

LatentSync 1.6 深度解析:最强开源数字人工具的再次进化
摘要:LatentSync 1.6 版本是一次重大的核心功能与技术升级,它精准地解决了先前版本中备受关注的 **512x512 分辨率下人脸模糊**、**“嘴瓢”** 和 **“牙糊”** 等问题。通过采用更高分辨率的训练模型和全新的人脸检测技术,新版本在生成视频的 **面部清晰度**、**皮肤纹理** 和 **口型精准度** 上实现了质的飞跃。此外,新增的 **批量处理** 功能和对 **NVIDIA 50系显卡** 的前瞻性支持,极大地提升了工作效率和硬件兼容性。然而,这些显著的提升也带来了更高的硬件门槛,特别是对显存的要求从 8G 提升至 **最低 12-18G**。本文将通过详细的 Q&A 格式,为您全面解析 LatentSync 1.6 的新特性、安装步骤、应用场景,并提供一份客观的总结与思考。
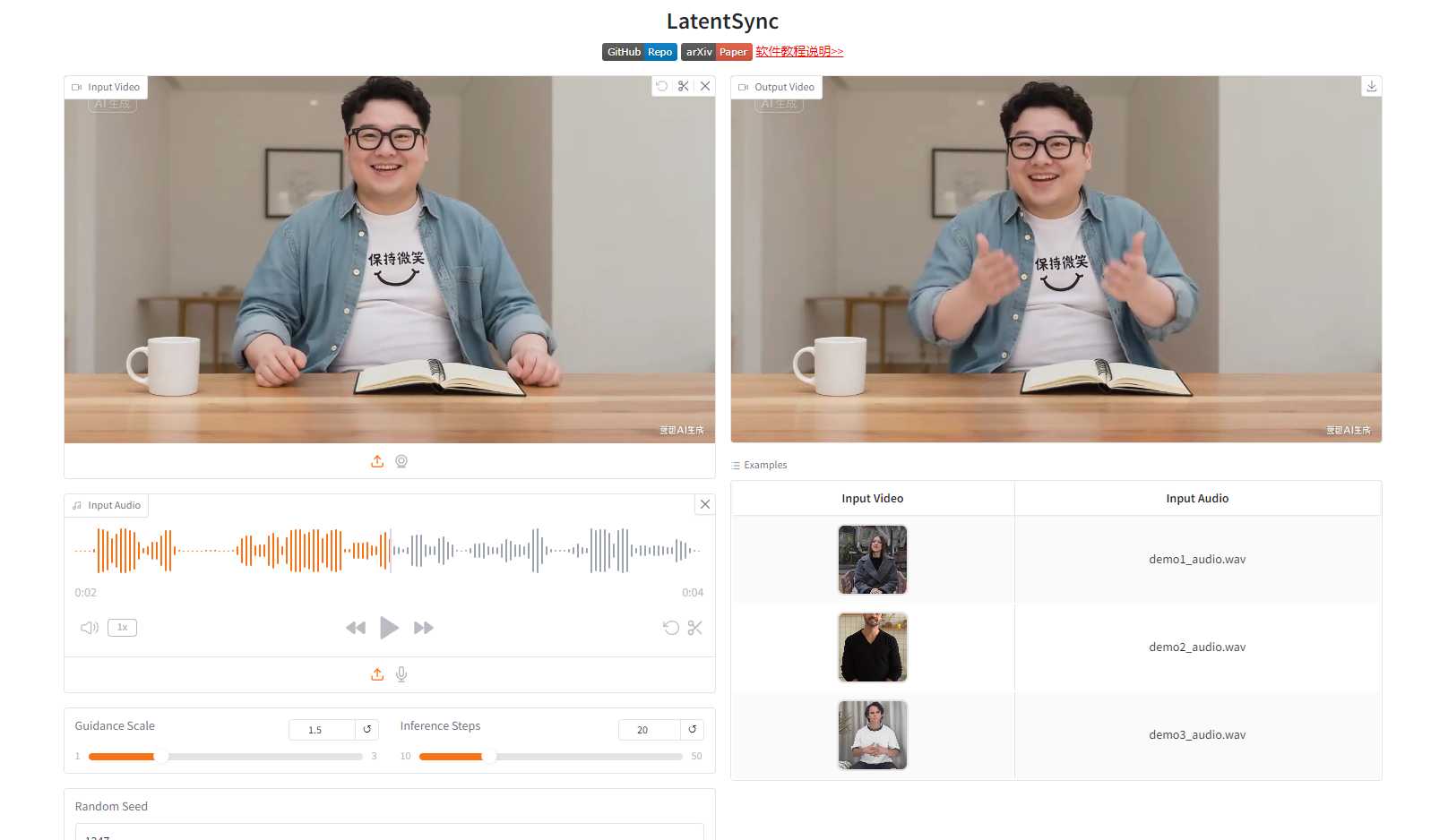
一、核心功能:1.6 版本带来了哪些关键升级?
Q: 针对广为诟病的人脸模糊问题,1.6 版本解决了吗?
A: 解决了,并且效果显著。 此前版本在处理低分辨率素材时,生成的人脸容易出现模糊感。1.6 版本针对性地解决了这个问题:
- 内部处理优化:模型处理人脸的内部尺寸虽然是 512×512,但算法经过大幅改进,即使在低清晰度的源视频中,也能生成非常清晰和自然的脸部细节,例如 **皮肤纹理、毛发细节** 等。
- 光影与匹配提升:除了清晰度,新版本还提升了面部光影的真实感和口型匹配的精准度。
- 高分辨率导出:请注意,512×512 仅为内部处理尺寸,最终视频 **最高支持导出 4K 分辨率**,完全不影响输出质量。
Q: 之前的“嘴瓢”和“牙糊”现象还存在吗?
A: 基本得到修复。 LatentSync 1.6 引入了 **全新的人脸检测模型**,该模型拥有更精准的嘴型区域检测能力。这项技术改进直接解决了此前版本中常见的“嘴瓢”(口型不准)和“牙糊”(牙齿细节模糊不清)的问题,使得最终生成的视频 **口型流畅度** 大幅提升。
Q: 我有很多视频需要处理,效率如何?
A: 效率大幅提升,支持批量处理。 这是 1.6 版本一个非常实用的更新。用户现在可以直接 **将多个视频和音频文件拖拽到处理界面**,软件将自动进行排队和批量化操作,无需再逐一手动处理,极大地节省了时间和精力。
Q: 我的显卡是最新款的,兼容吗?
A: 兼容性更强,已支持 50 系显卡。 1.6 版本在硬件适配上做了前瞻性优化,**新增了对 NVIDIA 50 系显卡的支持**。这表明该工具正在积极跟进最新的硬件发展趋势,为拥有新硬件的用户提供了保障。
二、技术改进:是什么让效果变得更好?
Q: 从技术角度看,视频清晰度提升的根本原因是什么?
A: 根本原因在于训练分辨率的提升。 1.6 版本的核心模型是在 **512×512 分辨率的视频数据** 上进行训练的。相比于之前版本使用的较低分辨率训练数据,这从源头上缓解了生成视频的模糊感,为清晰的面部细节打下了坚实的基础。
Q: 生成的视频会像以前一样出现跳帧或卡顿吗?
A: 时间一致性得到了保证。 1.6 版本延续并优化了 **TREPA(时间表示对齐)技术**。该技术的核心作用是确保生成视频在时间维度上的连贯性和稳定性,有效避免了画面突然跳帧、卡顿或前后帧人物状态不一致的现象。
Q: 我主要用它来做中文内容,效果怎么样?
A: 中文效果进一步增强。 1.5 版本虽然支持中文,但效果有时并不完美。1.6 版本 **特别针对中文口型同步进行了优化**,使得在处理中文音频时,生成的口型更加贴合、自然,改善了之前版本中可能出现的发音与口型错位感。
三、硬件与系统:我需要什么样的电脑才能流畅运行?
Q: 运行 LatentSync 1.6 的最低配置要求是什么?
A: 硬件门槛显著提高,请务必检查您的配置。
- 显卡 (最关键):最低要求 12G 显存,部分用户反馈在某些情况下需要 18G 显存 才能流畅运行。这比 1.5 版本的 8G 显存要求高出不少。强烈建议按高配置准备。
- 操作系统:Windows 10 / 11 64位。
- 内存:16G 或以上。
- CUDA 版本:需要 NVIDIA 显卡,并安装 CUDA 12.1 或更高版本。
- 硬盘空间:整合包解压后约 21.3GB,请确保有足够的剩余空间。
- 重要提示:软件的 **文件路径和文件名中绝对不能包含中文字符**,否则会导致启动失败!
四、使用教程:如何快速上手 LatentSync 1.6 整合包?
Q: 我是新手,如何安装和使用这个工具?
A: 使用“一键整合包”非常简单,无需复杂配置。
- 下载整合包:从社区提供的网盘链接(如夸克网盘)下载最新的 LatentSync 1.6 整合包。
- 解压文件:将下载的压缩包解压到一个 **路径不含中文** 的文件夹中。
- 启动程序:双击运行文件夹内的
一键启动.bat文件,程序会自动加载并打开一个网页操作界面。 - 上传素材:在网页界面中,分别上传你的 **视频素材** (作为驱动的模板) 和 **音频文件** (你希望人物说的内容)。
- 设置分辨率 (可选):根据需要,你可以勾选“提升分辨率”选项,并选择输出 1080p / 2K / 4K。请注意,这会显著增加处理时间。
- 开始生成:点击 **“生成”** 按钮,程序开始处理。你可以在命令行窗口看到实时进度。
- 查看结果:处理完成后,生成的视频会自动保存在整合包根目录下的
temp文件夹中。



