
摘要
这个视频是关于“stable diffusion”的教程,作者通过详细讲解模型结构和原理来介绍stable diffusion的工作过程。
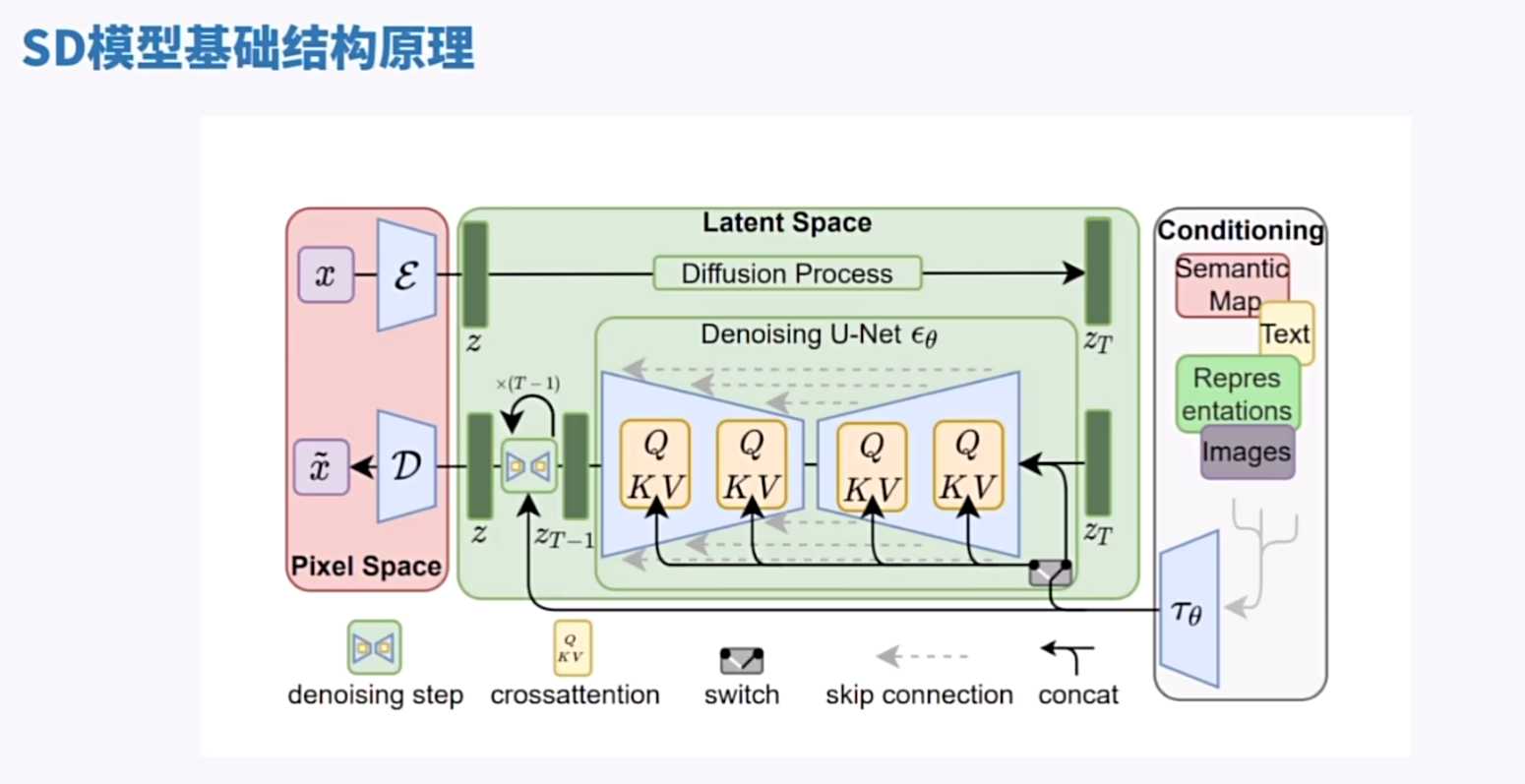
– stable diffusion是一种用于图像生成的神经网络结构,由latent diffusion(stablediffusion最早版本)论文提出。
– 这个结构分为三部分:pixel space(像素空间)、latent space(潜空间)和conditioning(条件)。
– Pixel space像素空间:
– 我们通常的图片在像素空间。
– 图像经过编码器VAE(E)和解码器(D)。VAE充当latent space和像素空间之间的桥梁,称为VAE(Variational Autoencoder)。
– Latent space潜空间:
– Latent space潜空间,是在像素空间和隐变量空间之间的过渡空间。
– 在这个结构中,通过不断迭代的单元(unit)来优化网络。
– Conditioning条件:
– 作为条件输入,文本在这里输入的。
– 在AI绘画中,通过交叉注意力层(Cross Attention)将文本和unet结合起来进行迭代(step)。
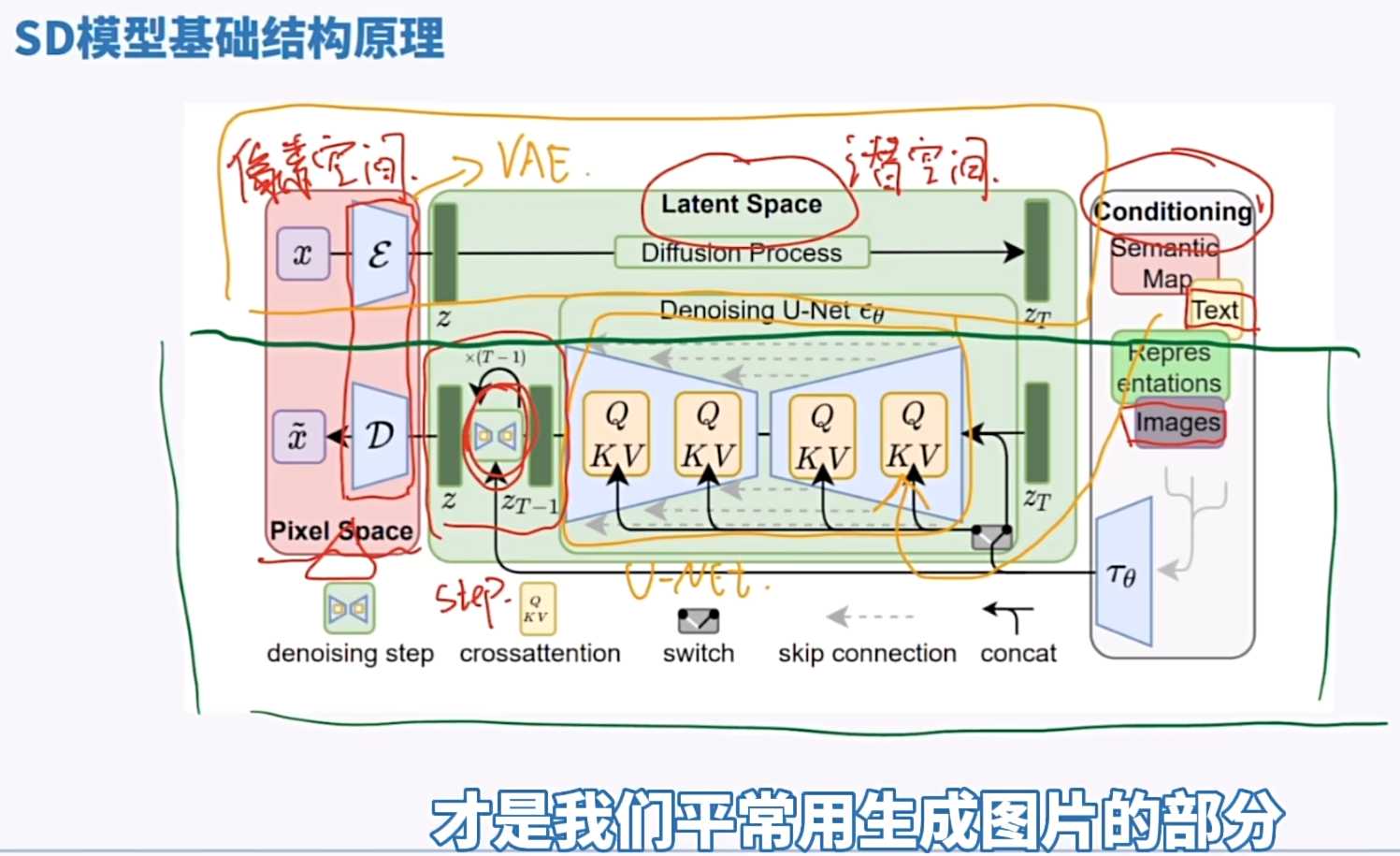
– Stable Diffusion生成过程:
– 上半部分(像素空间),通过给正常图片增加噪声,然后得到一张混乱噪声图片,这部分用于训练模型。
– 下半部分,就是我们平常所说的绘图,我们使用输入文本,通过网络生成图像。生成的图像在整个过程中,都是在潜空间内操作的。
亮点
【SD基础结构】图像上传和生成的过程:通过latent space(潜空间)和pixel space(像素空间)的交互,使用条件生成在潜空间内进行图片生成。
- 为什么要在潜空间运作?
- 潜空间是一种压缩过的空间,使用潜空间的原因是为了解决计算算力的问题。
- 家用电脑等传统设备难以处理大尺寸图片的计算需求,而潜空间可以显著减少计算量。
- SD模型基础原理
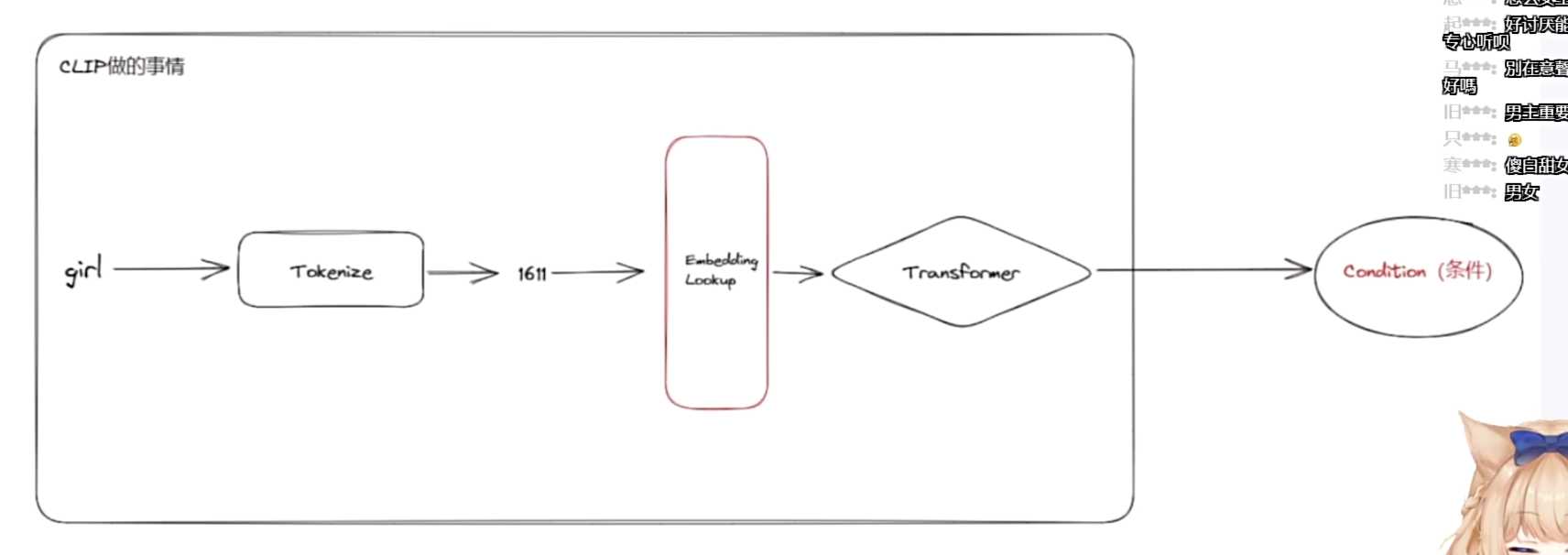
- SD模型是整体的潜空间结构原理。
- 先输入一段文本,经过文本编码器后进入Unet部分。
- Unet是负责上传图片的关键组件。
- 最后通过懒上传完成图片的生成,并送入VAE进行处理,得到正常图片。

- 文本编码器(clib)的作用
- 文本编码器是潜空间中的重要组件,采用的是CLIP的Text Encoder部分
- 它是一种基于对比学习的多模态模型
- 输入文本,经过文本编码器编码后才能进入Unit部分。
- 对文本编码器进行训练可以提升的性能和效果。
- 【Unit优化网络】介绍了unit优化网络的功能和使用,它是整个stable diffusion模型中主要的图片上传部分。
-
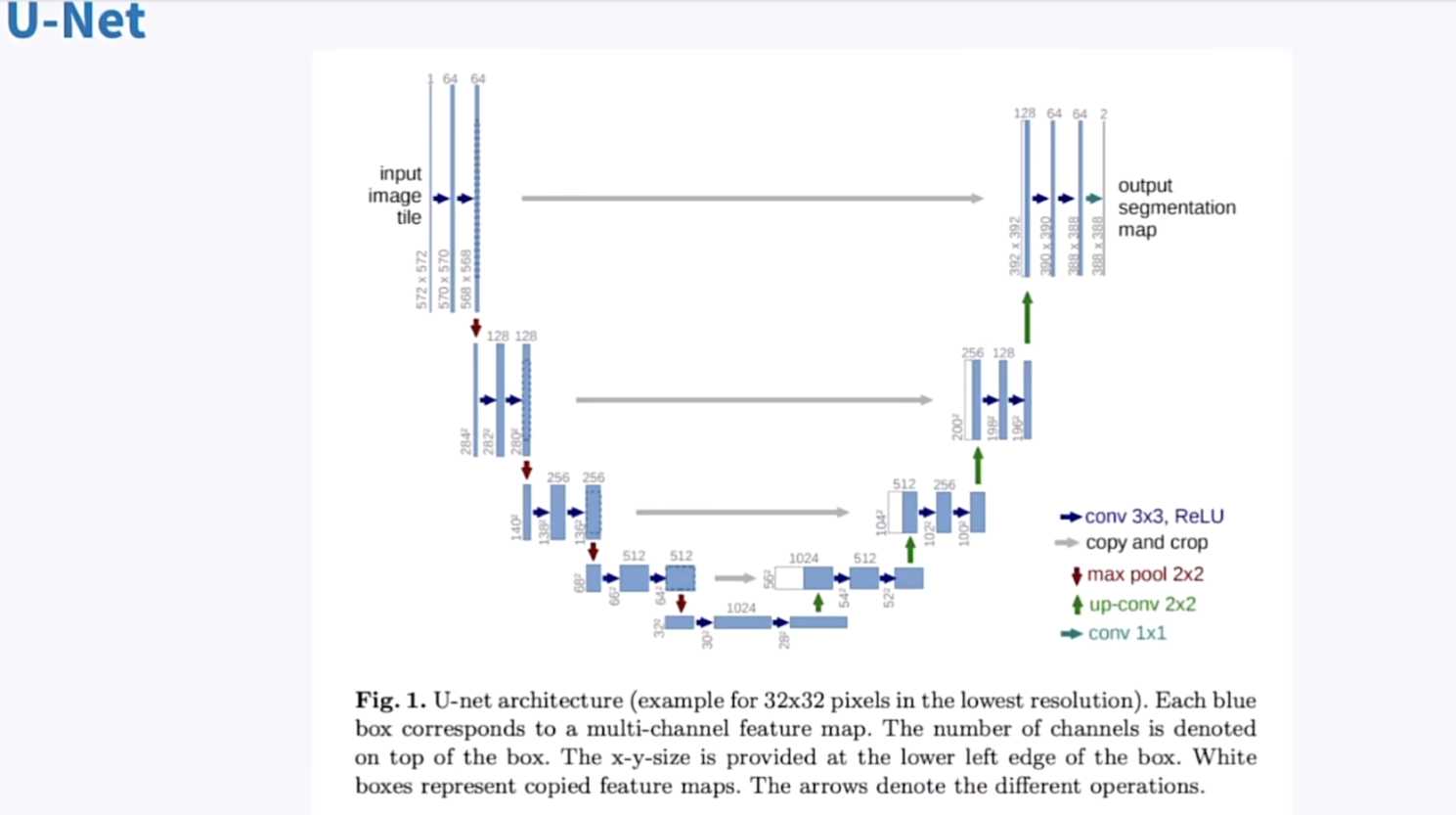
unet的介绍
- 说明UNET是常见的U型结构,与混模mix
- 描述unit的整体结构,并指出可以提供更大清晰的图片
- stable diffusion中使用的unet
- 描述stable diffusion中使用的unet的样子
- 强调unet的规模较大

常见的模型训练方式
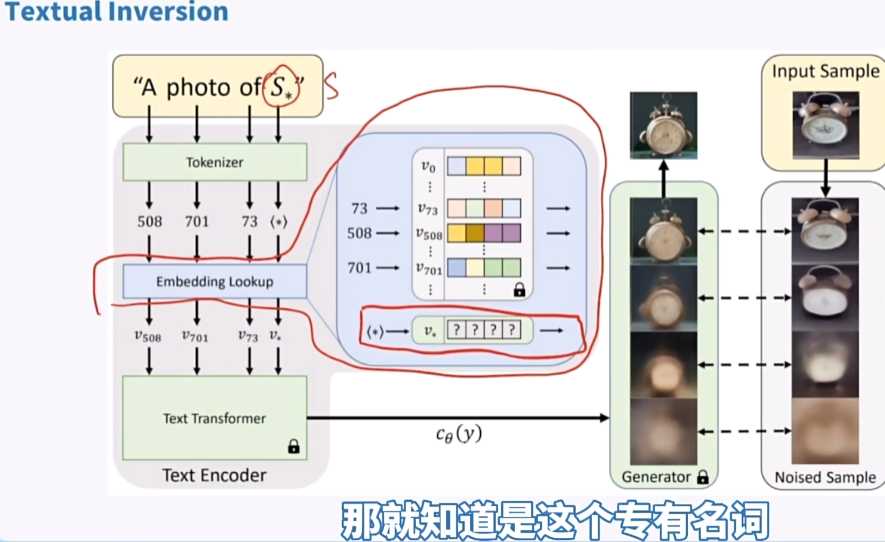
- 文本繁衍:也称为Textual Inversion,是一种常见的训练模型方式,也就是Embedding,文字编码器一旦见到这个词,就会理解,然后去找对应的语义向量。
- 超网络HyperNetwork:一种较少使用的训练模型方式
- 直接微调Finetune /Dreambooth:一种直接跳过的训练模型方式
- Finetune是直接微调,加正则化=Dreambooth
- Dreambooth是改善的,它入了一些之前模型生成的图片来防止摸型忘起以前学的东西。

Finetune/Dreambooth训练方式
- 我的autod训川练脚本(在线训练/linux下比较方便)
- Naifu-Diffusion (finetune)
- HCP-diff
- Kohya的训练脚本/U川
- 使用DreamBooth插件(非常不推荐)

Finetune/Dreambooth参数推荐
- Finetune基础学习率:3e-6
- bs:小样本集(百张级别)3以内可以开scale/sqrt lr大样本集(千、万张)能开多大是多大
- 步数:百张左右1w步,图片多的情况5 epoch以上自动打标准确率:0.35以上,手动打标:尽可能全面。

Finetune/Dreambooth参数推荐
- 底模:尽量选择本身就与要训练物体相同相似的,减少难度
- 素材:尽量丰富多样,不要类似差分图
Finetune/Dreambooth训练参数调整
- BatchSize应该是第一个确定的超参数
- 由BS确定后,第二个确定学习率
- 学习率应该由小到大尝试
- 最不重要的是步数,可以跑个几万随便对比看哪个好
- lora系列
- lycoris因为引入了对convolution卷积低秩分解,能改的更多一些(到resnet部分),所以训练lycoris更容易过拟合,他对网络的控制性也越强。
- lora,原版lora只对Unet它改了一小部分
- lycoris因为引入了对convolution卷积低秩分解,能改的更多一些(到resnet部分),所以训练lycoris更容易过拟合,他对网络的控制性也越强。

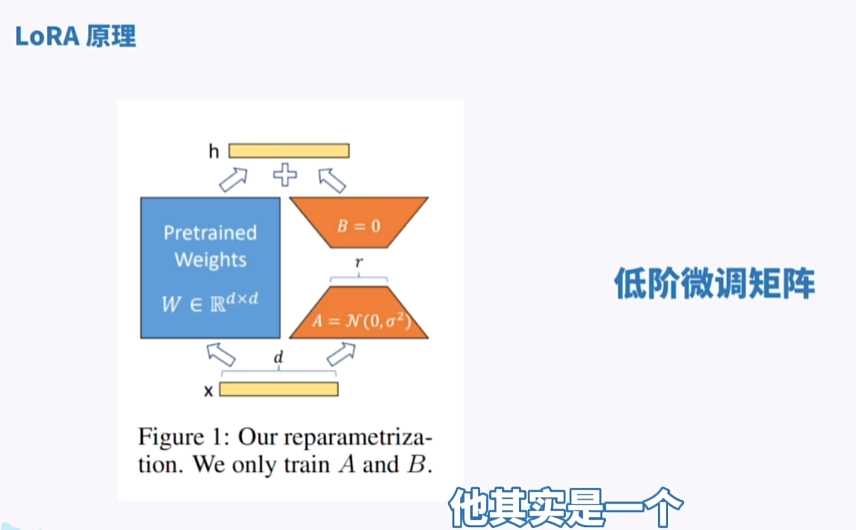
lora原理
实际上我们就可以理解成 开了一个旁路去再低阶微调transformer, 然后再加回去 大概就是这么一种感觉 就是开了一个小的东西去调整 然后再加回去就行了就是这么一种感觉。
lora训练参数(Adamw8bit优化器)
- U-Net学习率:1~1.5e-4
- TextEncoder学习率:1e-5
- bs:不推荐太大
- 步数:0~20 epoch
- 自动打标准确率:0.35以上
- 手动打标:全面
- 更多的参数放在下面的过拟合部分一起说
过拟合特征
- ·Tag失效
- ·画面物体/人物出现诡异细节
- ·画面线条变粗
常用减轻过拟合方式
- 数据增强(数据准备不够时需要)
- *减小学习率
- *减小epoch/step
- 不训练TextEncoder
- 更换Optimizer
- Drop out
一般数据增强(LoRA训练较少用)
- Color Skew随机调整色调饱和度
- Black and White黑白化
- Crop剪裁
利用AI进行数据增强
- 图生图
- 线稿生成
- 基于已有的模型生成更多图片
学习率/Scheduler
- 使用余弦/带重启的余弦
- 优先尝试低学习率,再试提高学习率是好还是坏

优化器Optimizer
AdamW(default),AdamW8bit,Lion,SGDNesterov,
SGDNesterov8bit,DAdaptation,AdaFactor
推荐
– AdamW8bit(常用的8 bitadam)
– Lion更易过拟合,学习率需要低一些一般是1/3
– 一些自适应学习率的优化器,占用更多显存
不对Text Encoderi进行训练
- 如果训练Text Encoder,模型非常容易过拟合
- 训练Text Encoder同时需要减小学习步数/学习率

如何补救过拟合模型
- 与其他正常模型进行融合
- 使用时加入ControlNet:进行额外控制
- 针对部分TE过拟合的模型,可以尝试使用其他模型的TE覆盖

相关文章

