Text-Embedding-3-Large是什么模型?怎么使用?
一月份,OpenAI发布了两种新的嵌入模型:text-embedding-3-small和text-embedding-3-large。这些模型采用套娃表示学习技术(MRL:Matryoshka Representation Learning)进行训练,这使得开发者可以在嵌入中权衡性能和成本。 该模型旨在通过将多个独立的模型合并为一个新的模型,提供统一的文本处理能力。具体来说,OpenAI通过整合文本相似性、文本搜索-查询、文本搜索-文档、代码搜索-文本和代码搜索-代码这五个独立的模型,实现了在文本搜索、句子相似性和代码搜索等不同任务上的综合性能提升。
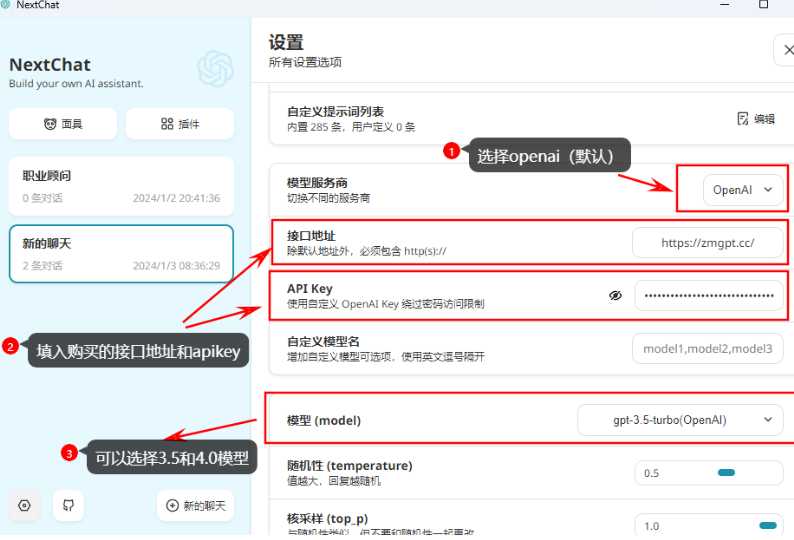
在实际应用中,例如在LangChain-chatchat和fastgpt等项目中,可以通过添加OpenAI的text-embedding-3-large模型来提高文本嵌入的效果,分享代码和实验结果
text-embedding-3-large的每1k token售价为0.00013美元。这可以转换为每1M tokens的价格,即0.13美元/1M tokens。使用些模型可到zmgpt.cc使用,注册送0.5美金。
什么是套娃表示学习?
套娃表示学习是一种用于训练嵌入模型的技术。它允许在牺牲少量准确性的情况下换取更小的嵌入尺寸。因此,可以以更低的成本存储更多的信息,并更快地搜索它。
嵌入通过从序列末尾移除维度,并且只使用嵌入向量的子集维度来缩短。例如,你可以只使用原本具有1536维度向量的前8、16、32等维度(或任何其他维度的切片)。
与常见的向量嵌入不同,其中所有维度都同等重要,在套娃嵌入中,向量前面的维度存储的信息比后面的维度更多,后者只是添加了更多细节。可以通过尝试在多个分辨率下对图像进行分类的类比来理解这一点:较低的分辨率提供了更多高层次的信息,而较高的分辨率则添加了更多细节。
因此,检索性能随着表示大小的增加而提高。然而,OpenAI报告说,text-embedding-3-large嵌入可以缩短到256的大小,同时在MTEB基准测试上仍然优于未缩短的、大小为1536的text-embedding-ada-002嵌入。
套娃嵌入的表示大小与检索性能

MRL(Matryoshka Representation Learning,套娃表示学习)实现的魔力全部在于训练这些模型时优化的损失函数!如果之前损失函数是L,对于MRL,将损失函数分解为各个向量维度范围上的损失之和:Loss_Total \= L(upto 8d) + L(upto 16d) + L(upto 32d) + … + L(upto 2048d)。有了这个新的嵌套损失函数,模型就有动力在向量的每个子部分捕捉信息。
修改损失函数后,可以免费获得这些可截断的向量,无需任何额外成本——这几乎适用于所有损失函数,并且可以对现有的预训练模型进行微调以输出MRL向量!这意味着MRL非常容易采用并应用于预训练模型。
Text-Embedding-3-Large的作用
统一文本处理能力
Text-Embedding-3-Large模型的一个显著特点是其统一的能力。它能够处理多种文本相关的任务,如文本相似性搜索、文档检索等。这种统一性使得模型能够在不同的应用场景下提供一致的表现,无需针对特定任务选择不同的模型。这些模型采用套娃表示学习技术(MRL:Matryoshka Representation Learning)进行训练,这使得开发者可以在嵌入中权衡性能和成本。
支持长文档处理
模型的上下文长度设置为8192,这意味着它能够有效地处理长文档。在处理包含大量信息的文档时,这一点尤为重要,因为它可以确保模型能够捕捉到文档的整体意义,而不仅仅是局部信息。
提供高效的检索性能
在检索任务中,Text-Embedding-3-Large模型能够根据问题的embedding表示,在向量数据库中检索出相似的本地知识文本片段。这一特性对于构建知识库问答系统等应用具有重要意义,可以帮助用户快速找到相关的信息。
可缩放的嵌入技术
此外,Text-Embedding-3-Large模型还支持嵌入维度的缩放。这意味着开发者可以通过在dimensions API参数中传递嵌入,在不损失概念表征属性的情况下缩短嵌入。这种技术允许用户在牺牲一些准确性的前提下,换取更小的向量大小,从而提高计算效率。
综上所述,Text-Embedding-3-Large模型是一个功能强大且灵活的工具,适用于多种文本处理任务,特别是在需要处理长文档和进行高效检索的场景中表现突出。它的统一能力和可缩放的嵌入技术为用户提供了多样化的选择,以适应不同的需求和资源限制。
© 版权声明
文章版权归作者所有,未经允许请勿转载。