
8张照片就可以训练个人LoRA,用StableDiffusion打造“AI写真”?Stable Diffusion EasyPhoto扩展插件教程
前段时间,妙鸭相机靠一手 AI 写真成为了 2023 年国内第一个爆补出圈的 AIGC 产品。上传 20 张左右的连相照片,交个 9.9,就能为自己制作一个数字分身,生成不同风格的写真照证件照。我试了一下,感觉还挺逼真的。你觉得这些照片像我本人吗?
Easy Photo
熟悉 SaberDiffusion 的朋友们都知道,它用到的核心技术就是 AI 绘画里的 LoRa 训练。制作数字分身就是通过用户上传的这些照片,训练出一个人物 LoRa,用来记住你的样貌、五官、发型、体格。赛事方式,加入这个 LoRa 模型,结合大模型与合适的提示词,就能生成非常像名的 AI 照片了。传统的 LoRa 训练界面的参数复杂,给素材打标、清洗需要花费不少时间精力,对配置也有不低的门槛要求。但在万能的 SaberDiffusion 里,有一个非常神奇的插件,从底层逻辑上复刻了妙鸭的这一套技术架构。只需要上传 5-10 张照片,不用打标,甚至连参数都不用设置,就可以训练出一个高质量的人物 LoRa,
并内置了一套完整的照片生成工作流,可以智能地将人脸融合到你自己生成的作品里。甚至,只用这个简单选项,就可以自由定义人物、场景、拍摄环境,实现 AI 写真自由。
安装 Easy Photo
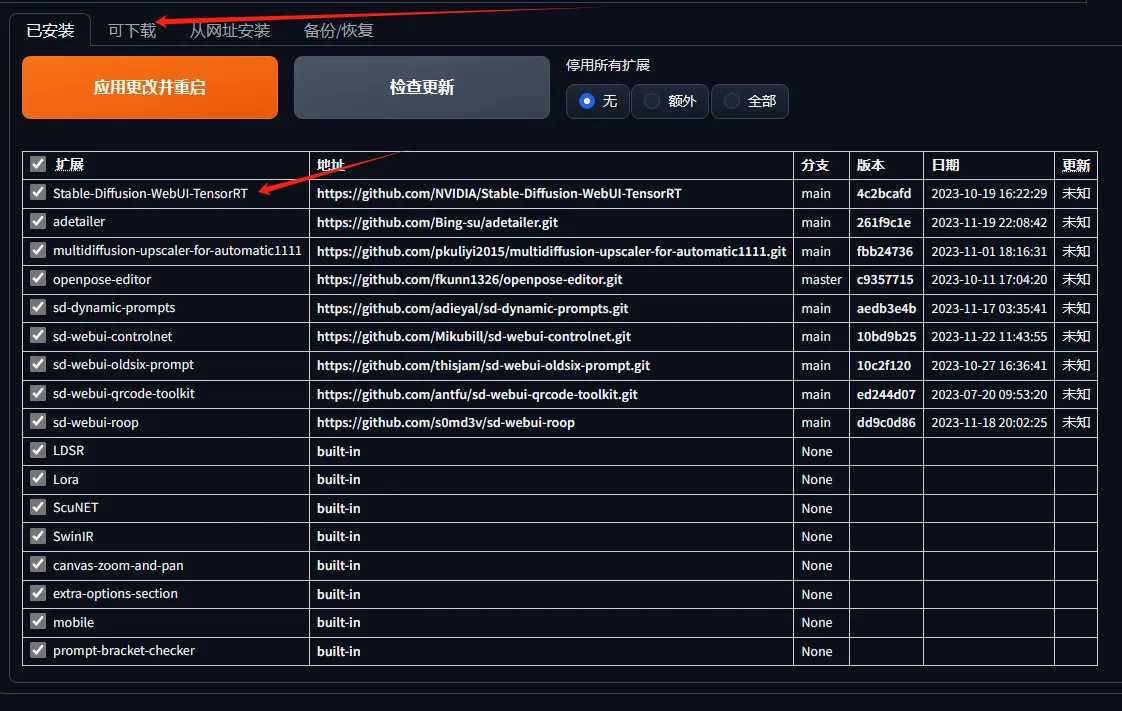
安装 Easy Photo 的方法很 Easy,将它的 GitHub 仓库地址复制到 WebUI 里的扩展标签里,从网址安装,或者直接在扩展列表中搜索 Easy Photo 点击安装,就可以在你的 Stability Vision 里使用它了。如果安装的过程中存在连接问题,你也可以从页面下次代码欧,写压缩,放到根拨度下的 Extensions 文件夹内。安装完成以后,整个除夕 WebUI 它会自动下载其他所需的依赖,全部同步了国内的下载源,非常顺利且快速。然后,它就会出现在你的 WebUI 标签栏里了。你无需自己配置一些其他的额外软件或环境,但需要在你的 WebUI 里安装 ControlNet,因为它会用到 ControlNet 里的一系列控制模型来辅助生成照片。不会还有人没安装 ControlNet 吧?如果还没有,请收看之前的 ControlNet 基础入门教程,花上一点时间把它安装配置好,并在设置里将这个 ControlNet 的最大单元数开到 3 以上,来支持多重 ControlNet 发挥作用。
使用 Easy Photo 生成 AI 写真
使用 Easy Photo 去生成 AI 写真的方法也很 Easy。为了让你清晰体会 Easy Photo 是如何生成 AI 写真的,我拿自己来做个实验,在它这里定制一套 AI 写真,把整个流程和基本操作方法讲清楚。
Easy Photo的工作分为两大板块:训练和推理。
– 训练阶段涉及亲戚人像照片的收集和模型参数设置。
– 推理阶段包括模板选择、模型和用户ID设置以及生成新照片。

训练阶段:
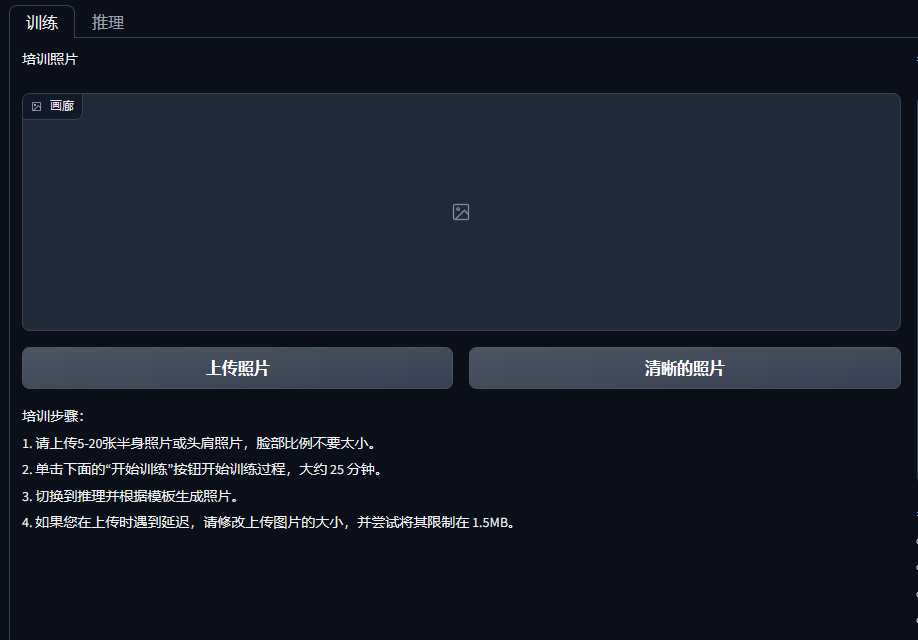
- 打开”Train”标签,收集5到20张亲戚人像照片。
- 选择要用于训练的基底模型,如”Realistic Vision”。
- 输入用户名(User ID)并启动训练。
- 观察训练进度,使用WebUI命令行进行实时反馈和错误排查。
推理阶段:
- 切换到”推理”标签。
- 选择要生成的照片类型,如证件照。
- 设置推理使用的模型和用户ID。
- 点击”开始生成”,等待几十秒到几分钟不等的生成时间。
- 在右边验收新生成的AI证件照。
自定义照片融合:
- 如果新生成的照片不满意,可以使用自主上传照片功能。
- 在”上传图像”标签中,拖入自己通过SD生成的图片。
- 选择模型和用户ID,再次点击”开始生成”。
- 这样可以实现更加自然的人脸融合,使照片更像自己。
通过这些步骤,您可以使用Easy Photo进行亲戚人像照片的训练和生成,同时还可以通过自主上传照片来个性化调整生成效果。
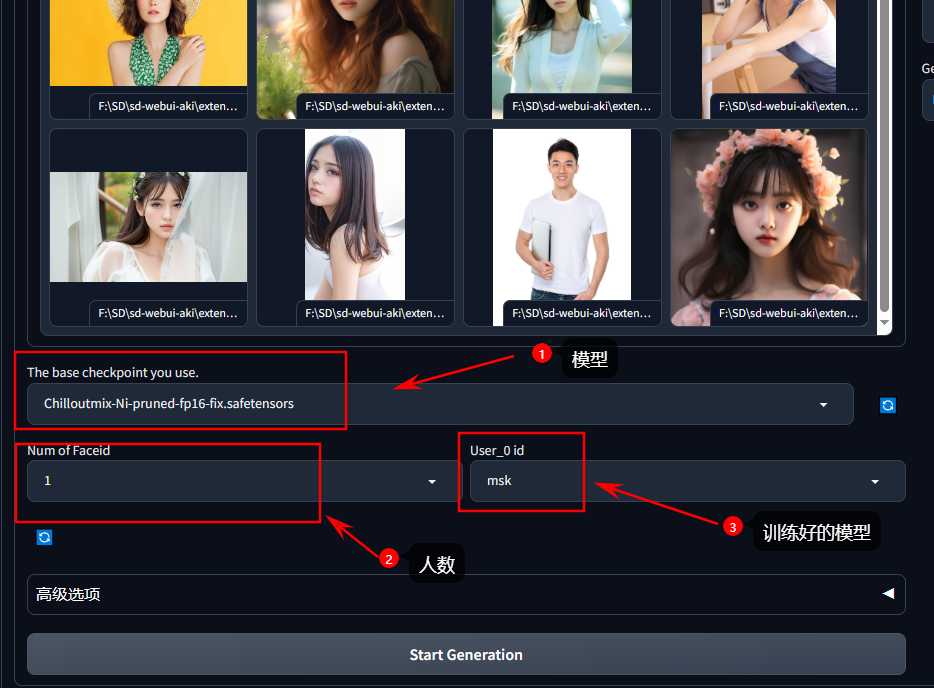
- 打开Train(训练)标签,收集写真主人的人像照片(5-20张),包括各种类型的照片。最好不要有远景或低质量图像。

- 上传照片到训练图库,并设置相关训练参数。
- 选择一个用于训练的基底模型,默认模型:Chilloutmix-Ni-pruned-fp16-fix.safetensors。
- 开始训练,可以在后台黑框观察训练进度和错误信息。
- 训练完成后,进入推理阶段。
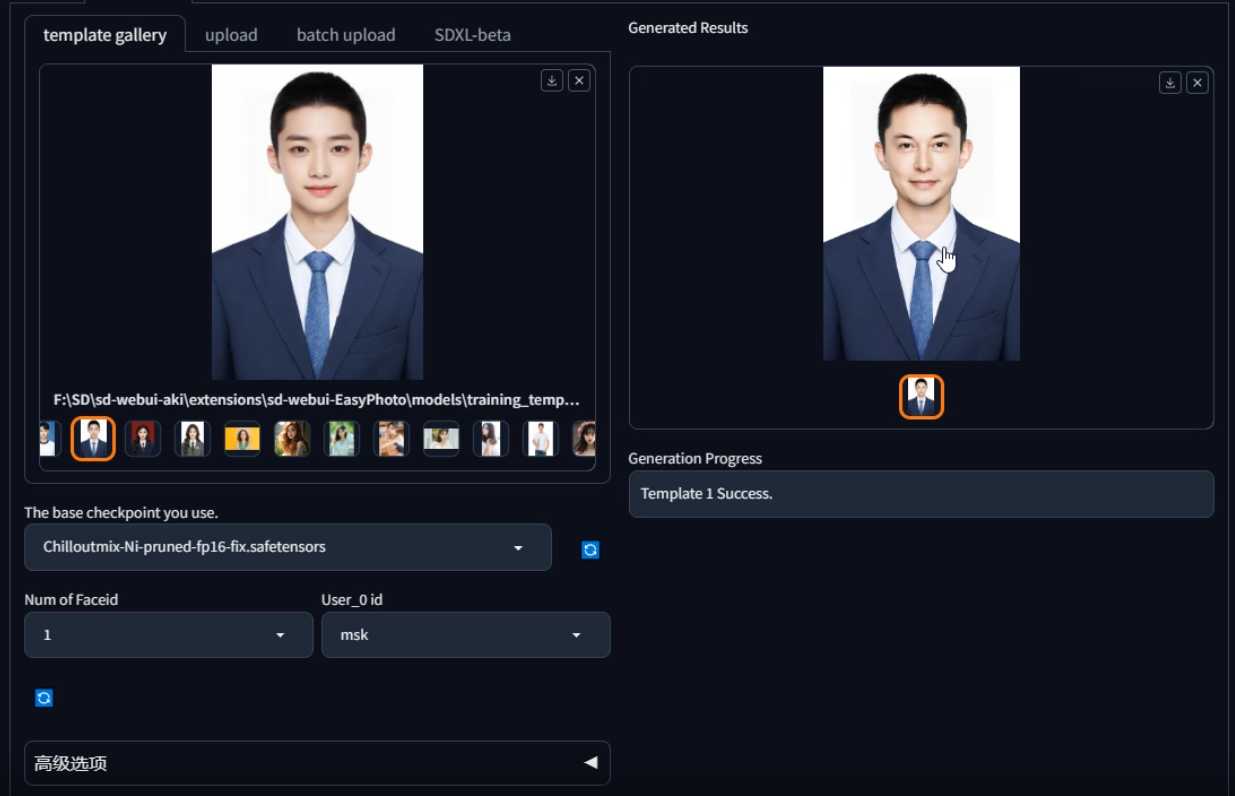
- 在推理标签切换到第二个标签(模板库),选择一个喜欢的模板图像。
- 在下方选定推理使用的模型和用户ID,点击开始生成新的AI证件照。
-
等待一段时间,右侧出现新生成的AI证件照。
- 如果不满意,可以使用自主上传照片功能,拖入通过SD生成的图片,实现更加自然的人脸融合。
Easy Photo的工作原理
- 在训练过程中,Easy Photo会对输入的照片进行人脸检测和定位,然后按比例截取图像,使用显著性检测和皮肤美化模型进行图像处理。
- 推理生成阶段,Easy Photo会对选定的模板图或上传的照片进行人脸检测,并生成用于重绘面部的遮罩。然后进行两次人脸融合和内部重绘,使用OpenPose模型对五官进行作用,确保图像的相似性和稳定性。
- 最后,使用基于StableSR的二次放大,实现高清化的图片输出。
- 使用Easy Photo插件可节省跳转不同插件的步骤,实现简单但高质量的LoRa训练。
- 要更好地使用Easy Photo插件,可以进行针对训练和推理过程的改进:
- 在训练过程中,可以微调参数如训练步数,增加到1200至1500步,以获得更好的效果。
- 如果显存水平在16G以上,可以考虑增大P字大小,进行更多图像的训练,以缩短训练时间。
- 在推理生成过程中,可以尝试更换模板图或修改上传照片,以提高生成照片的相似度。
- 还可以尝试不同的皮肤美化模型和显著性检测模型,以获得更理想的图片效果。
- 需要注意的是,在使用过程中可能会遇到生成照片不像本人或面部融合有一些小问题的情况,需要不断尝试和调整参数来优化结果。
它把很多传统的练丹流程里的操作步骤通过非常智能化的手段实现了,从而确保了一个简单但却高质量的LoRa训练,而让它产出图片的过程也融合了多种不同技术,形成了一个完整的工作流,也节约了你在各种不同的插件之间反复横跳的功夫。从技术角度来看,它让在SD里产出人像图片训练LoRa变得更easy了。
–
– 针对训练的优化是为了调整训练过程中的各种参数,以提高训练效果。
– 默认的参数设置通常能够实现不错的训练效果。
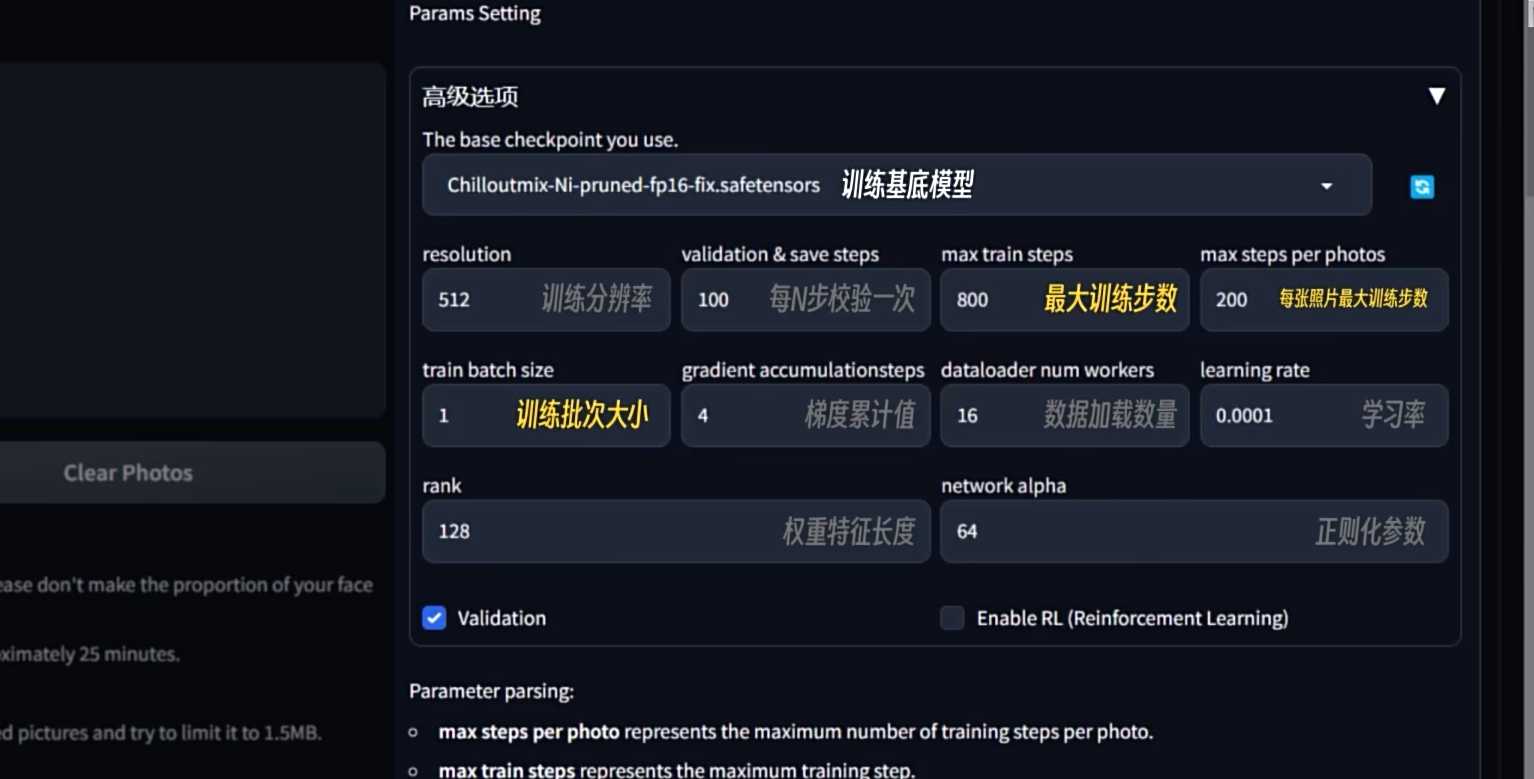
针对训练的参数调整:
- 样本分辨率、叠代保存次数、训练的步数、批次大小、学习率等等是需要调整的参数。
- 大多数情况下,保持默认参数即可。
- 可以尝试微调以下几个参数以提高训练效果:
### 训练步数:
– 默认情况下,一张照片最大训练200次。
– 设置最大训练步数时,EC Photo会在达到最小值时停止训练。
– 提高训练步数可以增加训练水平,一般建议将步数提高到1200到1500步左右。
– 通过调节最大训练步数和单张图片最大训练步数,让模型练多几步再停止。
### 显存水平及- 批次大小:
– 批次大小指每次更新模型时使用的样本数量。
– 可以尝试调整批次大小以优化训练效果。
– 较大的批次大小可以加快训练速度,但可能会增加内存消耗。
– 16G及以上显卡,可以考虑将批次大小增大到2到4之间,以在同一批次里进行更多图像的训练,从而缩短训练时间。
Easy Photo参数影响因素
如果你想更全面地了解EasyPhoto里的每一个参数影响的因素,在这里我也为你附上一张参数含义的表格。这些和Lora训练相关的参数还是挺有趣的,如果你期待一期关于它们的更为深入的讲解,可以在弹幕里敲个6,下单预订一下。
训练样本的重要性
比起参数,我认为更重要的是你输入给EasyPhoto的照片,也就是我们常说的训练样本。首先,数量多少并不绝对影响训练成果。在一开始上传照片时,并不是说你塞三四十张进去,效果就一定会比十张要更好。相反,过多的样本有时候还会干扰AI的学习,让Lora难以稳定发挥。相比之下,样本质量才是最重要的。
好的训练样本特点
什么样的照片才是好的样本呢?
– 第一,人的脸在画面中的占比应该尽可能大,至少是半身照、自拍照,尽量不要挑这种人很小的游客照,也不要挑这种脸部完整的自拍照。
– 第二,多张照片里最好包括不同角度、表情的人像,如果人物戴眼镜,那不戴眼镜的也要有。
– 其他一些基本的要求,比如照片要清晰、光线要良好,就不说了。尽量不要披铺那些PS美颜的痕迹,会让AI拿捏不准你真实的模样,很容易让训练的结果不像。
自己拍摄照片的优势
其实你也不要有太大的压力,如果是给自己定制一套Easy Photo,你完全可以像我一样,现场拍摄。找个不至于太乱的背景,人像画面的比例适中,转半圈、抬头、低一头,不同的角度都拍到。经过了实际测试,这一套照片训练出来的效果,比我之前所有搜集照片练出来的效果,在还原度和细节上都要更好。
选择底模的技巧
选择底模其实也有一定的讲究,为了保证Lora的泛用性,我比较推荐你使用一些泛化能力强,且人像风格多元化的底模。比如SD的历代观模,或者Realistic Vision,这样练出来的模型,在任何一个大模型上去推理,都会比较和谐融洽。如果你常常使用某一个微条幅模型,生成特定风格的图片,也可以用它训练,但可能会造成比较脸谱化的偏差。比如这次我用擅长亚洲女性人像的Magic Realistic,练了一个我的Laura,就是会有那么一股……我不说了,你们把评价发在弹幕上吧。
推理参数和高级选项
在推理方面,也有很多我们可以去操作的空间。除了选模型选人物以外,下面还有一系列你可以展开的高级选项。在这个提示词框里,你可以额外输入一系列用于面部宠惠的提示词,这是影响效果的关键之一。默认情况下,他准备的提示词是Masterpiece Beauty,但其实你可以写更多,比如一些通用的,用于优化人像镜照的提示词模板。另外,如果你的写真主人是男生,Beauty容易让人带有女性化的性质,这个时候可以把它换成One Boy, One Man, Handsome,Male Focus之类的提示词。你还可以加入一些五官神态特征,它在一定程度上可以更好地帮助你还原你想要的人物特质。但你不用一开始就写特别多,先使用简单的提示词做尝试,在效果不好的情况下再把提示词作为一种调整手段。
高级参数和附加功能
下面同样有一系列可以调控的高级参数。和推理参数一样,我不会建议你一个个的去琢磨,因为这也不符合那种Easy的感觉。最下方的一系列复选框控制了一些核心功能的开关,一般我都会建议你全部勾选。如果你对图像分辨率的要求不高,取消勾选最后一个超分的选项可以节约掉最后使用Stable SR放大的这部分时间。上方的滑块控制的是在刚才我们提到的那个两次融合的绘制过程中面部的融合方式。你可以通过这些参数调节控制AI生成的人像细节,不过它们的影响是非常细微的,比如这个用于控制写真是否相像的人脸融合比例,在最大值与最小值上的差异其实并不大,所以只有当效果不尽人意的时候我才建议你到这里面找一些解决方案。最下面的两个附加功能其实非常有意思,这个展示面部相似度得分会在生成后附上一张样本来源,你可以很清晰地看到它是学习了你上传的哪一张图片,也揭示了推理过程中进行面部匹配的这一流程,对你挑选去的样本也会有一定的启示意义。旁边的背景还原则控制了是否会对背景进行重绘,你可以试着将它开启并拉大背景重绘幅度,然后在上方额外提示字中加入针对背景的描述,看,你就会在人脸重绘的同时自然地实现背景切换了。
底图选择和自定义
在生成一张AI写真的过程中我们输入的底图也是相当重要的,Easy Photo提供的底图模板其实覆盖的还蛮全面的,但多数时候你肯定还是更想用自己跑出来的图上传制作写真。关于生成高质量人像照片的方法在之前的教程里我们已经分享了很多了,所以在这里我就补充几组针对不同写真风格的标准化提示字。你可以在这期视频的简介资料里下载到对应的原图与提示字组合并一键应用到WebUI里。而如果你想像模板图里一样生成一些特定形式的照片,那融入一些风格Lora会有不错的帮助,比如证件照、胶片风、拍立得的Lora。感兴趣可以在初度这一步充分尝试一下。这里面还有一个小关键,就是我们一开始提到的一定要通过提示词等手段的控制预先生成发型、脸型和本人相像的图片。因为EasyPhoto目前阶段的融合是仅限于五官范围的,而我们去看一个写真作品像不像发型、脸型甚至身型都会是重要的考量因素,所以做好这一点会有助于建立起个个人形象的识别。而为了帮助你更好地做到这一点,我同样会总理系列用于描述这些外貌特征的提示词,你可以写个图保存一下,需要时拿出来参考。
影响训练和推理效果的因素
总结下来,上述的每一个环节都可能会对训练和推理的最终效果构成影响,而每个人对于写真的要求也是不一样的。所以,我无法为你总结出一个绝对正确的方法,但会希望以上的讲解能帮你把里面的规律讲明白,从而可以根据自己的需求不断做改进。在做LoRa训练生成图片的时候,大家也一般都是在反复的上市中逼近正确答案。好在,EZ Photo的训练持续时间并不长,官方测试按照默认的800步进行训练,大概需要25分钟来训练好一个用户LoRa,而在我的电脑上大概8分钟左右就能出一炉。如果你体验过了EasyPhoto,你可以把你的设备情况和训练所需的时长发在弹幕和评论里给更多后面的朋友提供参考。我自己在本地训练LoRa的时候也碰到过不少问题,比如训练的显存占用高,负担大,如果设备比较一般,训练期间除了看着定多条慢慢爬,基本什么都做不了。而模型训练耗时往往也比较长,在真实的LoRa训练中学习部署更多,要求更高的情况下,可能要三四个小时,甚至一整晚才能烧出一炉。虽然说LoRa训练的门槛低,但如果你的显存太低,可能连启动都启动不了。如果你在本地使用EZ Photo训练,推理时碰到了类似的障碍,也可以考虑出一些云平台的帮助。
在线部署应用的方式
目前,Easy Photo的开发者官方提供了三种不同的在线部署应用的方式,分别是阿里云的Pi DSW,OTO DL,Docker。你可以参考项目主页里的指引进行镜像部署。这三种途径里,着重聊聊我用过的Pi DSW的体验。作为国内领先的云计算平台,阿里云为广大用户提供了充足的可免费白嫖的计算资源,支持超过300个小时的计算训练,帮助你克服算力门槛。这些试用资源是每天限额发放的,如果需要,可以点击视频下面的链接快速跳转到试用中心进行利用。领取完了以后,就可以通过它租用GPU实例进行训练推理了。如果你想借助它在线开启Easy Photo的试用,可以在DSW Gallery中搜索Easy Photo,将这个Notebook在实例中打开,就可以一键配置包含Easy Photo的插线和完整环境的SE WebUI了。它的资源使用弹性灵活,不用时会自动预计停机,避免产生额外的扣费。除了Easy Photo这种简易的LoRa训练以外,DSW还支持完整部署WebUI以及LoRa训练以外。无论是想云端链单还是在线速度作画,都可以通过它加入了一个图像批处理的功能。切换到推理界面的这个批量上传标签,你可以自行选中多张照片上传,按上面的方式设置好参数,模型,就可以让它批量产出同一个主人的一系列照片。只需要不到10分钟的时间就拍好了这样一套高质量的AI写真集,真的非常方便了。同时,它还支持了多人写真的面部融合,导入有多张人脸的照片后,在下方定义面部数量,再给每个人脸选择就可以做出像这样的多人合照了。
很多SD用的不多的朋友,可能在做底图这一步上就会碰到困难,但也不用担心,本着让照片变得越来越easy的思路,它在这个月还加入了一个新的功能,就是基于SDXL实现的底图快捷生成,这个功能彻底打通了从生成到产出的整个完成流程。利用它生成照片前,你需要先下载一个大约7G左右的SDXL微调模型来支持生成。相比起我们诸多常用的1.5、2.1版本的老模型,SDXL在图像生成的精细度、真实感、提示词忠实度和准确性上都有显著的提高,因而非常适合用来生成照片。切换到最右边这个SDXL BETA的功能标签以后
在这之后,会有一系列可选项,可以以非常可控、可选择的方式帮助你定义人物的性别、姿势、穿着、场景,甚至是季节和时间。只需要简单地选择几个选项,然后像之前一样加载模型和用户ID。
提醒:选择正确的性别和风格
如果你想生成男生人像,除了更改性别选项,还要将右边的Close尽量改成男性风格,否则可能会出现尴尬的场面。
面部融合替换
在这个流程中,我们可以认为是使用XL模型生成了底图,然后利用之前的流程实现了面部融合替换。所以你可以根据喜好选择底模。但请注意,建议拥有16G以上的显存来承担这个压力。
云服务平台上的运行
如果你打算在云服务平台上运行Easy Photo,请选择具有大显存的GPU,比如阿里云的派平台上可以免费试用的A10专业计算卡,它的24G显存可以让你愉快地体验这个功能。即使显存不达标,你仍然可以自由地使用Easy Photo的基本功能。
扩展插件的多样应用
这个插件的使用不仅仅限于生成真实的写真照片。例如,使用2.5D风格的模型,在人脸融合这一步选择对应风格的模型,就可以创作出更具想象力的画面。再结合Stable Diffusion中的其他工作手段,你可以最大程度发挥它的潜力。比如,在上传满满之前,你可以利用Open Post Editor自由定义人物的姿势和动作。而在输出图片后,还可以通过Tile Diffusion的扩展进行高清消分,实现真正的摄影大片效果。
© 版权声明
文章版权归作者所有,未经允许请勿转载。