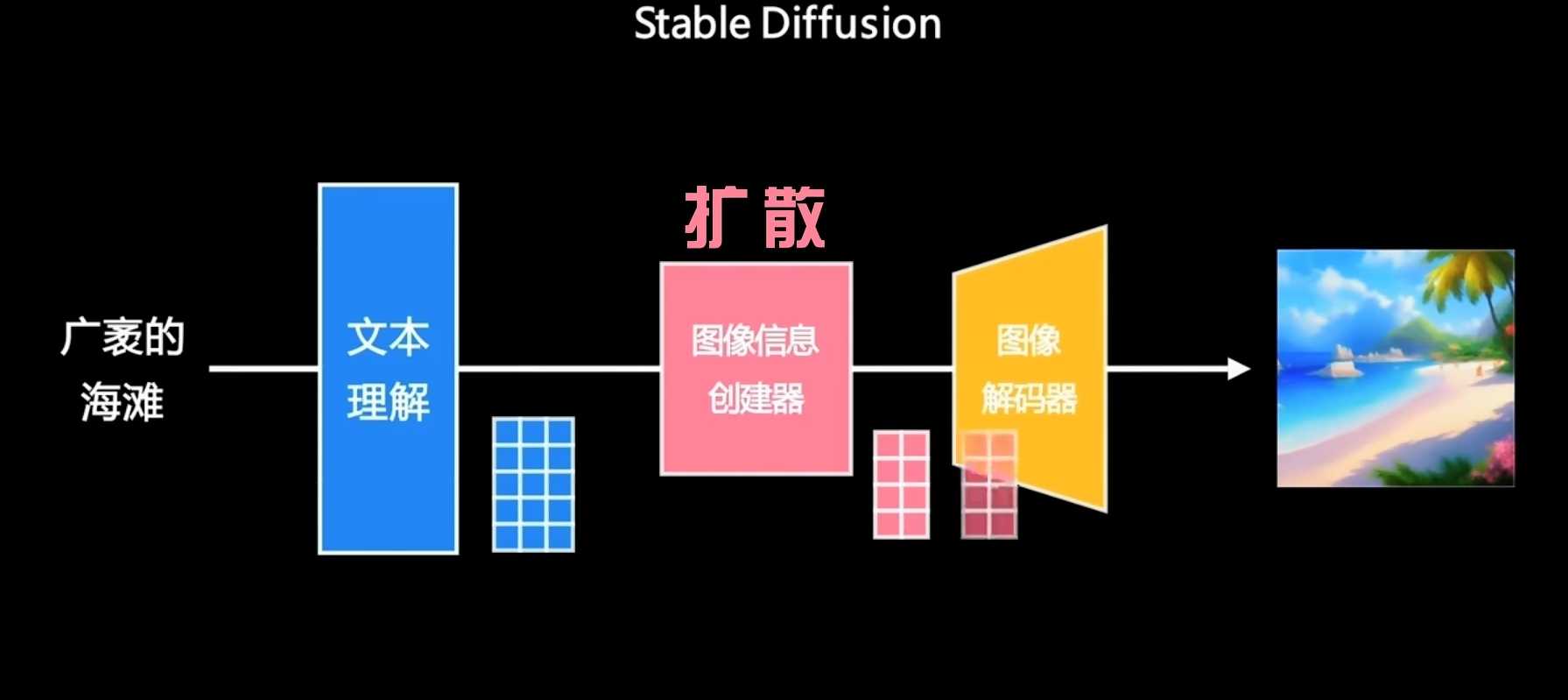
前言
什么是卷积核,Pytorch与过拟合?分不清机器学习和深度学习?
这里整理了所有你可能用到的知识
机器学习和深度学习是人工智能的两个重要分支。机器学习是一种计算机算法,它通过给定的数据来推断出模型的参数,并用这些参数来预测新的数据。深度学习是一种机器学习方法,它通过使用神经网络来学习特征表示,以及如何用这些特征来做出预测。两者的主要区别在于所用的模型。机器学习通常使用各种不同的模型,如决策树、随机森林和支持向量机等。深度学习则主要使用神经网络模型。
深度学习的优点是它可以自动提取数据中的特征,因此不需要人工选择特征。但这也是深度学习的一个缺点,因为它不能保证所提取的特征是正确的。
机器学习则需要人工选择特征,但这样做可以保证所用的特征是正确的。
总之,机器学习和深度学习都是人工智能领域的重要分支,它们各有优缺点,可以相互补充。在实际应用中,选择哪种方法取决于数据特点和需求。
机器学习框架
机器学习框架(Machine Learning framework)是一个用于构建、训练和部署机器学习模型的软件工具包。
它包括常用的机器学习算法、模型训练和验证接口、数据读取和处理模块、模型保存和加载工具等功能,能够帮助开发人员更快速地完成机器学习项目。
常见的机器学习框架包括 TensorFlow、PyTorch、Keras 等。
TensorFlow是由谷歌开发的开源机器学习框架,支持多种语言和平台,提供强大的计算图功能,能够支持大规模机器学习和深度学习应用。
PyTorch是由 Facebook 开发的开源深度学习框架,采用动态图模型,能够提供快速的模型训练和高效的模型部署。
Keras是一个高度模块化的深度学习框架,支持快速搭建和训练深度学习模型,并提供丰富的工具和接口,适合初学者和专家入门和开发深度学习项目。
TensorFlow适合大规模机器学习和深度学习应用,PyTorch 适合快速模型训练和高效模型部署,Keras 适合初学者和专家入门和开发深度学习项目。
机器学习通常分为三类
监督学习是指使用带有标签的训练数据来学习模型的预测函数。监督学习可以用于分类和回归。
无监督学习是指使用没有标签的训练数据来学习模型的特征表示。无监督学习可以用于聚类和降维。
强化学习是指使用实际操作来学习模型的参数。强化学习可以用于游戏智能、自动驾驶等应用。
常见的机器学习算法
- 线性回归:线性回归算法是机器学习中最简单的算法之一,它用于预测数据中两个变量之间的线性关系。
- 逻辑回归:逻辑回归算法是一种分类算法,它用于预测数据中两个变量之间的二分类关系。
- 决策树:决策树算法是一种监督学习算法,它通过建立决策树模型,对数据进行分类和预测。
支持向量机:
K-均值: - 随机森林:随机森林算法是一种集成学习算法,它通过组合多棵决策树模型,实现分类和回归任务。
- 神经网络:神经网络算法是一种深度学习算法,它通过模拟人类神经系统的结构和功能,实现分类和回归任务。
这些算法都有不同的特点和应用场景,根据实际需求确定使用范围
感知器:感知器是一种简单的神经网络模型,它由输入层、隐藏层和输出层组成。它通过计算输入特征与权重的线性组合来做出预测。
常见的深度学习算法
- 卷积神经网络(CNN):卷积神经网络是一种专门用于图像处理的神经网络模型。它通过使用卷积层来提取图像的特征,并使用池化层来降低数据的维度。CNN 可以用于识别图像中的对象、分类图像等应用。
- 循环神经网络(RNN):循环神经网络是一种专门用于处理序列数据的神经网络模型。它可以在序列中保留历史信息,并用这些信息来做出预测。RNN 可以用于处理自然语言、预测时间序列等应用。
强化学习:强化学习是一种通过实际操作来学习的机器学习算法。它通过不断尝试和学习来改善模型的表现,并通过奖励机制来调整模型的参数。强化学习可以用于游戏智能、自动驾驶等应用。
推理
推理(Inference)指的是在训练完成后,通过机器学习模型对新的数据进行预测、分类或回归,从而得到有用的信息和结果的过程。
推理是机器学习的核心部分,它能够实现机器学习模型对新数据的自动预测和处理。
模型
模型(Model)指的是用于预测、分类或回归数据的数学函数或计算模型。
通过对数据进行训练,可以得到一个模型,该模型能够对新的数据进行预测,并输出有用的结果。
模型的类型可以是线性模型、决策树、支持向量机、神经网络等,根据实际应用需求,可以选择不同的模型进行训练。
模型参数主要有权重和偏置
权重(Weight)是模型中的一种参数,它代表了各个特征对模型输出的影响程度。权重通常是模型训练中需要更新和调整的参数,能够通过训练数据来学习和更新。
偏置(Bias)是模型中的另一种参数,它代表了模型的偏向性。偏置项通常是固定不变的参数,能够对模型的输出产生额外的平移或缩放效果。
权重和偏置项是模型中重要的参数,它们能够影响模型的表现和性能。通过训练数据,权重和偏置项能够被自动学习和更新,从而使模型对新数据具有更好的泛化能力。
模型权重(Model weight)
模型权重是模型参数的一种,指的是模型中各个参数的值。
模型权重包括权重矩阵和偏置向量等参数,它们是在模型训练过程中由优化器根据损失函数自动调整的,能够决定模型在新数据上的预测结果。通过调整模型权重,可以提高模型的性能和泛化能力。
模型偏置(Model bias)
模型偏执指的是模型在预测结果时存在的偏差。偏差可能来源于模型本身的结构或假设,也可能来源于训练数据的不平衡或噪声。
模型偏差会导致模型预测结果不准确或不稳定,因此在模型训练过程中,需要对模型偏差进行监控和修正,以保证模型的准确性和泛化能力。
噪声(Noise)
噪声指的是数据中的随机误差或干扰,它会影响模型的训练和预测精度。
噪声可能来源于采集数据的方法、传输数据的途径、存储数据的环境等,也可能来源于数据中的异常值或冗余信息。
噪声会使模型过度拟合或欠拟合,影响模型的泛化能力,因此在模型训练中需要对数据进行清洗和预处理,去除噪声的影响。
模型融合(Model fusion)
模型融合是一种将多个机器学习模型的预测结果进行结合的方法,以得到更准确的预测结果。
模型融合通常采用多个不同的模型进行预测,并通过投票或加权平均等方式对模型预测结果进行结合,从而提高模型的准确性和稳定性。模型融合的常见方法包括加权平均、投票、贝叶斯平均等。
embedding
embedding指的是将高维离散特征转换为低维连续特征的过程,它能够帮助模型更好地处理离散数据,并减少维度灾难的影响。
通常情况下,机器学习模型处理的特征都是连续的,例如人的身高、体重等特征,它们可以直接通过浮点数表示。
但有些特征是离散的,例如人的性别、国家等特征,它们需要使用离散编码来表示。
这些离散特征通常会对模型的训练和预测产生不利影响,包括增加模型复杂度、增加模型参数、导致维度灾难等问题。
通过 embedding 技术,可以将离散特征转换为低维连续特征,从而减少模型的复杂度,降低模型参数,避免维度灾难等问题。
例如,将人的性别用 0、1 表示,然后将它们转换为 2 维的向量,通过模型训练可以学习到性别的特征,并能够准确预测性别。
这样,模型就可以更好地处理离散特征,提高模型的泛化能力。
embedding模型
embedding 模型(Embedding model)是一种将离散的输入特征映射到连续空间的模型。
它通过建立输入特征与连续向量之间的映射关系,将离散的特征转换成连续的特征表示,使得同类型的特征在连续空间中更接近,更易于模型训练和处理。
常见的 embedding 模型包括词嵌入(Word Embedding)和图嵌入(Graph embedding)等
hypernetwork
hypernetwork(超网络)是指一种深度学习模型,它由两个不同的神经网络构成:主网络和超网络。
主网络用于处理输入数据,并输出主网络的输出结果;超网络用于生成主网络的权重参数,并将权重参数应用于主网络中。
超网络能够通过学习主网络的权重参数,使主网络具有更好的性能和泛化能力。
数据集
模型训练中的数据集包括训练集、验证集和测试集。
它们都有不同的用处:
训练集:训练集是模型训练的主要数据来源,通过对训练集进行训练,可以调整模型的参数,使模型能够对训练集的样本进行分类或回归。
验证集:验证集用于在训练过程中评估模型的性能,通过对验证集进行预测,可以得到模型在新数据上的表现情况,并根据验证结果调整模型的参数,使模型更加适应新数据。
测试集:测试集用于最终评估模型的性能,通过对测试集进行预测,可以得到模型在未知数据上的泛化能力,并确定模型的最终性能。
训练集用于模型训练,验证集用于模型验证,测试集用于模型评估。
通过不同数据集的应用,可以保证模型训练的准确性和泛化能力。
泛化能力
泛化能力是指模型在训练过程中学习到的知识能够应用于新的、未经过训练的数据,并能够在这些数据上取得较好的预测结果。
具有良好的泛化能力意味着模型不会欠拟合或过拟合,能够在实际应用中取得较高的准确率
拟合度
拟合度(Fitness)指的是模型在训练数据集上的性能表现。
拟合度越高,表示模型能够较好地拟合训练数据,具有较强的泛化能力。
拟合度过低则表示模型对训练数据的拟合能力不足,对新数据的预测能力也可能不足。
过拟合
模型训练中的过拟合指的是在训练模型时,模型在训练数据上的表现过于优异,而在未知数据上的表现不佳的情况。这种情况通常发生在模型的复杂度过高,或者训练数据不够充分时。
为了解决过拟合问题,可以采取多种方法。首先,可以增加训练数据的数量,这样可以使模型在充分学习了真实数据的情况下,更加准确地预测未知数据
避免过拟合
使用正则化来限制模型的复杂度,避免学习到噪声数据。
增加训练数据的数量,减少模型在训练数据上的训练次数。
使用数据增强技术,增加模型对未知数据的泛化能力。
使用验证集进行模型评估,选择在验证集上表现较好的模型。
使用早停法,在模型在验证集上表现持续下降时停止训练。
欠拟合
欠拟合指的是模型无法很好地拟合数据,导致预测的精度不够高。
这种情况下,模型无法很好地捕捉到数据中的特征和规律,导致预测的准确度不够高。
避免欠拟合
选择适当的模型,比如增加模型的复杂度,比如增加网络层数或增加网络参数。
增加训练数据,提高模型的泛化能力。
对训练数据进行预处理,比如归一化或标准化,减少数据中噪声的影响。
使用正则化或 dropout 技术防止过拟合。
调整学习率或优化算法,提高模型的收敛速度。
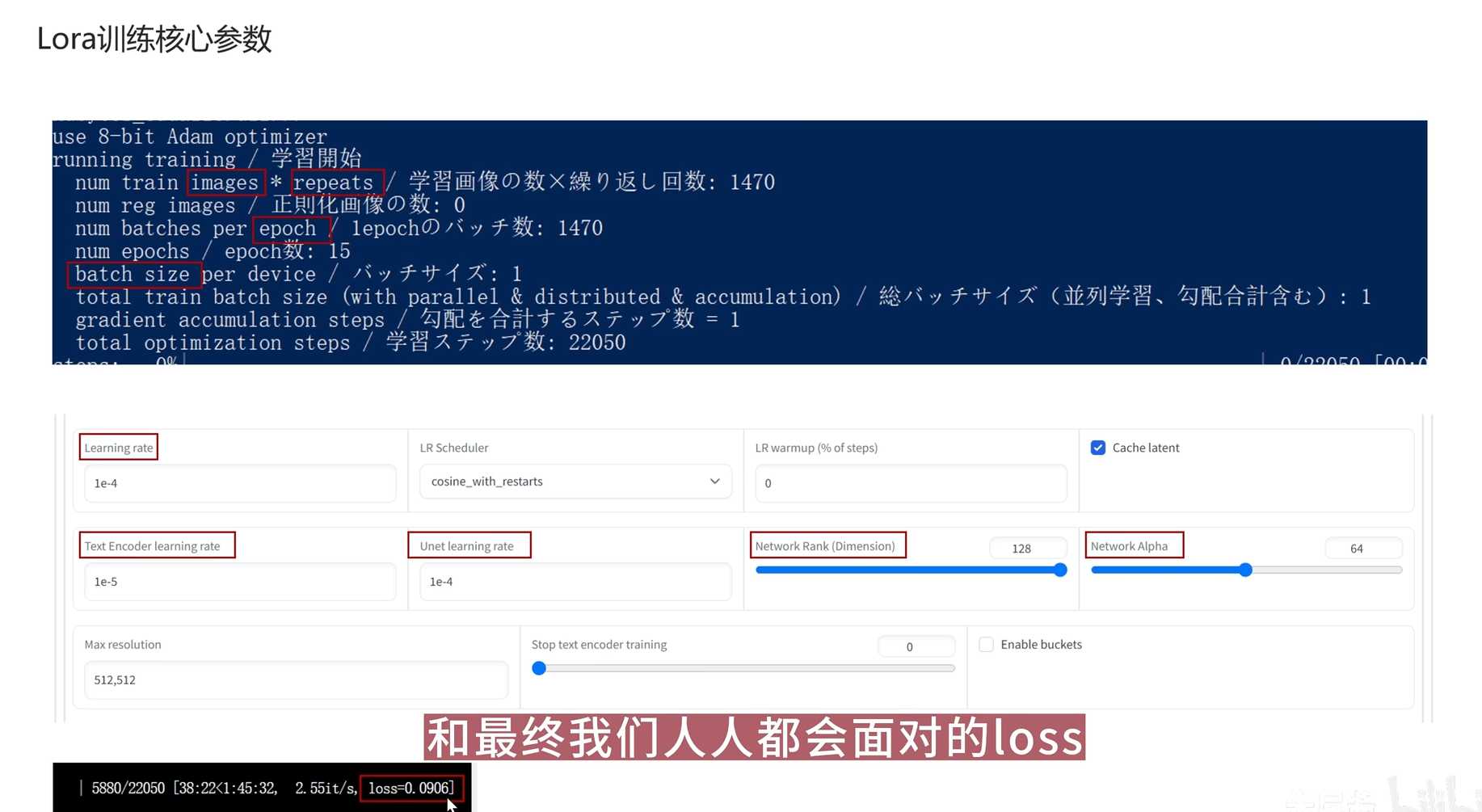
批尺寸
批尺寸是模型训练中用于一次训练的数据量。
批尺寸较小时,模型更新频繁,可以更快速地收敛,但是每次更新可能不够有效;批尺寸较大时,
模型更新次数减少,收敛慢,但是每次更新的影响更大。批尺寸的大小需要根据具体情况进行调整。
epoch
在模型训练中,epoch是指对训练数据集进行一轮完整的遍历和更新参数的过程。
模型训练时,通常需要进行多轮训练,每轮训练都叫做一个epoch。
每个epoch中,模型会根据训练数据和当前的模型参数进行参数更新,以提高模型的泛化能力。
模型训练中的训练集是用于训练模型的数据集。
它包含了用于训练模型的输入数据和对应的正确输出结果,用于帮助模型学习并预测未知数据的输出结果。
训练集的选取对模型的性能有很大的影响,通常需要经过多次实验和调整才能获得较为理想的模型。
loss损失率
模型训练中的损失率是指模型预测结果与真实结果之间的差异度量。
通常情况下,损失率越小,模型的准确率越高,说明模型对于训练数据的拟合越好。
损失率通常用于评估模型训练过程中的收敛情况,并通过不断优化损失率来提升模型的预测能力。
损失函数
损失函数是一个度量模型预测值与真实值之间差距的函数。在机器学习和深度学习中,通常会使用损失函数来衡量模型的预测精度,并通过不断调整模型中的参数来使损失函数最小化。
常见的损失函数有平均绝对误差、平均平方误差、指数损失函数和对数损失函数等。具体取决于模型的类型和目标任务。例如,在二分类问题中,通常会使用对数损失函数;在回归问题中,通常会使用平均平方误差作为损失函数。
优化器
优化器是一种工具,用于最小化或最大化模型的损失函数。
常见的优化器包括随机梯度下降(SGD)、小批量随机梯度下降(Mini-batch SGD)、动量法(Momentum)、AdaGrad、RMSProp、Adam等。
优化器的特点取决于具体算法,不同的优化器可能具有不同的优化速度、收敛性能、对噪声的适应能力等。
例如,SGD在收敛速度上可能较慢,但具有较高的收敛精度;而Adam优化器在收敛速度上可能较快,但可能对噪声数据不太稳定。
PS 我们的stable diffusion Webui的embedding训练使用的是AdamW算法
学习率
学习率是模型训练中用来控制模型参数更新步长的一个超参数。
它决定了模型在每次迭代中更新参数的幅度,即模型每次迭代对错误的调整程度。
通常情况下,学习率越大,模型的更新速度越快,但也容易错过最优解;相反,学习率越小,模型的更新速度越慢,但更容易收敛到最优解。
因此,选择合适的学习率是模型训练的关键。
学习率退火
是指在模型训练过程中,随着训练的进行,逐渐降低学习率的一种策略。
这样可以避免模型在训练初期受到过大的更新,使模型训练更加稳定。
通常在模型收敛后,学习率会被逐渐降低,以防止模型过拟合
常见的退火算法
线性退火:学习率逐渐降低,达到一定次数后终止训练。
指数衰减:学习率以指数速率衰减,达到最小学习率后终止训练。
阶段性衰减:学习率在不同训练阶段有不同的衰减速度,达到最小学习率后终止训练。
动态调整:根据模型的训练情况实时调整学习率,达到最小学习率后终止训练。
如何获得最优的学习率
使用默认值,通常可以经过多次试验确定一个合理的学习率。
通过网格搜索,选择多个不同的学习率,并进行模型训练,最后选择模型性能最好的学习率。
采用动态调整学习率的方法,即在训练过程中动态调整学习率,以便让模型在不同阶段有不同的学习速率。
使用贝叶斯优化算法,自动调整学习率,以获得最优的学习率。
参考其他研究工作,对学习率进行模拟退火等其他技巧,来确定最优的学习率。
梯度下降
梯度下降算法是一种机器学习算法,用于训练模型并使模型的预测结果尽可能接近真实值。
该算法通过不断计算模型的损失函数的梯度并更新模型的参数来使模型的预测结果逐渐接近真实值。
通常,梯度下降算法需要设定一个学习率来控制更新的步长,并可以使用不同的优化算法来提高模型的训练效率。
模型蒸馏(Model dstillation)
模型蒸馏是一种模型压缩技术,它通过使用一个强大的“教师”模型来训练一个较小的“学生”模型,从而让学生模型具有更好的性
使用教师模型对训练数据进行预测,得到教师模型的输出结果。
使用教师模型的输出结果作为标签,训练学生模型,让学生模型尽可能接近教师模型的输出结果。
通过模型蒸馏,可以在保持模型性能的同时减小模型的大小,提高模型的部署效率。
PS我们常用的SD1.5和SD2.0就是蒸馏过的 作者:Harekaze晴风
© 版权声明
文章版权归作者所有,未经允许请勿转载。