
Seko
Seko是一个前沿的AI视频生成平台,将您的创意转化为令人惊叹的专业视频。利用先进的AI技术创建、编辑和定制视频。加入全球数千名创作者的行列。

Vidu是由生数科技联合清华大学在2024年4月27日于中关村论坛未来人工智能先锋论坛上正式发布的。这是中国首个长时长、高一致性、高动态性的视频大模型,标志着在视频大模型领域取得了重大突破。Vidu的发布,是继Sora之后,全球范围内率先取得的显著进展,其性能全面对标国际顶尖水平,并且在加速迭代提升中展现出强大的潜力。
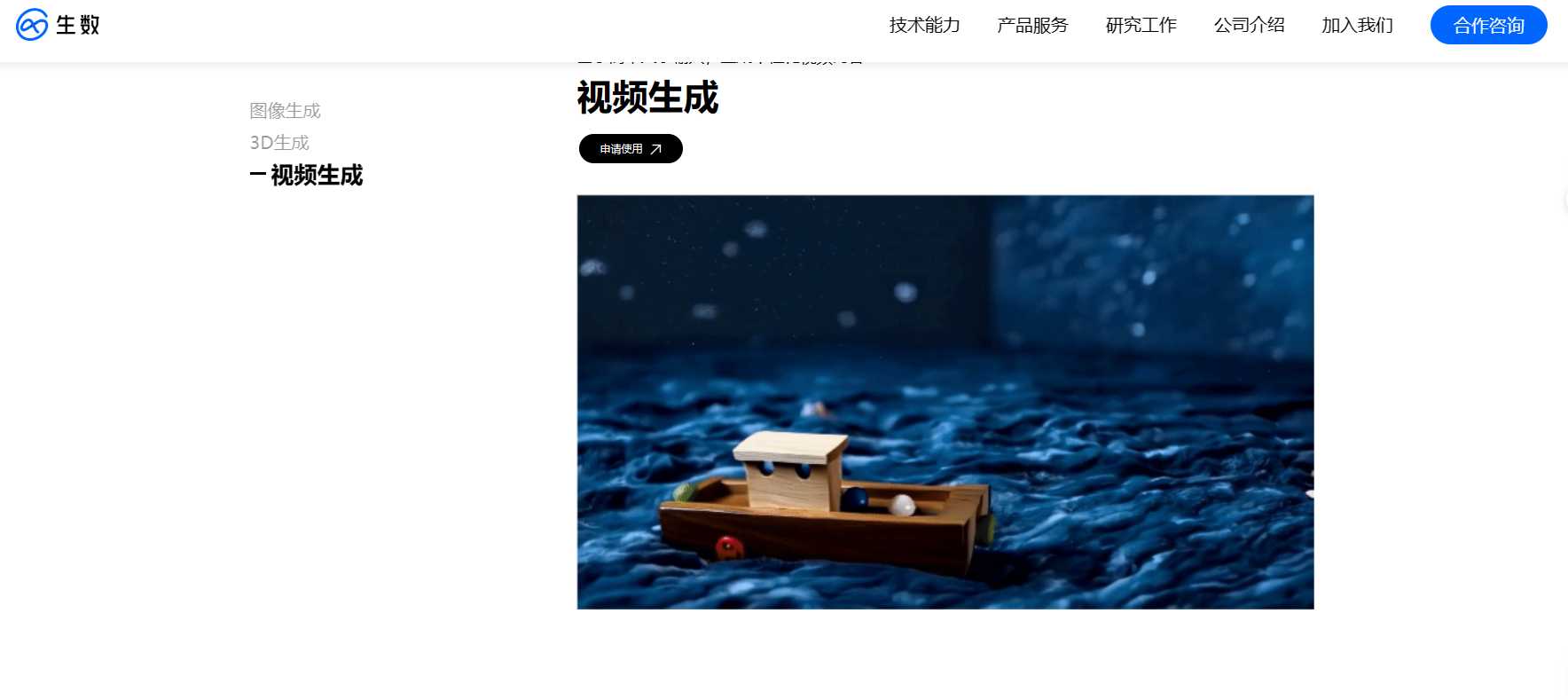
Vidu模型采用了团队原创的Diffusion与Transformer融合的架构U-ViT,支持一键生成长达16秒、分辨率高达1080P的高清视频内容。这一创新性的技术应用,不仅提升了视频生成的质量和效率,也为视频内容创作和编辑提供了新的可能性。
Vidu的快速突破得益于团队在贝叶斯机器学习和多模态大模型的长期积累以及多项原创性成果。其核心技术U-ViT架构由团队于2022年9月提出,早于Sora采用的DiT架构,成为全球首个Diffusion与Transformer融合的架构。
Vidu的发布不仅是技术上的一个重要里程碑,也预示着未来人工智能在视频处理和生成领域的广泛应用和发展前景。
| 事件名称 | 事件时间 | 事件概述 |
|---|---|---|
| 中国首个Sora级视频大模型Vidu发布 | 2024年04月27日 | 生数科技联合清华大学在中关村论坛年会上发布了Vidu。 |
| Vidu模型的技术特点和创新 | 2024年04月27日 | Vidu采用U-ViT架构支持生成高清视频内容,是全球首个重大突破的视频大模型。 |
| Vidu的研发背景和成果 | 不明确(提及时间为2024年) | Vidu源自于团队在贝叶斯机器学习和多模态大模型的长期积累和多项原创性成果。 |
| 组织名称 | 概述 |
|---|---|
| 生数科技 | 科技/人工智能与清华大学联合发布了Vidu。 |
| 清华大学 | 教育/研究机构参与了Vidu的发布。 |
Vidu作为国内首个Sora级别的视频大模型,被媒体和业内人士广泛关注,其对视频处理和生成领域的推动作用不可忽视。
Vidu的发布,对于视频内容创作者和人工智能技术工作者来说,都是一个令人振奋的消息。它不仅展示了中国在视频大模型领域的技术进步,还为相关行业带来了更多的可能性和发展空间。Vidu的应用场景广泛,包括但不限于媒体、娱乐、教育等多个领域。其发布,无疑将加速视频内容的创新和智能化进程。
目标受众:人工智能研究者、视频内容创作者、科技爱好者、教育与媒体行业人士。
使用场景:视频内容创作、视频编辑、教学演示、媒体报道、知识传播等。












