
注意事项
在开始之前,我要先说几点注意事项,这些注意事项也是其他人经常问我的,比如说我的电脑配置够不够,我用的是苹果电脑能不能运行之类的,那现在我一一给大家解答一下。
系统支持与硬件要求
- ollama支持Windows、Mac OS和Linux三个系统,所以这三个系统都是可以运行的。
- 如果没有独立显卡,也可以运行,但是会非常慢。推荐的配置是电脑的内存大于8GB,显卡的显存大。如果你的电脑刚刚满足这两个配置,那么恭喜你,已经可以在本地运行最小参数量的模型。
- 对于AMD显卡的支持情况现在还不是特别确定。
如何部署大模型
如果电脑配置真的很低,但还是想部署一个大模型怎么办?你可以尝试一下通义千问开源的0.5B参数的模型,它只有300多兆,运行起来也就是推理起来,并不会占用特别多的资源,所以大家可以去尝试一下。
开始操作
OK,这次咱们真的开始操作了。
下载ollama
首先打开我们的浏览器, 在地址栏输入ollama.com ,然后点回车。点击这个下载按钮,然后选择自己电脑的操作系统,然后点击下载。
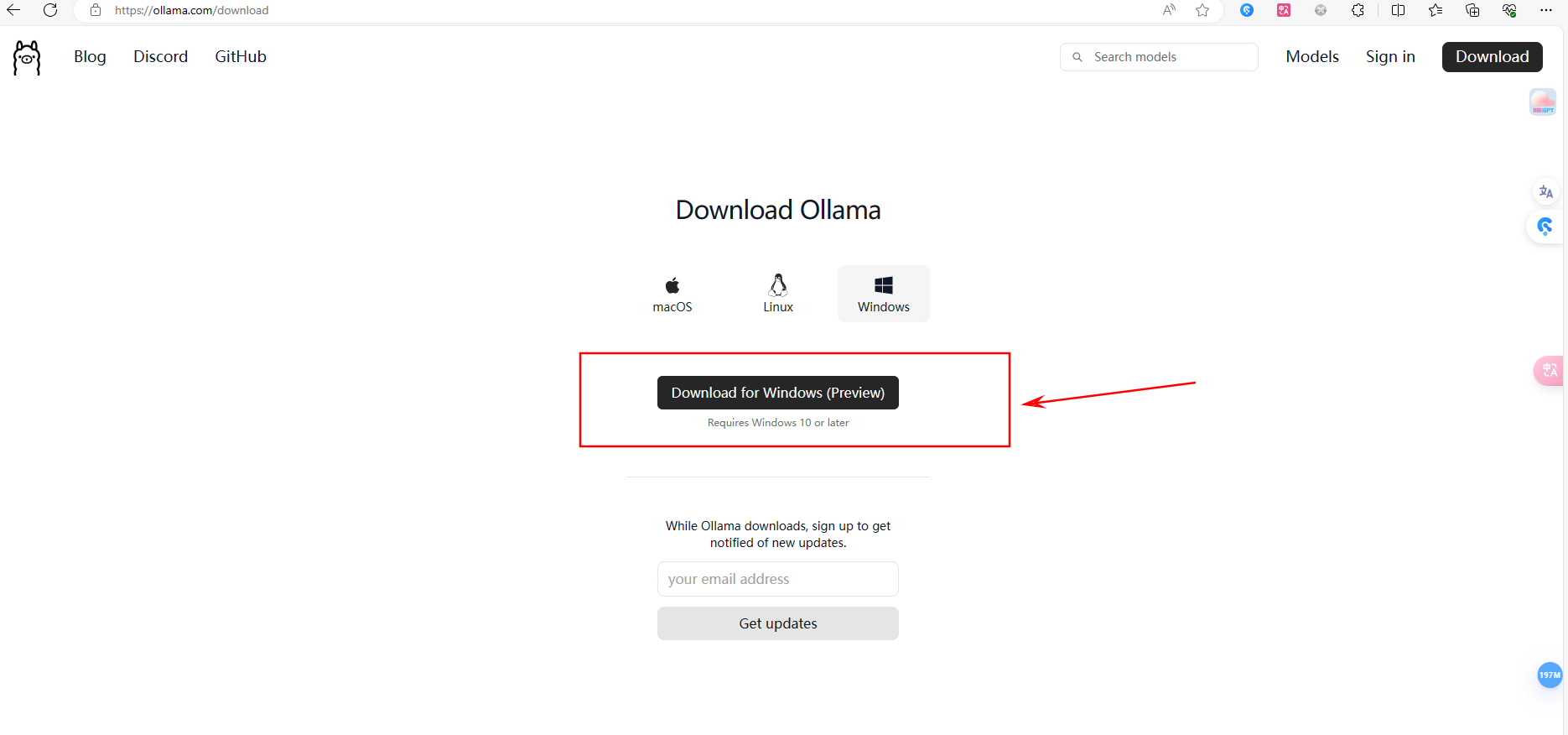
下载完成之后,我们找到我们刚刚下载的这个文件,然后双击运行,然后点安装,等待它安装完成。
设置环境变量
安装完ollama之后,我们需要进行一步操作,就是给ollama的模型文件找一个地方,它默认是存到C盘的,但是我相信大部分人的C盘都已经快存满了。OK,点击开始,然后找到设置,在设置的搜索栏里,我们搜索环境变量,然后找到这个编辑系统环境变量
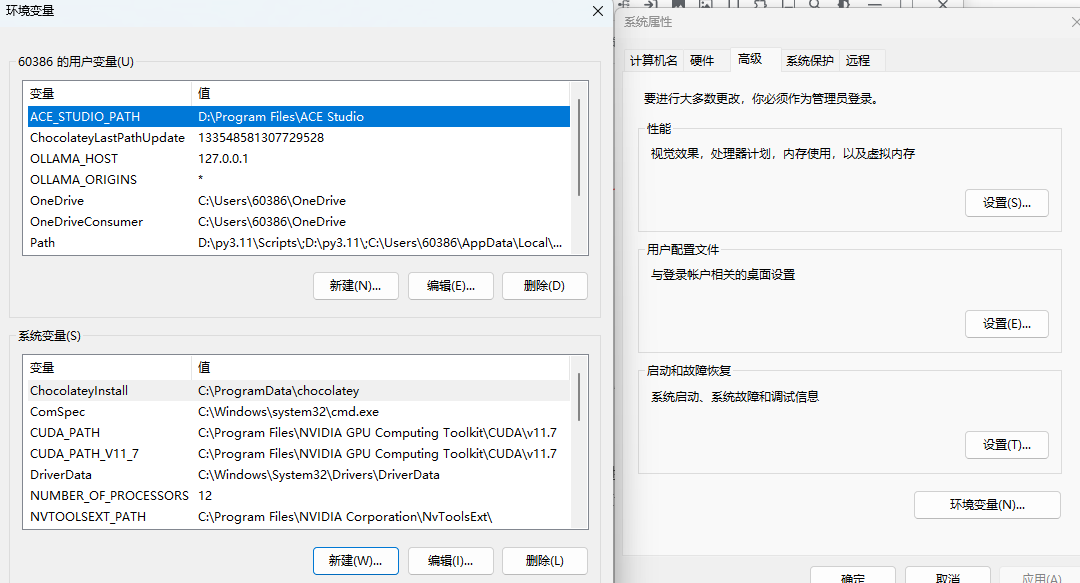
打开之后,会弹出这样一个窗口。然后这里有一个环境变量点进去,在系统变量这里我们点击新建,然后变量名称这里我们输入大写的全部大写哦 OLLAMA_MODELS,变量值就是你想要把模型存放的路径了。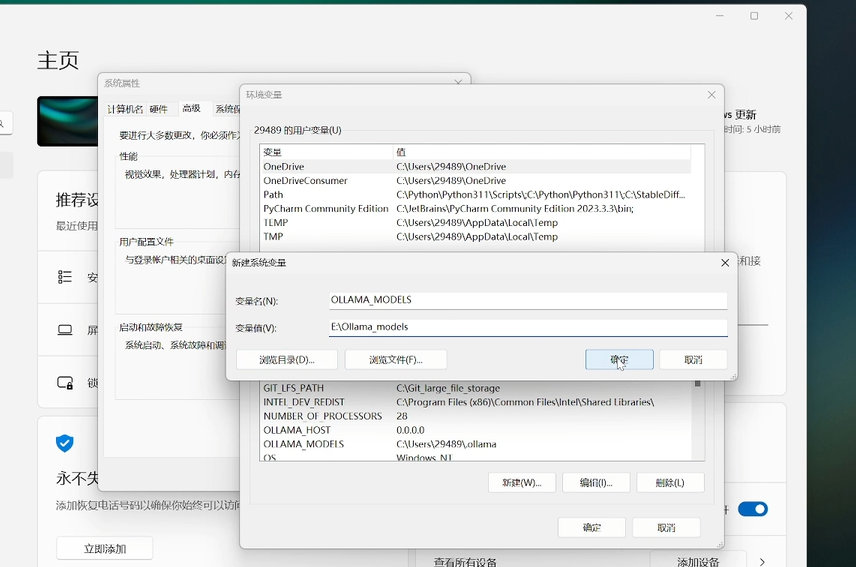
下载模型
因为之前已经设置过了,所以我这里就不点确定了。之后再点击这里的确定,然后再点这里的确定就OK了。我们回到ollama的官网,然后在官网的右上角点击models,
然后可以查看欧拉马都支持哪些模型,比如刚刚发布的llama3,还有谷歌的GEMAN,还有之前的蓝猫二,前面还有同1000万的千万模型,还有等等等等其他的一些。我们这里呢只用那个拉玛三来进行演示,点进去。
选择模型版本
这里我们只需要关注这两个地方就可以了。第一个是我们可以选择模型不同参数量的版本,比如70亿参数的版本和8亿参数的版本。也可以看到对应版本所需要的硬盘容量,70亿参数的需要40GB,8B模型的8亿参数的模型只需要4.7GB。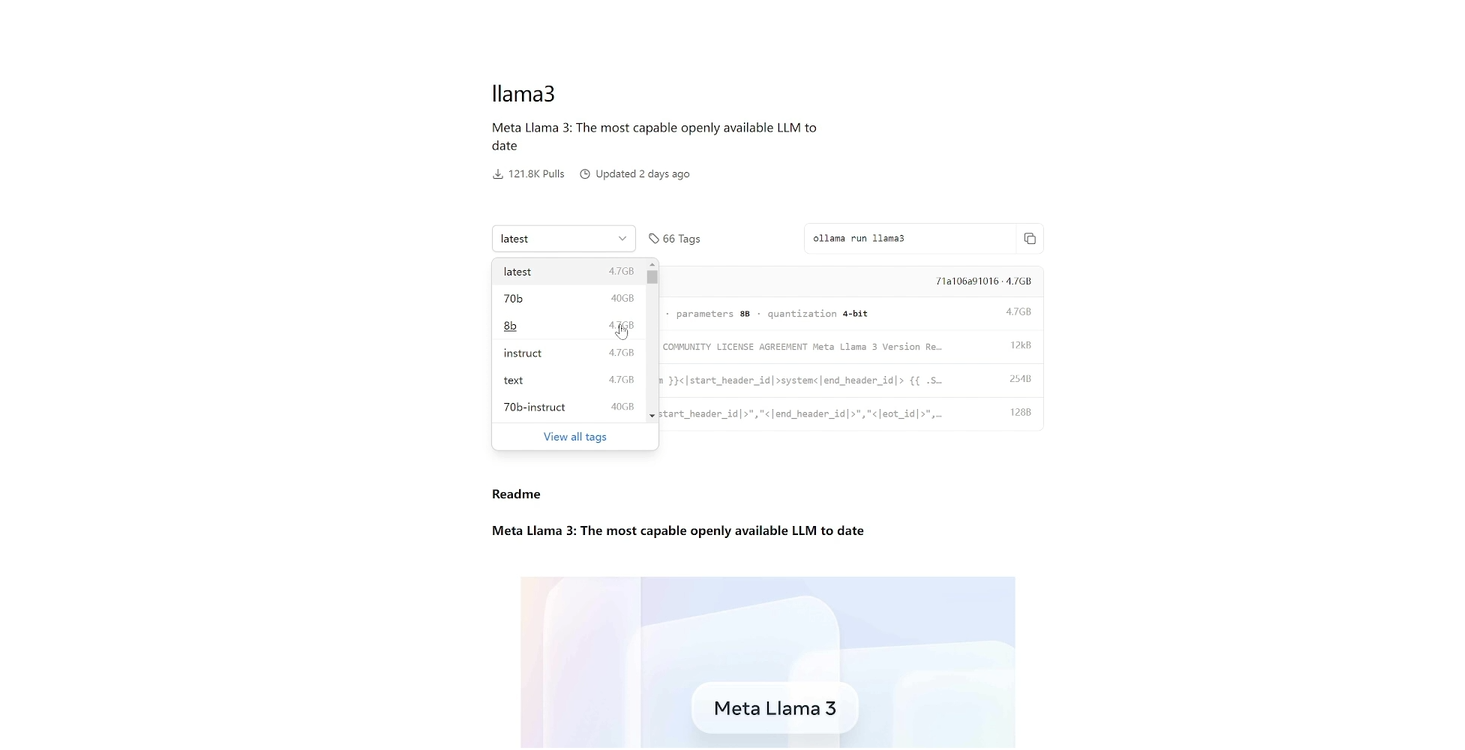
运行命令
然后后面这个是我们在本地运行某个模型时需要的命令。因为我们下载的是拉玛三,所以你会看到后面这个词是llama3,
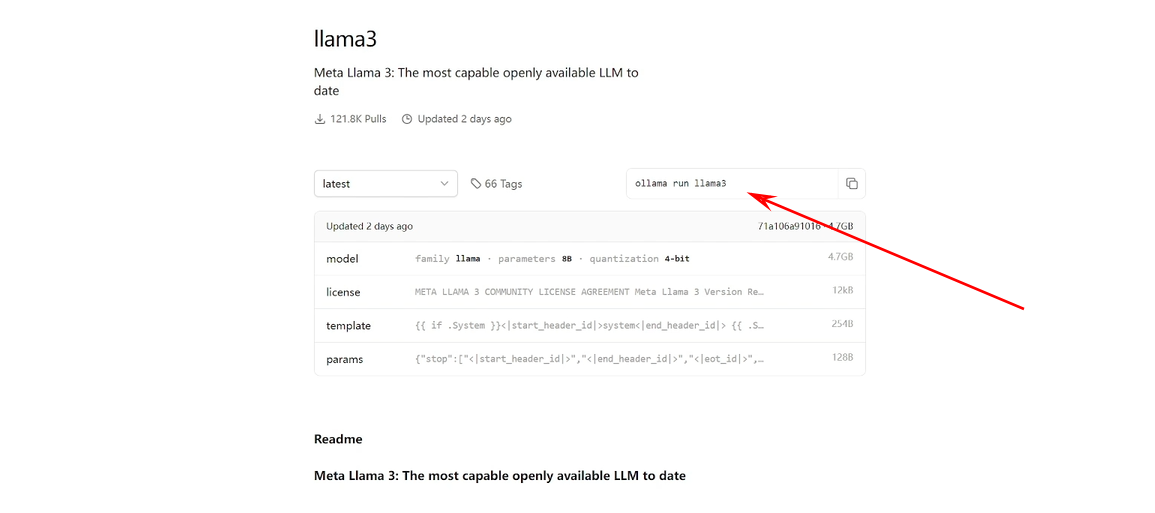
但如果我选择的是70亿参数的这个模型,你会看到他后面就会写拉玛三冒号70B,就会指定我运行的是拉玛三的70亿参数的版本。我们打开终端,然后把我们刚刚复制的这一段命令粘贴进去,然后按一下回车,可以看到它就已经开始在运行了。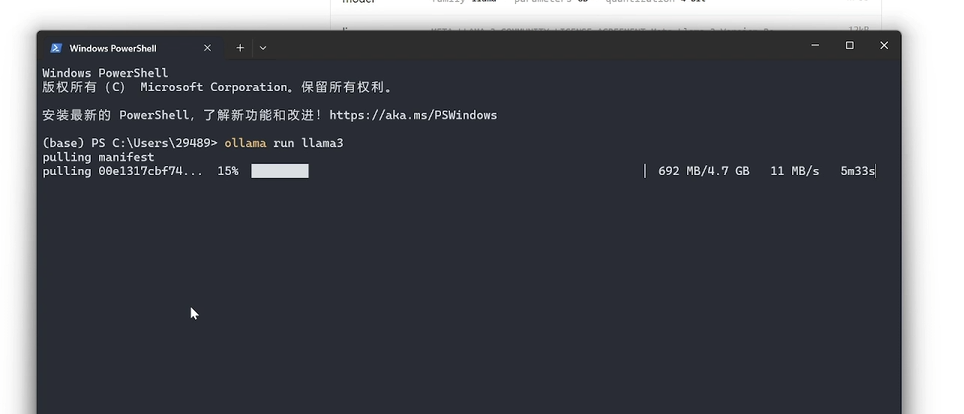
模型运行和测试
当你输入这个命令按下回车开始运行的时候,欧拉马会首先检测你有没有下载这个模型,如果没有下载,它会开始下载。如果你下载了这个模型,它就会直接运行这个模型。因为咱们刚刚安装完还没有下载模型,所以他会先进行下载,把这个模型下载完之后我们就可以在终端中使用这个模型了。
模型下载完成
OK,你看下载完成了之后,然后他就开始运行这个大模型,出现这个的时候,
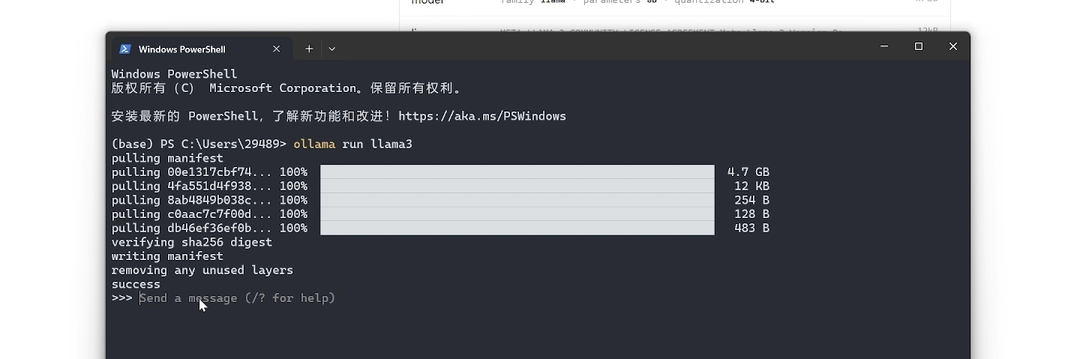 就证明这个大模型已经在本地运行起来了。然后现在问他一个问题,
就证明这个大模型已经在本地运行起来了。然后现在问他一个问题,
可以看到速度非常快,然后他会说他叫llama是什么什么什么,我英语不太好也看不懂。然后我们可以用中文来测试一下。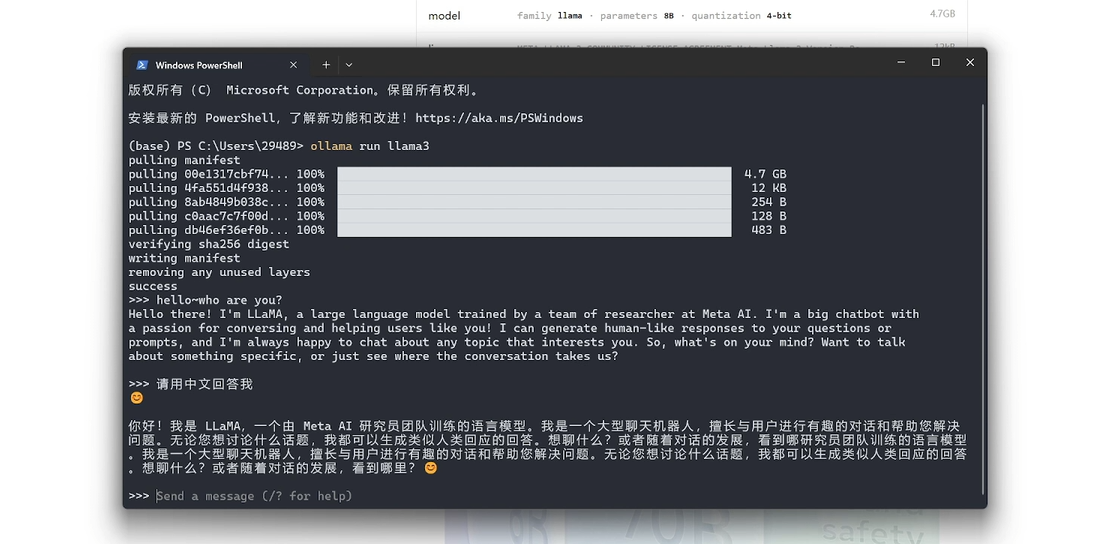
部署前端页面
OK现在咱们已经通过ollama把大模型下载到咱们电脑的本地,然后在本地运行起来了。但是这样用起来肯定是非常的不爽,这个时候我们还需要一套前端的页面,让我们可以在一个页面里去和大模型进行对话。而且这个前端它还可以支持其他的功能,比如说向量检索,向量检索也就是把你的一个文档传给大模型,然后你可以针对这个文档去问大模型一些问题,然后大模型就会阅读这个文档然后去回答你的问题。
操作指南
OK不多说,咱们直接开始操作。在ollama的官网的左上角可以点击这个GITHUB,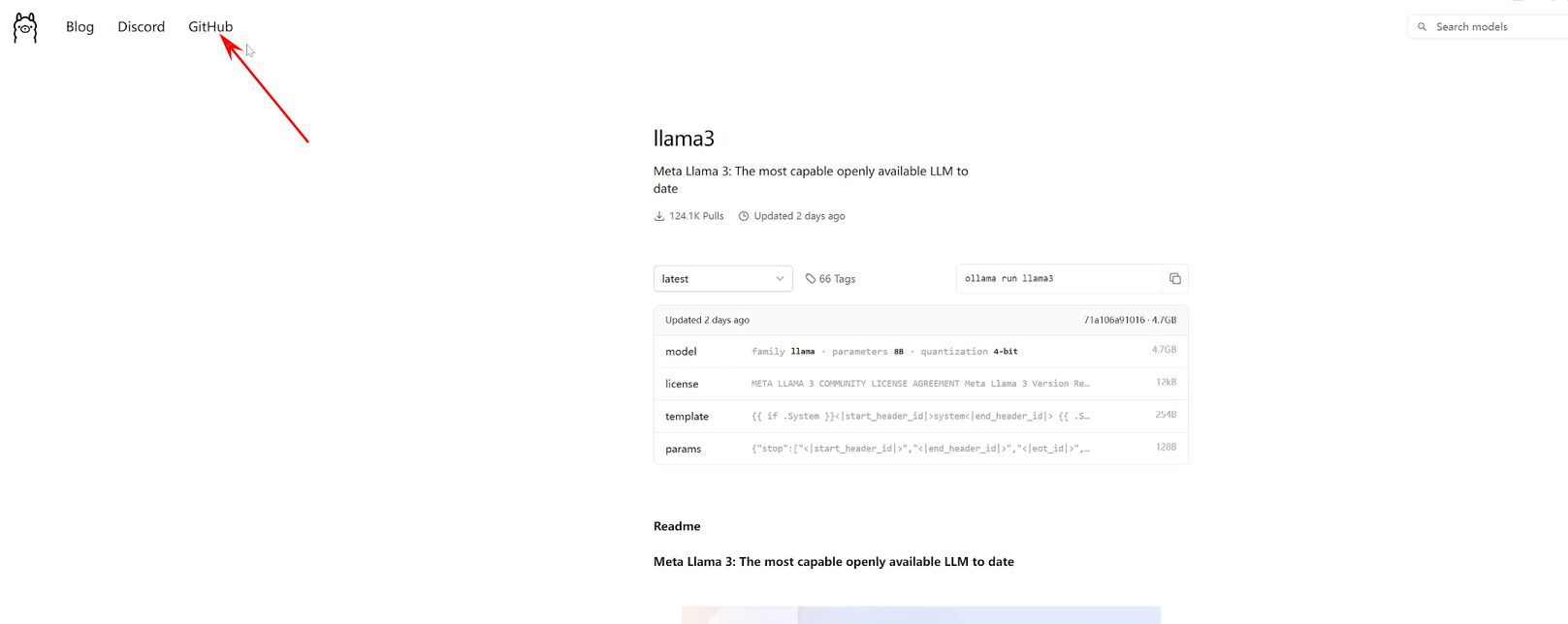 然后到GITHUB的ollama的首页,然后往下翻,可以看到有这么多项目都支持奥拉马。我们这一次呢只用这个 open web ui 这个项目来给大家做演示
然后到GITHUB的ollama的首页,然后往下翻,可以看到有这么多项目都支持奥拉马。我们这一次呢只用这个 open web ui 这个项目来给大家做演示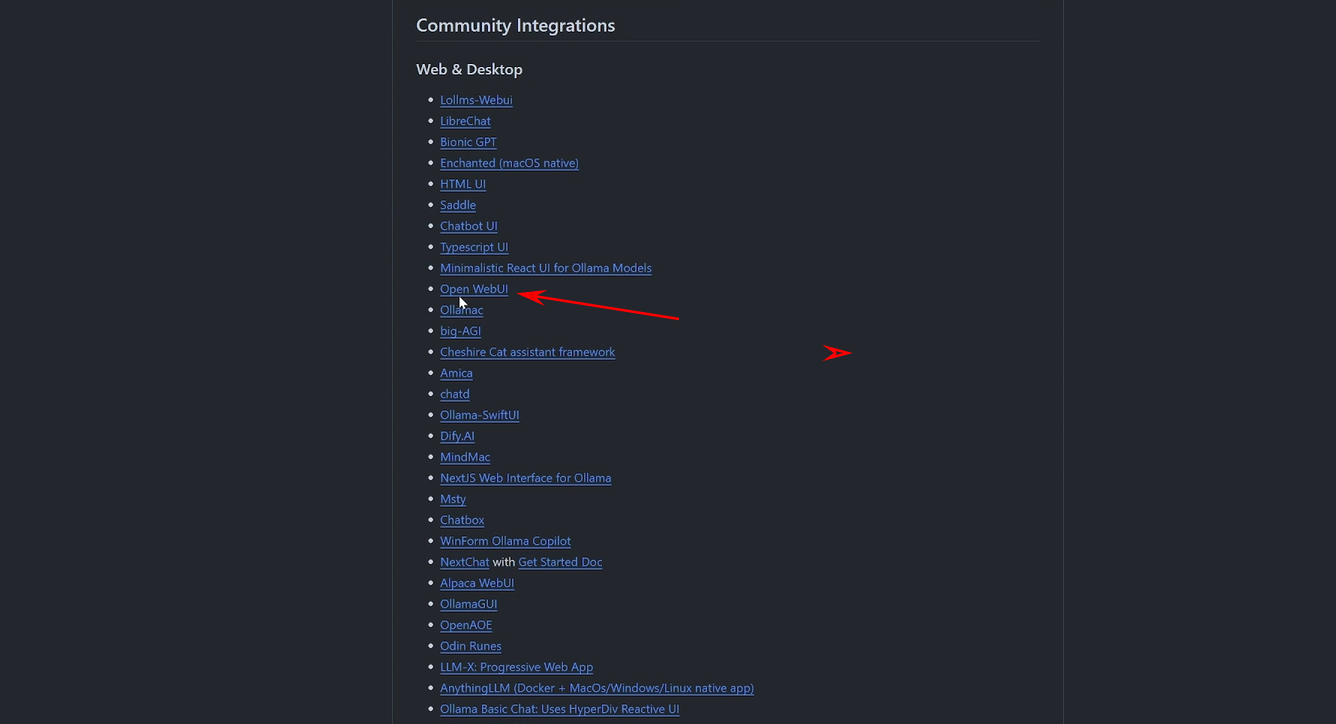 。
。
Open Web UI介绍
这个就是 open web ui 这个项目的GITHUB主页,在这里面我们只需要用到一行代码,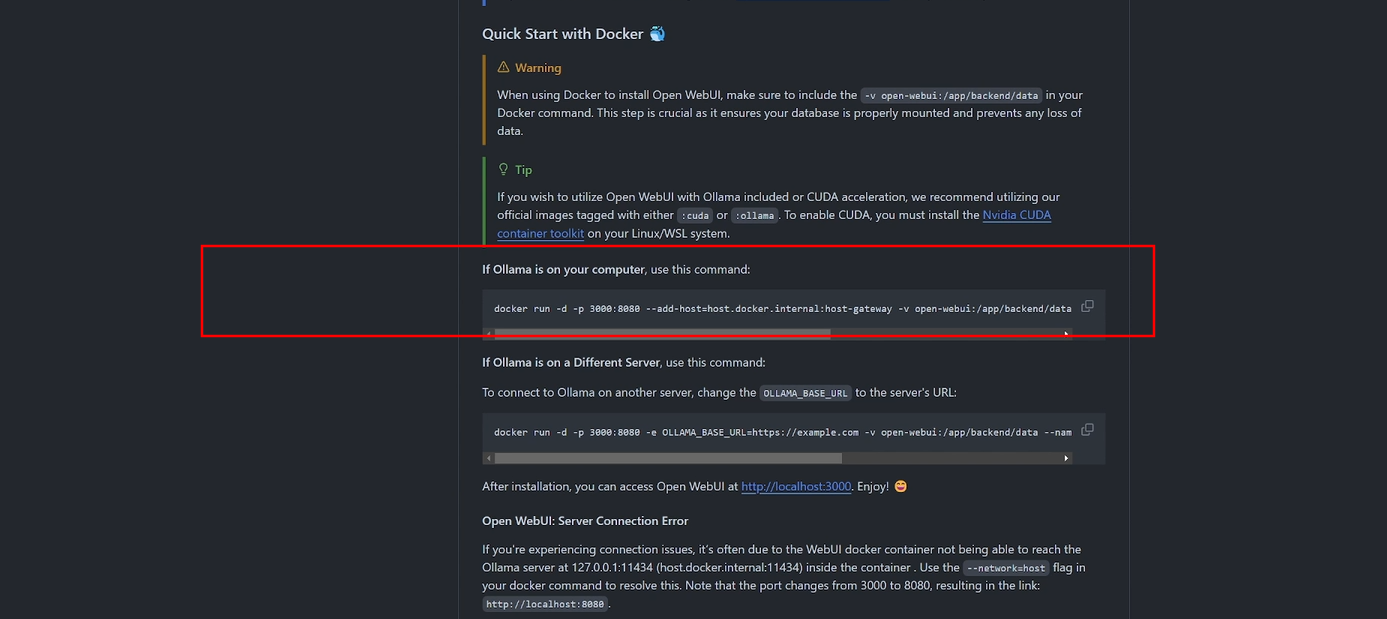 但是在使用这一行命令之前我们还需要下载一个 docker 。
但是在使用这一行命令之前我们还需要下载一个 docker 。
Docker安装
首先我们打开浏览器,在地址栏里输入DOCKER.COM,在docker的官网中点击下载,然后选择你要下载的版本,注意你的系统版本,然后点击进行下载。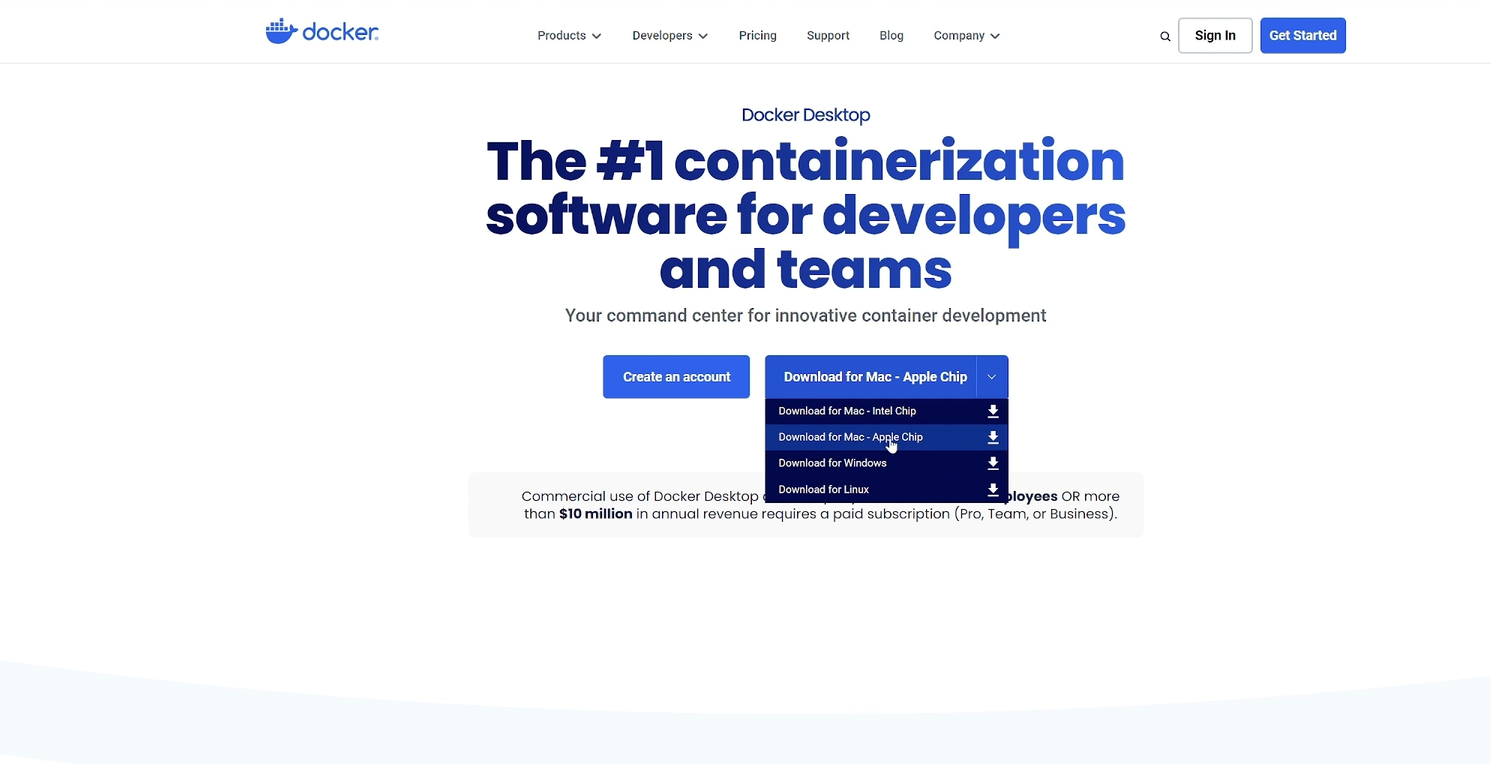 下载完成之后,我们打开下载目录,找到我们刚刚下载的docker,然后双击进行安装。
下载完成之后,我们打开下载目录,找到我们刚刚下载的docker,然后双击进行安装。
Docker运行
我们点击OK,然后它就会开始自动安装。安装完成之后,我们点击关闭,然后在桌面双击docker的图标,然后我们点击这个同意。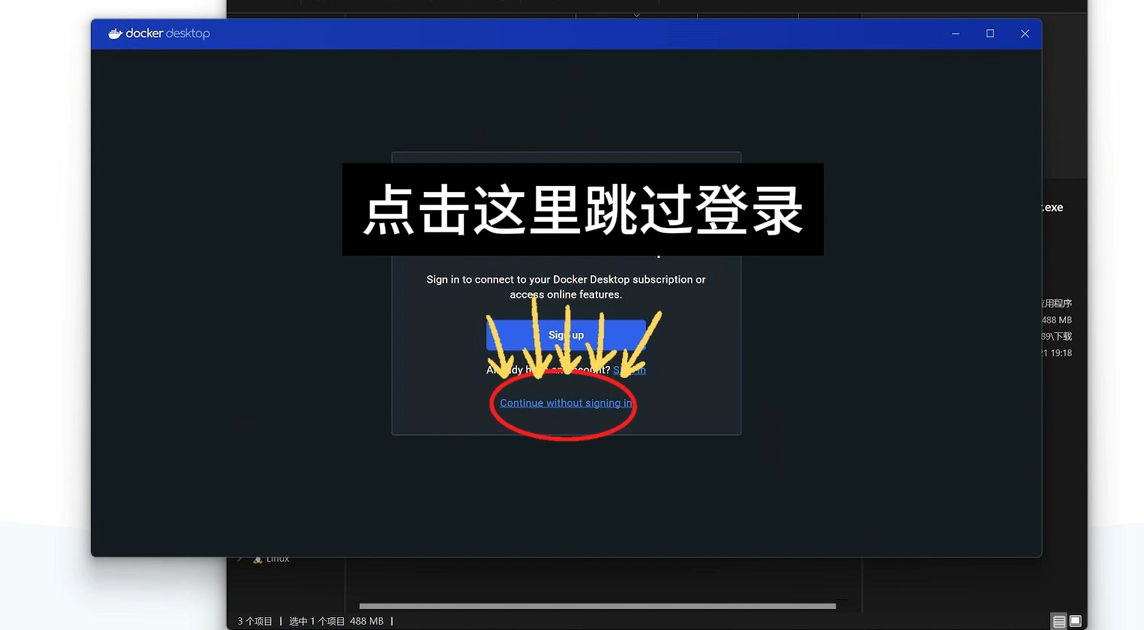 如果你是第一次安装和打开这个docker的话,先保证左下角这里他的状态是运行的。
如果你是第一次安装和打开这个docker的话,先保证左下角这里他的状态是运行的。
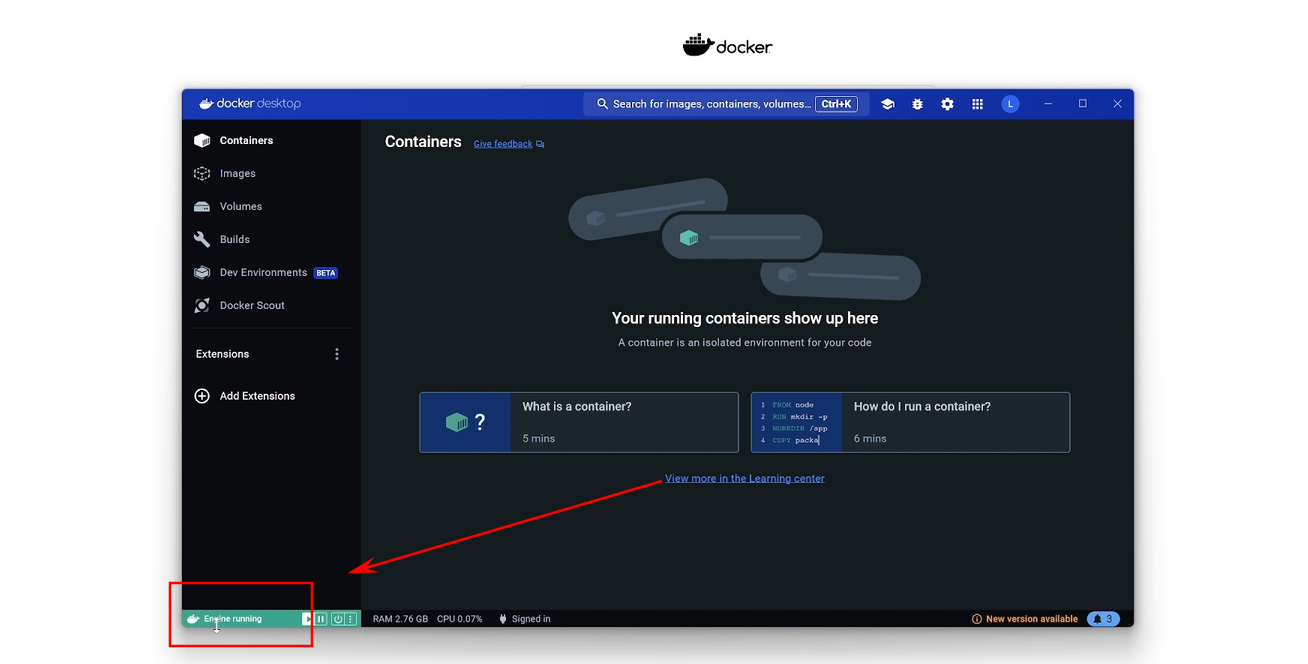 运行起来成功了之后,就会看到我现在这个样子。到这个时候我们就可以回到 open web ui 的这个主页,用这一行代码去运行。
运行起来成功了之后,就会看到我现在这个样子。到这个时候我们就可以回到 open web ui 的这个主页,用这一行代码去运行。
docker run -d -p 3000:8080 --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main
运行Open Web UI
然后我们点击一下后面这个复制的按钮,然后打开用win加R键,然后打开我们的终端,然后把刚刚复制这一行代码粘贴进去,然后按一下回车,然后等待它运行就好了。你看到它会自己在运行,然后它会自动的去下载一些东西。
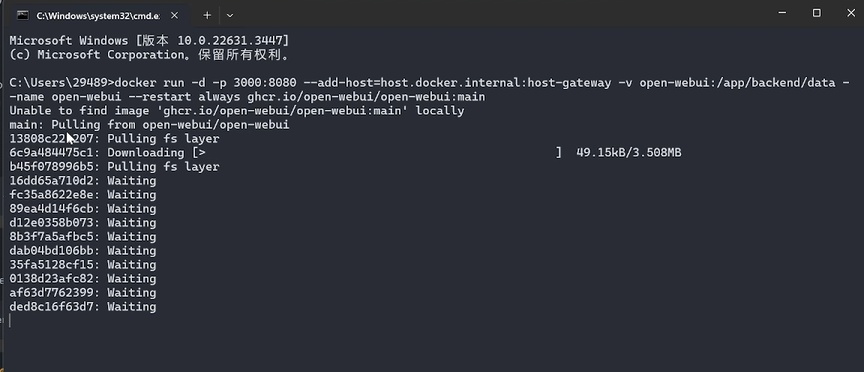
部署完成
好OK运行完了之后,我们再回到docker,在第一个里面就有了 open web ui 这个项目。然后这个时候我们可以点击后面这个3000冒号8080,打开之后我们就可以看到 open web ui 这个项目就已经可以在前端运行了。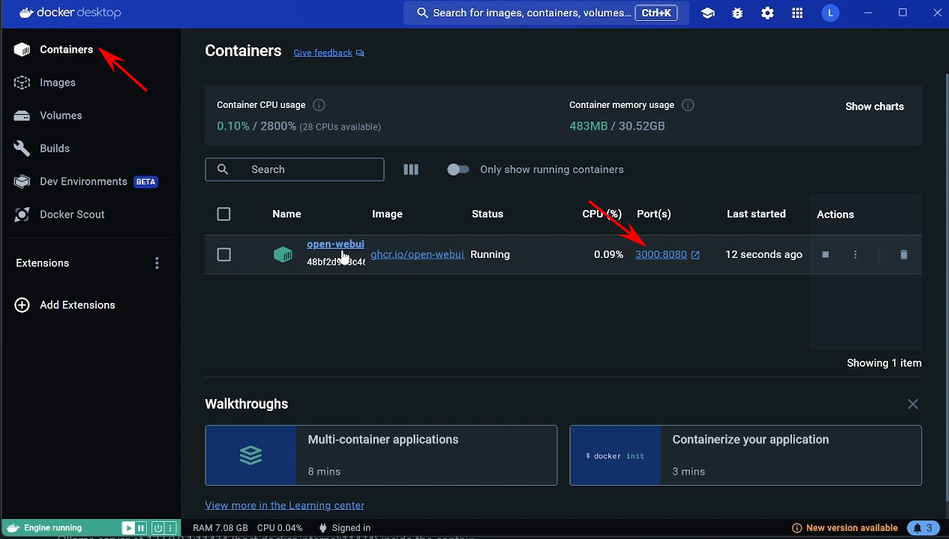 这个时候我们注册一个账户,第一个注册的就会当做管理员用户,然后我们直接登录就可以了。
这个时候我们注册一个账户,第一个注册的就会当做管理员用户,然后我们直接登录就可以了。
使用大模型
OK这个时候我们就可以先选择一个模型,我们刚刚下载的llama3,选择模型之后,我们这个时候就可以进行对话了。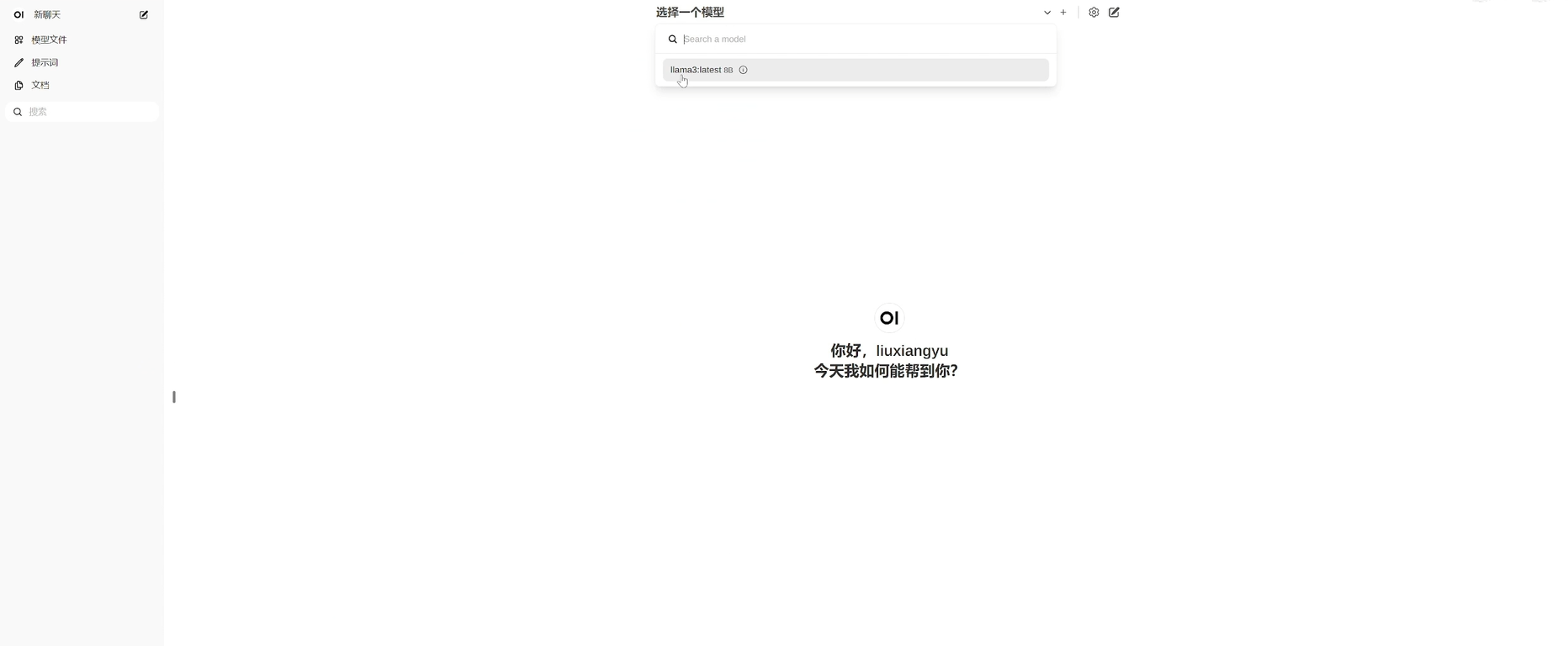
部署前端页面完成
OK咱们现在已经把前端页面已经部署完了,我们就可以像使用chat gt一样,然后来使用我们部署在本地的大模型了。
部署大模型的优点
为什么非要把大模型部署到本地呢?有这样几个优点:
- 完全免费
- 运行速度非常快
- 你和大模型对话产生的所有的数据和聊天记录都会被保存到本地,这样的话对有保密要求的数据就非常友好。
感悟:
这段口述内容其实是一个非常详细的教程,讲述了如何在本地部署和使用大型机器学习模型。整个过程包括了从下载、安装、配置环境变量、下载模型、运行测试到最后的前端页面部署,每一步都详细到了几乎每一次点击和输入。这种教程对于初学者来说非常友好,因为它几乎覆盖了所有可能会遇到的问题,并且提供了解决方案。
自己的想法是,这样的教程非常适合那些想要自学但又担心遇到问题而无从下手的人。通过这样的视频,可以降低学习门槛,鼓励更多的人去尝试和学习新技术。同时,这也体现了开源社区的力量,让知识和技术的传播变得更加容易和快捷。
© 版权声明
文章版权归作者所有,未经允许请勿转载。




