













🎨 AI绘画基本概念
AI绘画的逻辑类似于找一位画家,告诉他你想要的画像,然后他根据你的描述在脑海中找到相应的特征,最终绘制出符合你要求的画作。AI绘画的核心是基于算法训练的模型,用户通过输入文本信息,AI会在模型中寻找最匹配的图像特征,并渲染出最接近用户要求的图片。
🔧 AI绘画工具
目前市面上最主要的两家厂商是Stable Diffusion(SD)和Midjounrey(MJ)。SD是开源的,免费且功能丰富,可以在本地操作和定制插件,也可以在云端进行部署。而MJ则是基于Discord平台,操作简洁但价格昂贵,且数据无法本地化。选择工具时需要考虑使用需求和个人能力。
🖌️ AI模型训练
AI模型训练过程中,将大量的图片样本录入模型,并根据算法不断加工样本进行学习。同时,对图片进行标记和描述,将文本信息转化为数字与图像特征对应,并存储在模型中。生成图片时,输入文本提示词,AI会在模型中寻找最匹配的描述,并生成最接近要求的图片。
⚙️ 大模型与小模型
目前的AI模型主要分为大模型和小模型。大模型通常是DreamBoost,小模型则是lora。它们的训练逻辑相同,都是将图片信息和文本信息进行降维处理,最终存储为一组数字。在生成图片时,通过逆向操作,输入文本提示词,AI会根据模型中的数字找到最匹配的描述,并生成符合要求的图片。
什么是大模型
就是把图片信息(image)、对应的文本描述信息(tag),基于特定的算法,转化为数字存储在专门的文件里,这个专门的文件就是模型。
LORA模型训练,其实就是用一个或者一些,特定特征来替换底模中的对应元素,比如用一张特
定的人脸、特定的衣服或者特定的风格,这样就可以根据需要生成不同于底模的图片。
为什么选择Lora用于模型训练
LORA采用的方式是向原有的模型中插入新的数据处理层,这样就避免了去修改原有的模型参数,
从而避免将整个模型进行拷贝的情况,同时其也优化了插入层的参数量,最终实现了一种很轻量化
的模型调校方法。直接以矩阵相乘的形式存储,最终文件大小就会小很多了。一般lora都在144M,
而一般的DB大模型至少都是近2G起,节省了大量的存储空间;LORA训练时需要的显存也少了,显卡的显存达到6G即可开启训练,硬件门槛更加亲民:LORA可以非常方便的在wbui界面通过调用和不同权重,实现多种模型效果的叠加,相比DB大模型操作更加便捷,效果更加显著:
🔍 AI绘画的不确定性
由于算法的原因,AI绘画过程中会存在一定的信号丢失,即使使用原始的标记或描述也无法得到完全相同的图片。这导致AI绘画存在一定的不可控性和随机性,无法完全可控。因此,练丹的结果往往是玄学,需要根据个人经验和实践来调整和优化。
📚 AI模型选择
根据个人需求和能力,可以选择不同的AI绘画工具和模型。SD是免费且开源的,功能丰富但门槛较高;MJ操作简洁但价格昂贵且封闭。大家可以根据自己的情况选择适合的工具和模型进行练习和创作。
02|Lora模型训练核心参数
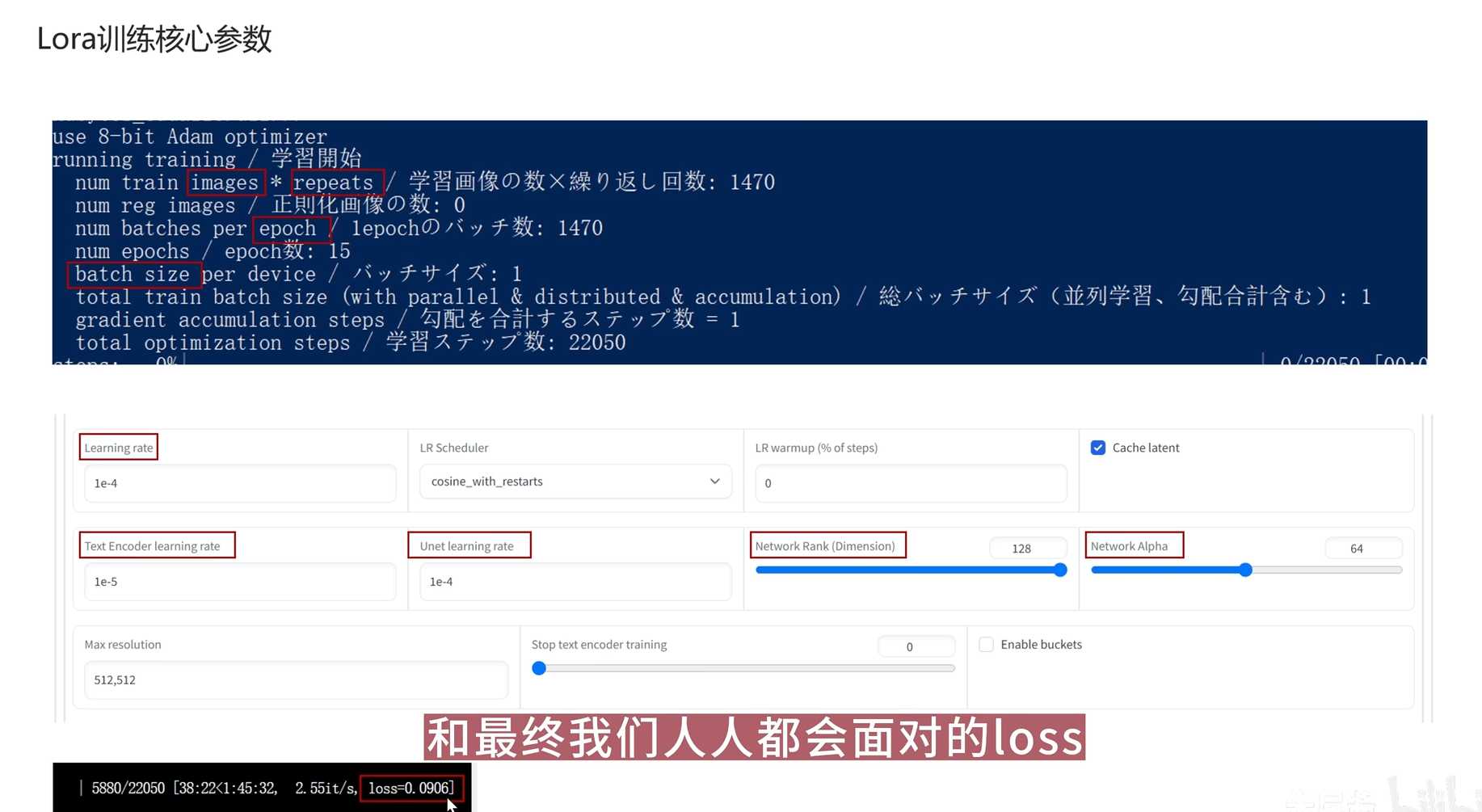
- 下图框选出的参数

- 核心参数分为两大类,一个是步数想关参数,一个速率质量相关参数
- 步数想关参数
- Image是指训练集中的图片数据。
- Repeat是指AI对每张图片学习的次数。
- Epoch是指训练集中的图片数量,表示一次完整的训练循环。
- Batch Size是指每次训练中同时学习的图片数量。
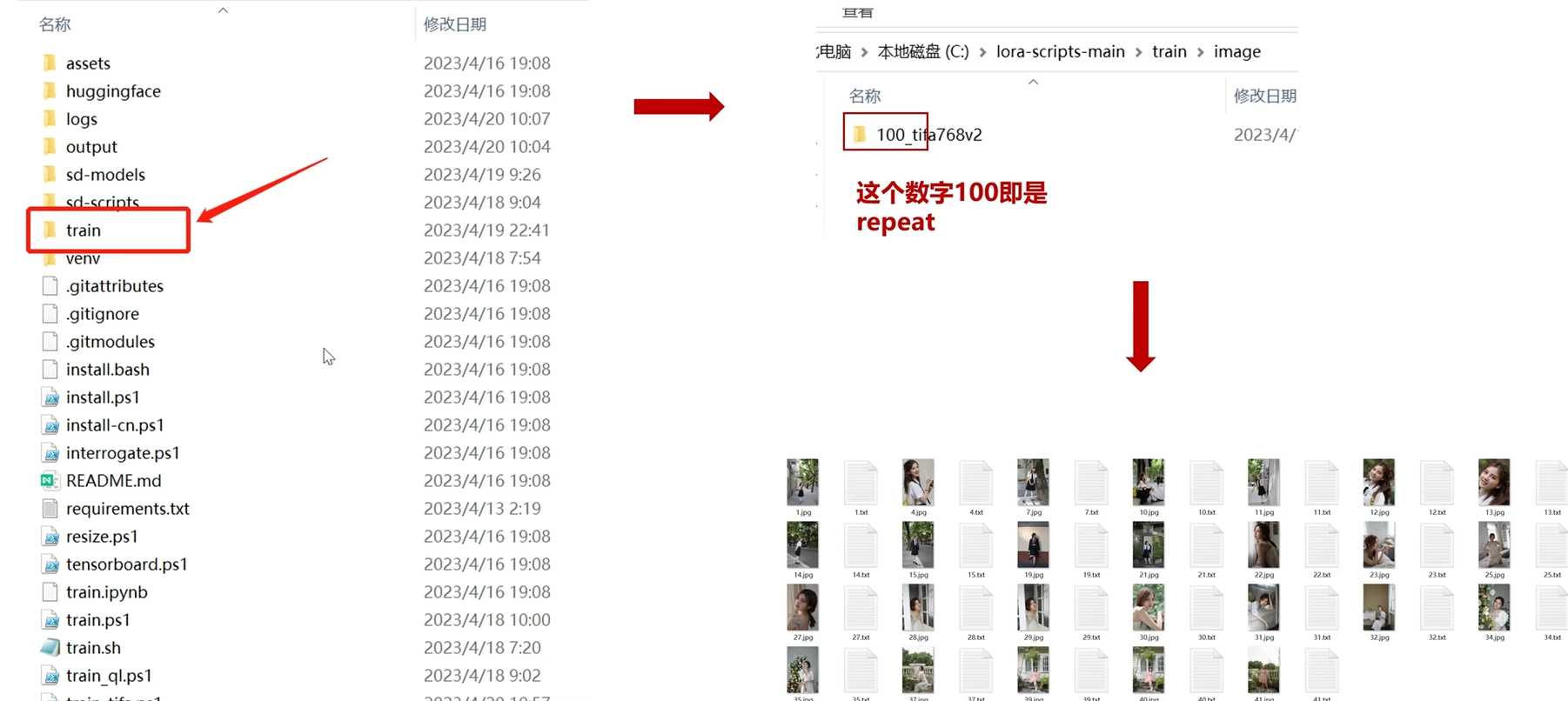
- -Train是训练集的文件夹,包含了图片和文本文档。里面我们还会建一个二级文档如图所示,这个参数需要在这里设置。Repeat参数是在Train文件夹中的文件命名中体现的,代表AI对每张图片学习的次数。
- -Train是训练集的文件夹,包含了图片和文本文档。里面我们还会建一个二级文档如图所示,这个参数需要在这里设置。Repeat参数是在Train文件夹中的文件命名中体现的,代表AI对每张图片学习的次数。
- 训练集的准备对于模型的结果和生成图片的质量具有重要影响。好的训练集应该包含充分的素材,覆盖不同角度和近景、中景、远景等不同特征,素材的分辨率和清晰度也会影响模型的效果,建议使用高分辨率的素材进行训练。对于练人或物品等细节较多的素材,建议使用更高分辨率的原图进行裁剪或训练。
- 在训练AI模型时,使用文本文档来描述图片的特征非常重要。如果没有准确的描述,AI将无法正确学习。
- Tag的描述:在文本文档中,应该对图片的特征进行详细精确的描述。例如,描述一个女孩的发色、眼睛、姿势、背景等。描述越精细,训练出来的模型就越准确。
- Tag的描述:在文本文档中,应该对图片的特征进行详细精确的描述。例如,描述一个女孩的发色、眼睛、姿势、背景等。描述越精细,训练出来的模型就越准确。

– 示例:给出了一张图片和自动生成的Tag文本,分析了其中的问题,并进行了手动调整和补充。使用圆Tag生成图片时,与原图越接近说明Tag越准确。

- 训练集的要点
原图的分辨率越高越好,素材尽可能丰富,覆盖不同光影不同角度,Tag除了Al自动达标外还要手工调整、补充更好的原图,对学习参数的设置要求就会更高,且不是图片越多越好,要寻求最优解。 -
Repeat参数:Repeat是AI对于一张图片的完全扫描。对于复杂的图片,需要更多的Repeat次数,但也不能过高,以免固化模型的认知能力。没有最高值或最低值,只有最优质这点跟epoch很像,在训练过程中,需要找到适合的Repeat次数,以保证模型的学习效果和训练效率。
-
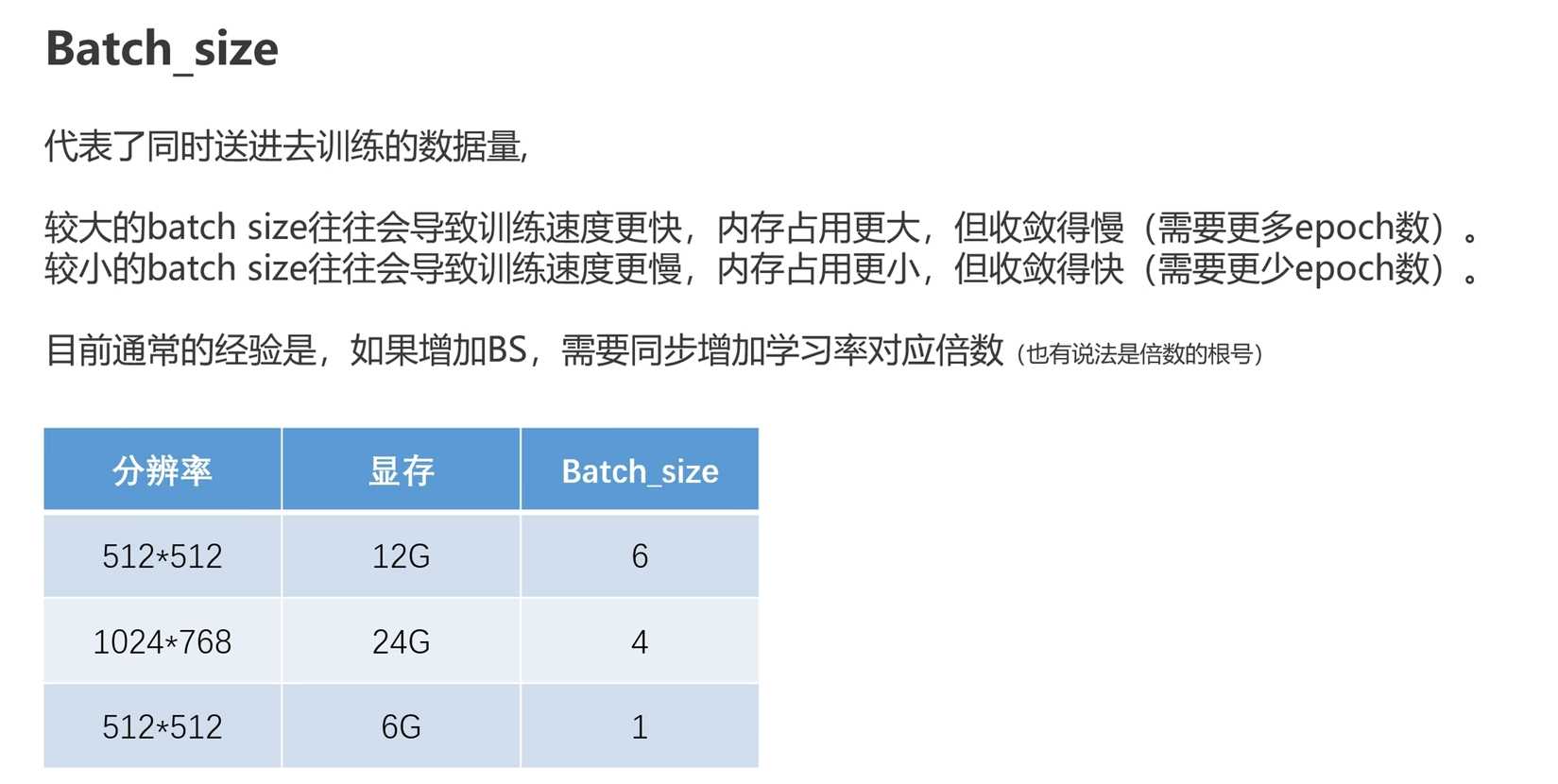
Batch Size的重要性:
- Batch Size代表AI在同一时间学习的图片数量
- 取决于显卡显存大小,6G显存以下的建议使用1
- 高级显存可以使用更大的Batch Size,加快训练速度
- 增大Batch Size会导致收敛变慢,学习更快但学习到真正像素级别的过程变慢,囫囵吞枣。
- 减小Batch Size会导致训练速度变慢,但收敛更快,学习更像素级别
- 增加Batch Size时,需要相应增加学习率(1e-4增加)
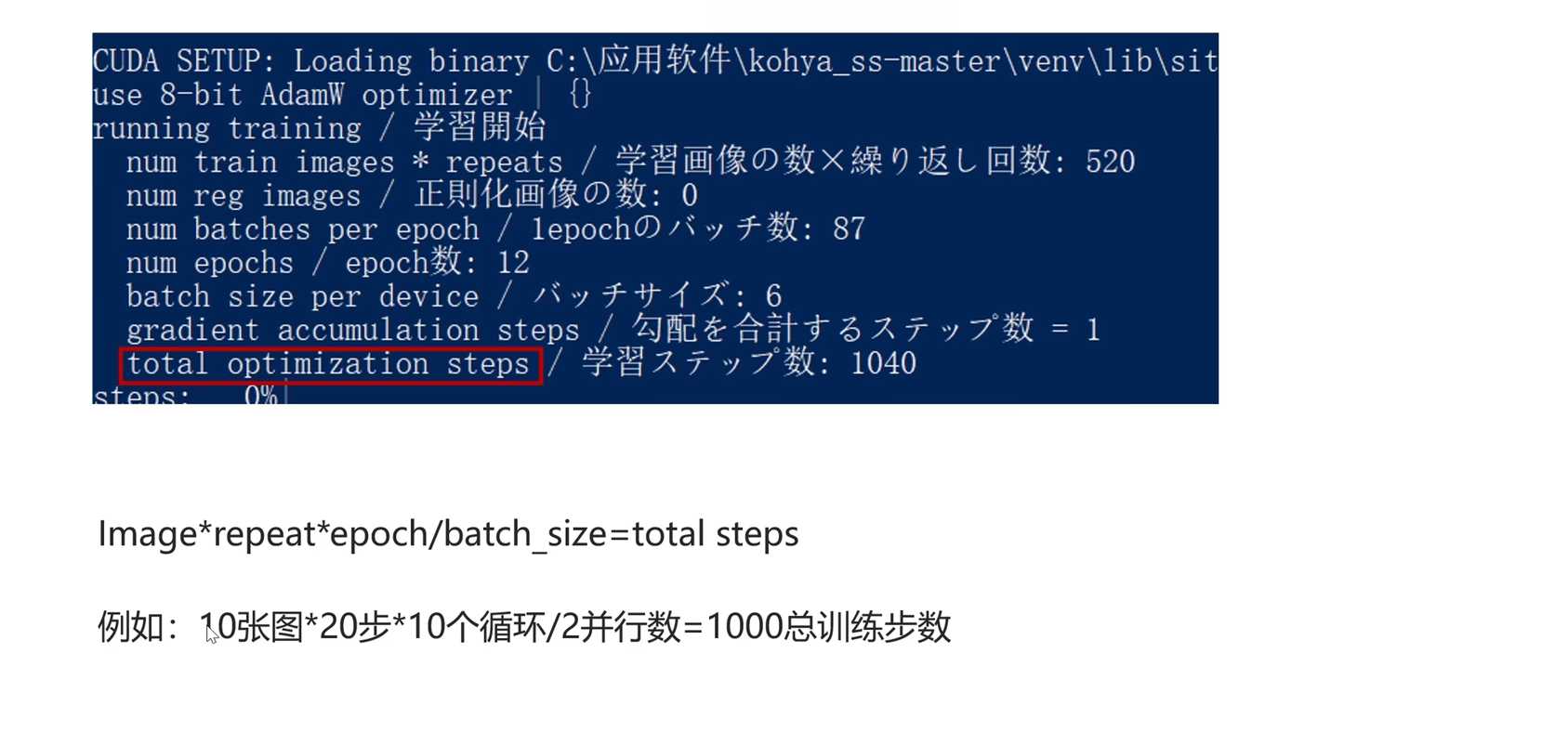
- Total Optimization Steps:
- 总学习步数的计算公式:Image数量 x Repeat x Apple / Batch Size
- 例如:10张图片,20步,一个循环是200步,共学习10个循环,总步数为2000步,Batch Size为2,则实际总训练步数为1000步
- 速率和质量相关的核心参数:
- 学习率决定了AI学习图片时的效率和速率
- 学习率高,AI学习速度快,但可能导致过拟合
- 学习率低,AI学习速度慢,可能导致欠拟合
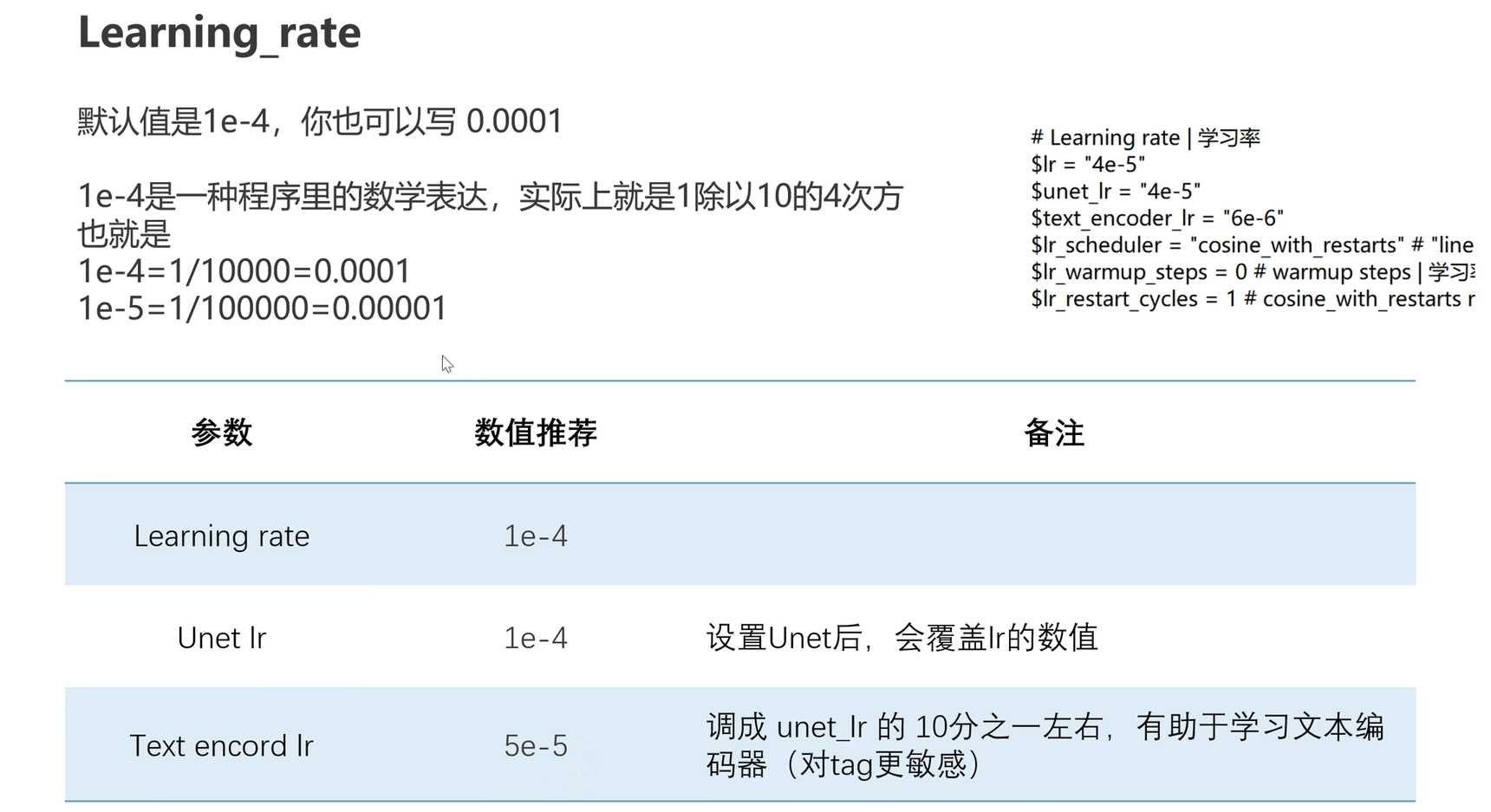
- 建议使用1e-4的学习率进行配置,避免输错
- learning_Rate是用于学习文本编码器的学习率参数
- 通常设置为unet lr,1e-4(1/10的四次方)
- 可使训练对标签更敏感
- Text encord Ir:5e-5
调成unet Ir的10分之一左右,有助于学习文本编码器(对tag更敏感)
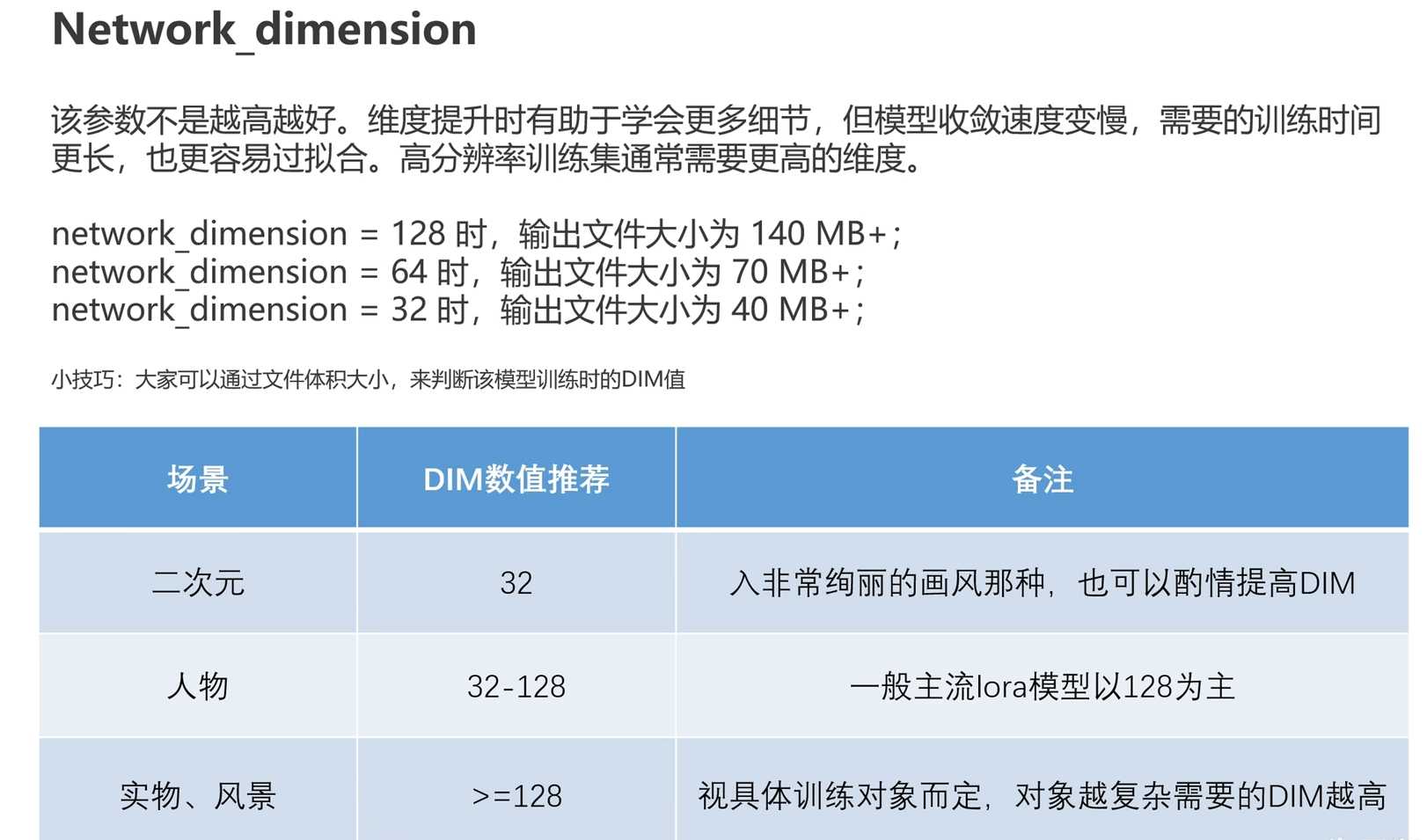
- Network dimension是网络维度参数,决定了生成图片的精细度
- DM越大,网络维度越高,生成的图片特征越精细
- 建议使用128的DM进行训练,适用于大多数情况
- 对于二次元图片,可以根据需要提高DM
- Optimizer优化器是决定学习率调整逻辑的参数
- 常用的优化器有Adam8bit、DA和LINE
- DA用于测试一组素材的最优学习率
- 最优学习率可用于Adam8bit或LINE进行训练
- 使用LINE时,建议最优学习率除以3后进行训练
- 参数之间的影响和模型结果的影响可以通过实证数据进行理解
- 使用实证数据来解释参数和模型之间的关系
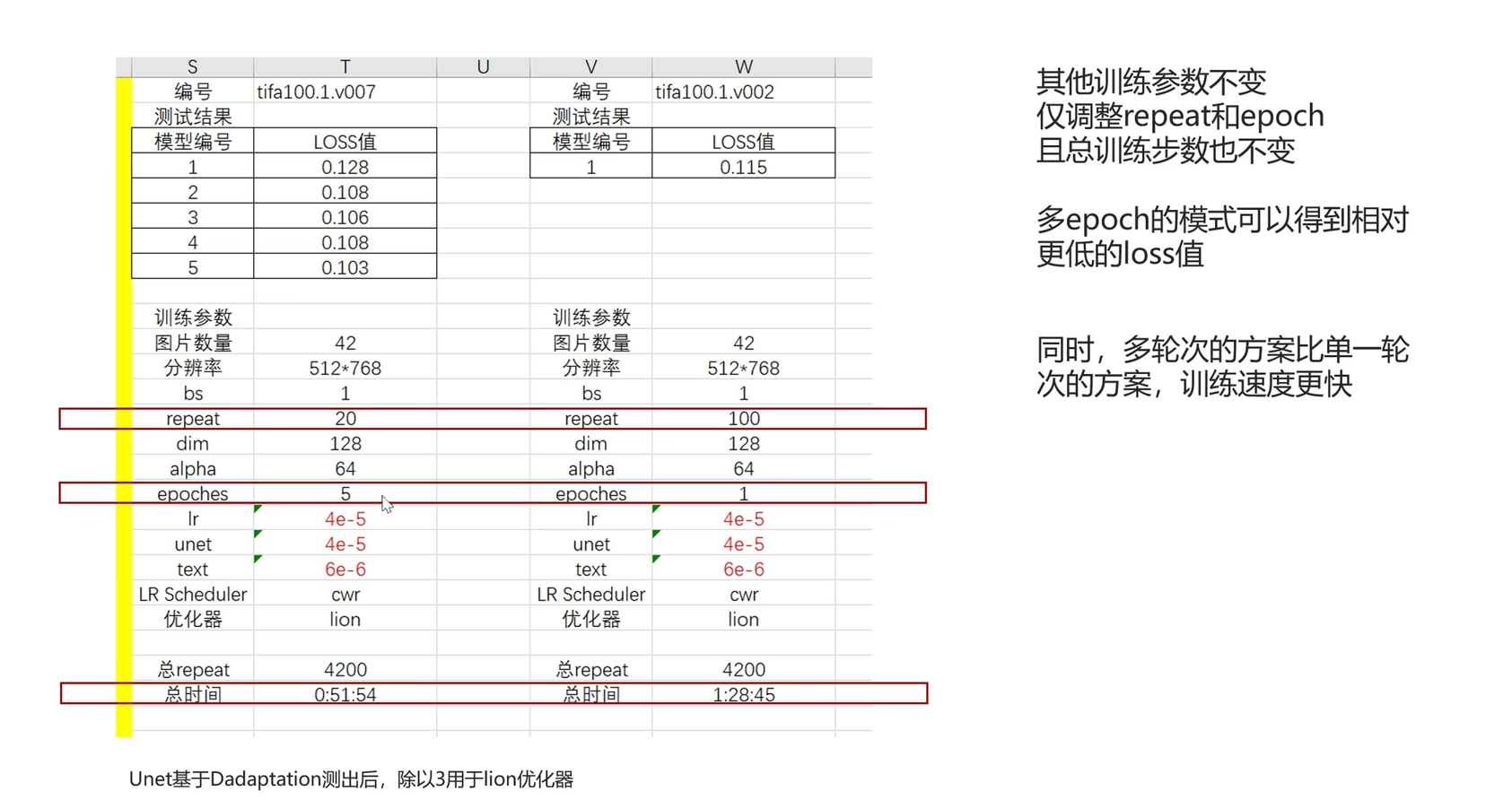
- repeat和apoc是训练模型时的两个参数,对训练时间和结果都有影响。
- 使用实证数据来解释参数和模型之间的关系
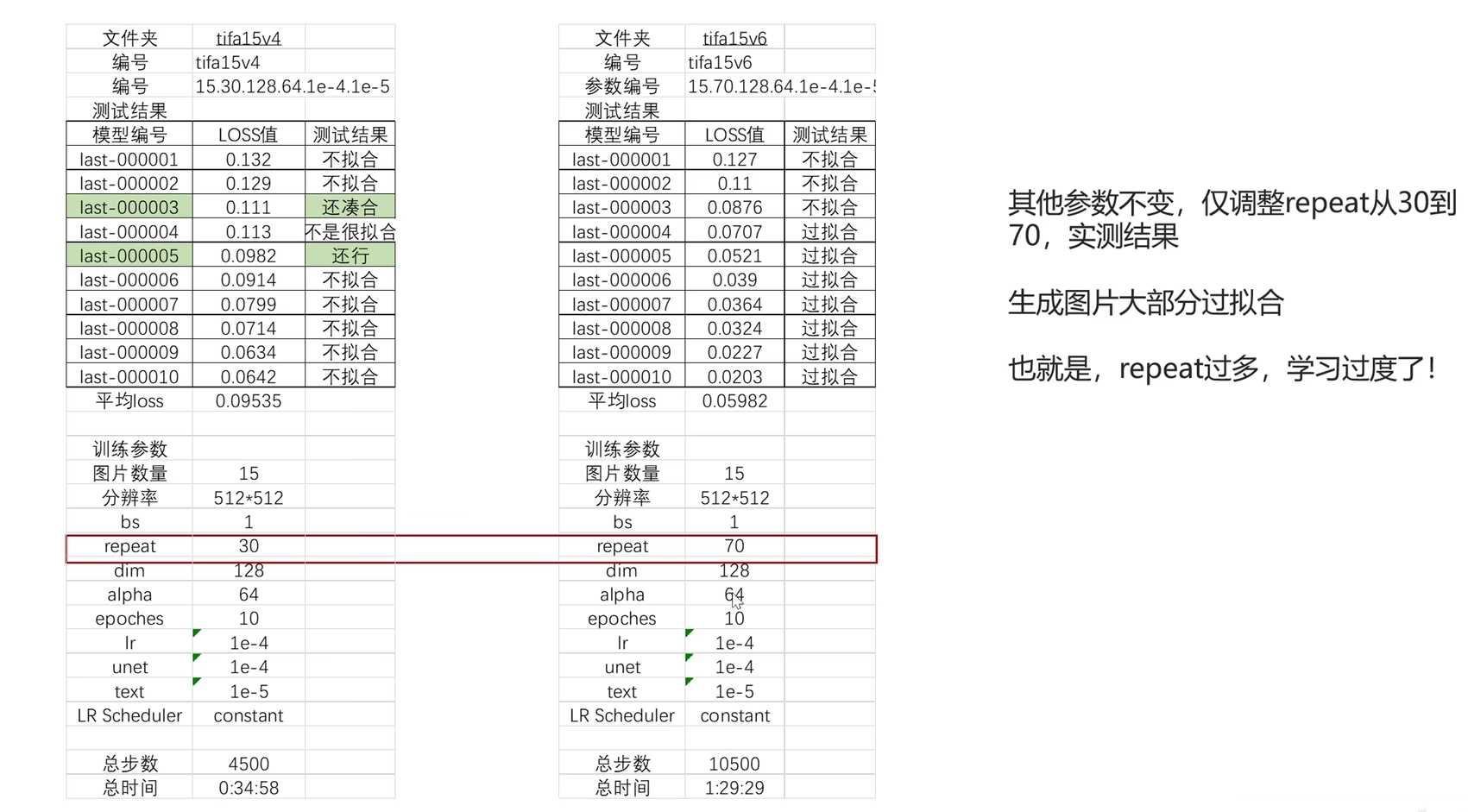
- repeat参数:
- repeat参数指定了模型训练的重复次数。
- 当repeat较小(例如30)时,模型不够拟合,训练力度不够。
- 当repeat较大(例如70)时,模型过拟合,导致训练结果不好。
- repeat不是越多越好,而是需要合适的数值。
- epoches参数:
- epoches参数指定了每张图片学习的次数。
- 当epoches较小(例如20)时,需要多轮次的训练才能达到总的学习次数。
- 当epoches较大(例如100)时,单轮次的训练就能达到总的学习次数。
- 多轮次epoches的优势之一是训练时间更短。
- 多轮次epoches的另一个优势是模型的拟合性更好。
- 结论:
- repeat和epoches对训练时间和结果都有重要影响。
- repeat不是越多越好,需要合适的数值来避免欠拟合和过拟合。
- 多轮次epoches可以更快地达到总的学习次数,并且拟合性更好。
- 多轮次epoches可以增加得到好模型的概率。
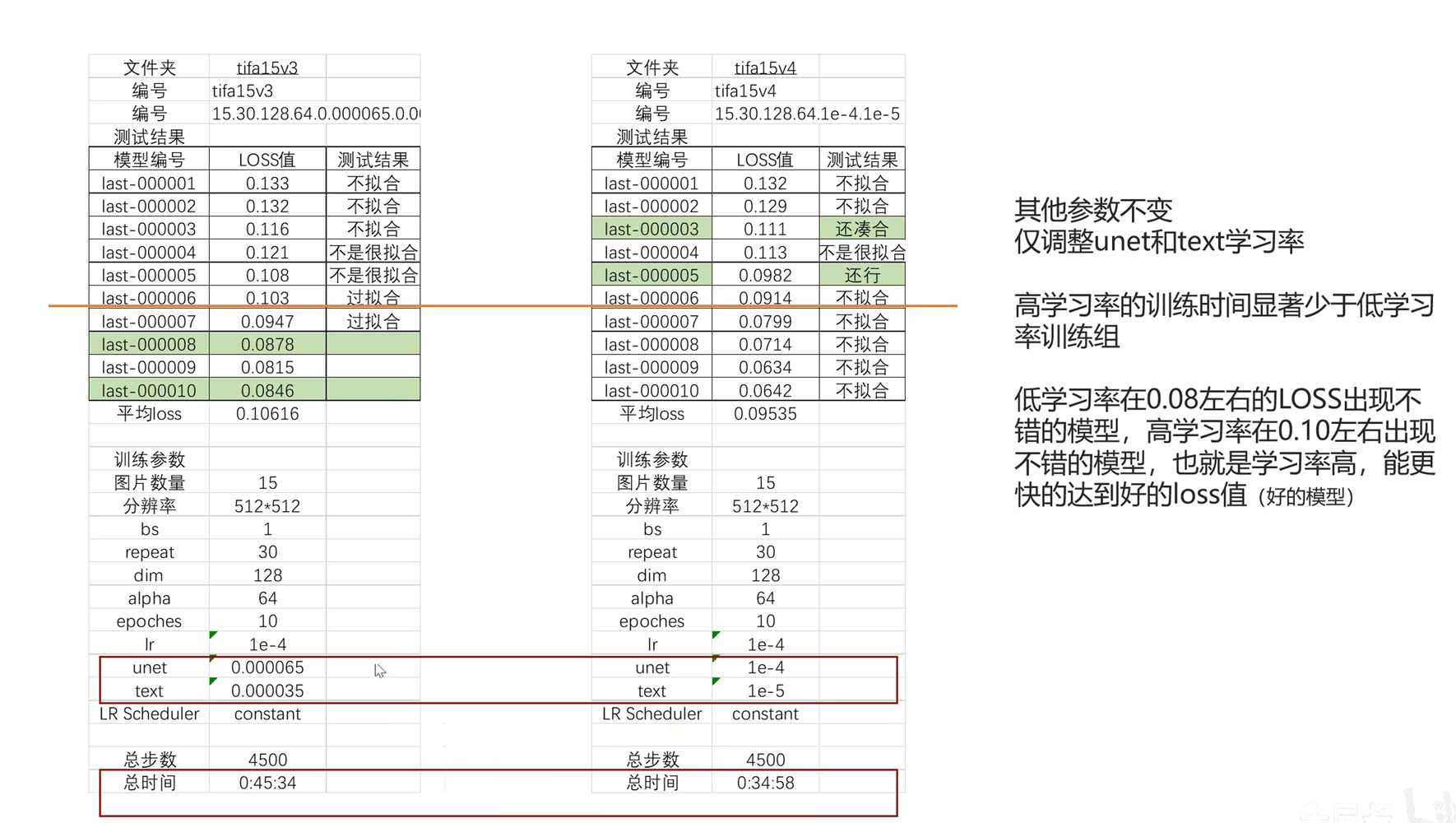
- 学习率对模型训练的影响
- 降低学习率会增加总训练时间
- 降低学习率会推迟得到好模型的时间周期
- AI中存在不确定性和逻辑,无法确定增加或减少的方式
- 学习率对模型结果的影响
- 给出了unet学习率调整对模型结果的实证数据
- 新手参数建议
- image图像质量应尽可能高
- repeat次数一般在7到15之间,人像可能需要20到30
- epoches建议新手使用10,以增加得到好模型的概率
-
unet lr学习率:一般为1e-4,根据实验经验调整,如果loss无法降低,可以增加学习率;如果loss过低或无法得到理想模型,可以调整学习率。
- DM(network rank)参数:一般建议使用128。
- alpha参数:一般建议使用一半或介于1到128之间,不要超过DM。
- Loss值:通常0.08左右的loss值被认为最优,但不要迷信loss,建议新手测试所有模型,根据特定图片寻找最佳模型。
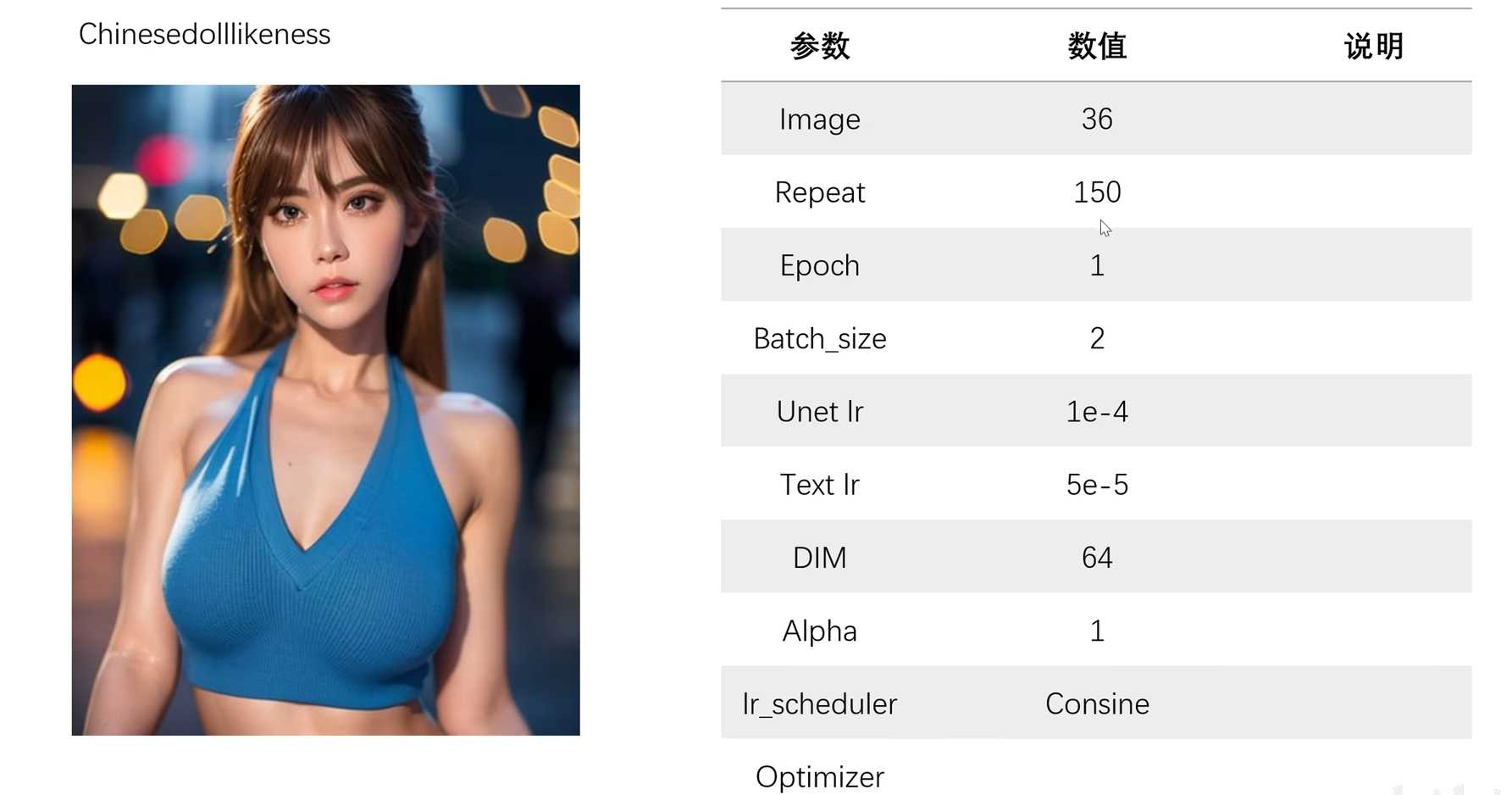
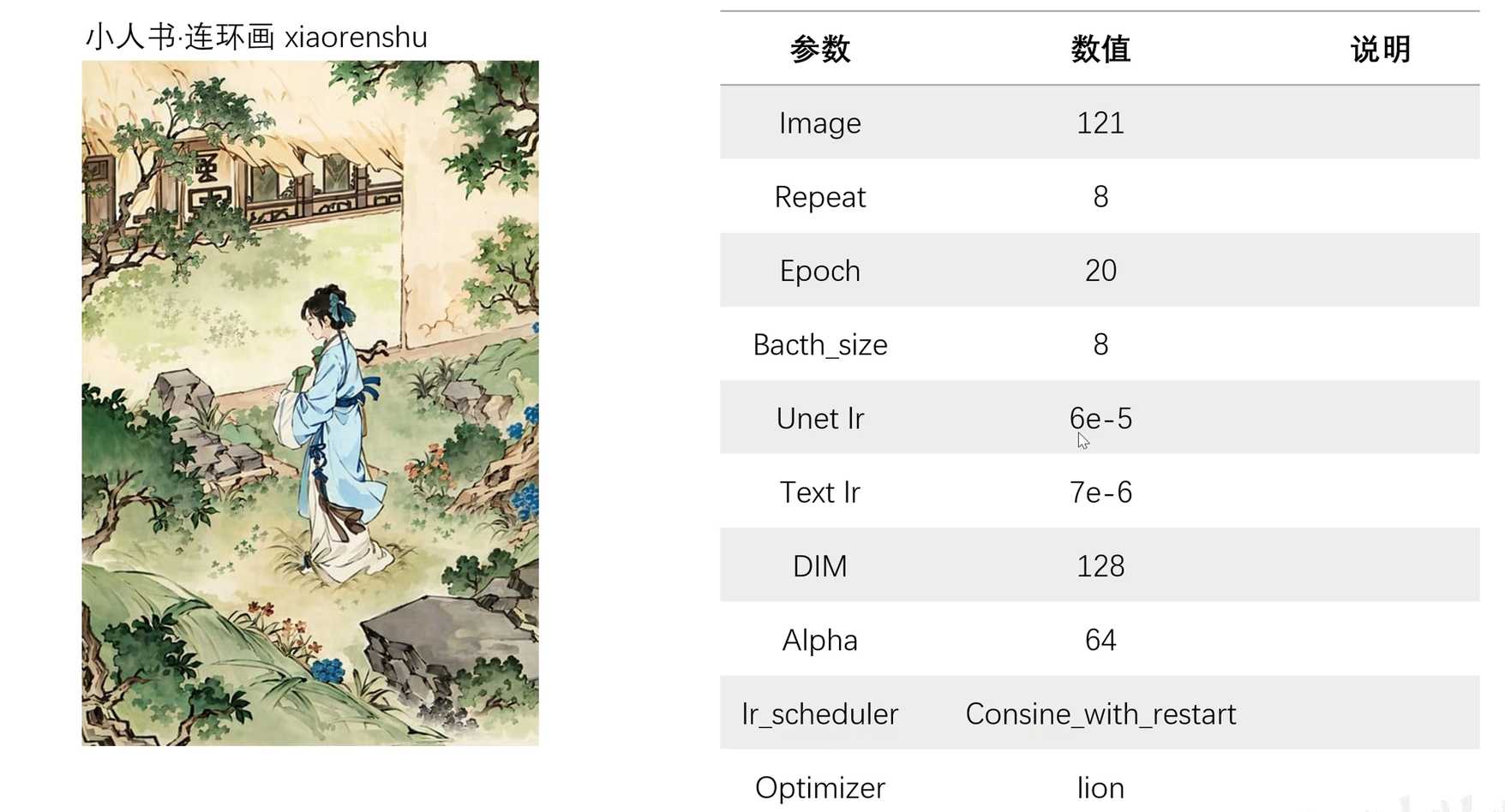
- 案例分享:介绍几个成熟案例及其对应的参数。
- 案例一:Lora模型,训练时使用36张图片,每张图片重复150次,batch size为2,单元学习率为1e-4,DM为32或64。
- 案例二:Aespa模型,使用26张图片,每张图片重复7次,训练了20个轮次,batch size为7,单元学习率为1e-4,DM为128,alpha为128。
- 案例三:小人书模型,使用121张图片,每张图片重复8次,标准的24小时训练参数,batch size为8,单元学习率为0.6的1e-4,DM为128。
- 案例一:Lora模型,训练时使用36张图片,每张图片重复150次,batch size为2,单元学习率为1e-4,DM为32或64。
UP:朱尼酱
© 版权声明
文章版权归作者所有,未经允许请勿转载。