





📢 GPT-SoVITS声音克隆详细教程:从准备到实现
🎯 前期准备工作
在开始声音克隆前,我们需要做好以下准备工作:
- 准备声音素材:
- 需要一段用于克隆的声音素材
- 时长控制在30分钟以内(示例中使用的是1分钟音频)
- 准备AIDI账号:
- 注册一个AIDI账号
- 向账户内充值10元(足够基本使用)
🖥️ 服务器配置与设置
选择合适的GPU服务器
- 进入控制台页面,点击”容器实例“

- 点击”租用新实例“
- 选择GPU规格:
- 不推荐选择4090D(价格高但性能不佳)
- 推荐选择4090或其他显存在24GB以上的GPU型号
- 注意:CUDA版本必须是11.8及以上,否则会报错
选择适合的镜像
- 点击”社区镜像“
- 在列表框中输入”GPT“
- 选择最新的V7.2版本镜像(包含GPT-SoVITS V3)
- 点击”立即创建”
> 重要提醒:使用完毕后务必记得关机,否则系统会持续计费!
🔄 前置数据处理阶段
上传声音文件
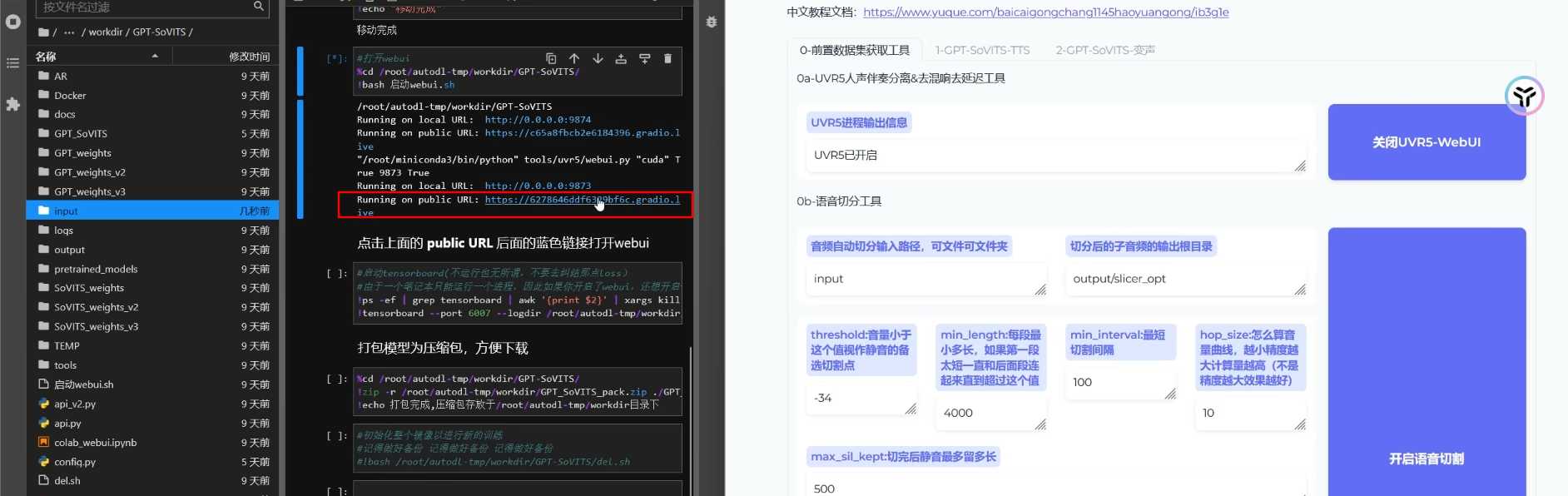
- 点击Jupyter实验室 等待实例加载完成
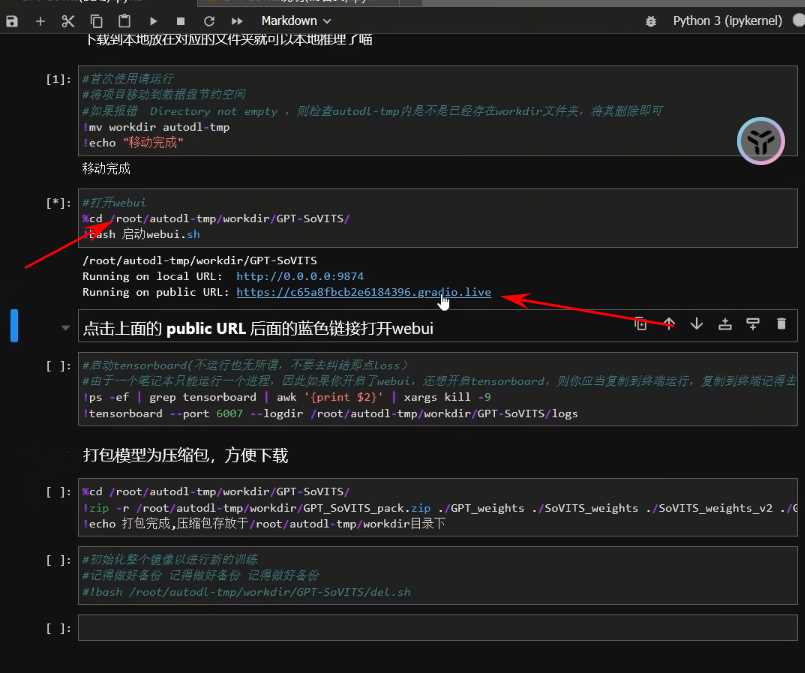
- 滚动到页面下方,选择脚本块并点击”运行“
- 等待显示”移动完成”
- 选择”启动web UI“并运行
- 等待出现两条蓝色链接,选择下面那条
- 打开SoVITS模型所在input文件夹,上传准备好的声音文件
使用UVR5工具提取人声
- 开启UVR5工具,等待启动完成
- 点击蓝色链接进入UVR5工具的Web UI页面
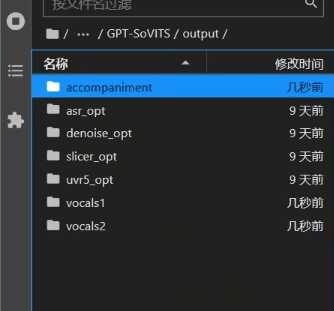
- 在SoVITS模型的输出目录中新建三个文件夹:
- 第一次人声输出文件夹
- 第二次人声输出文件夹
- 伴奏文件夹
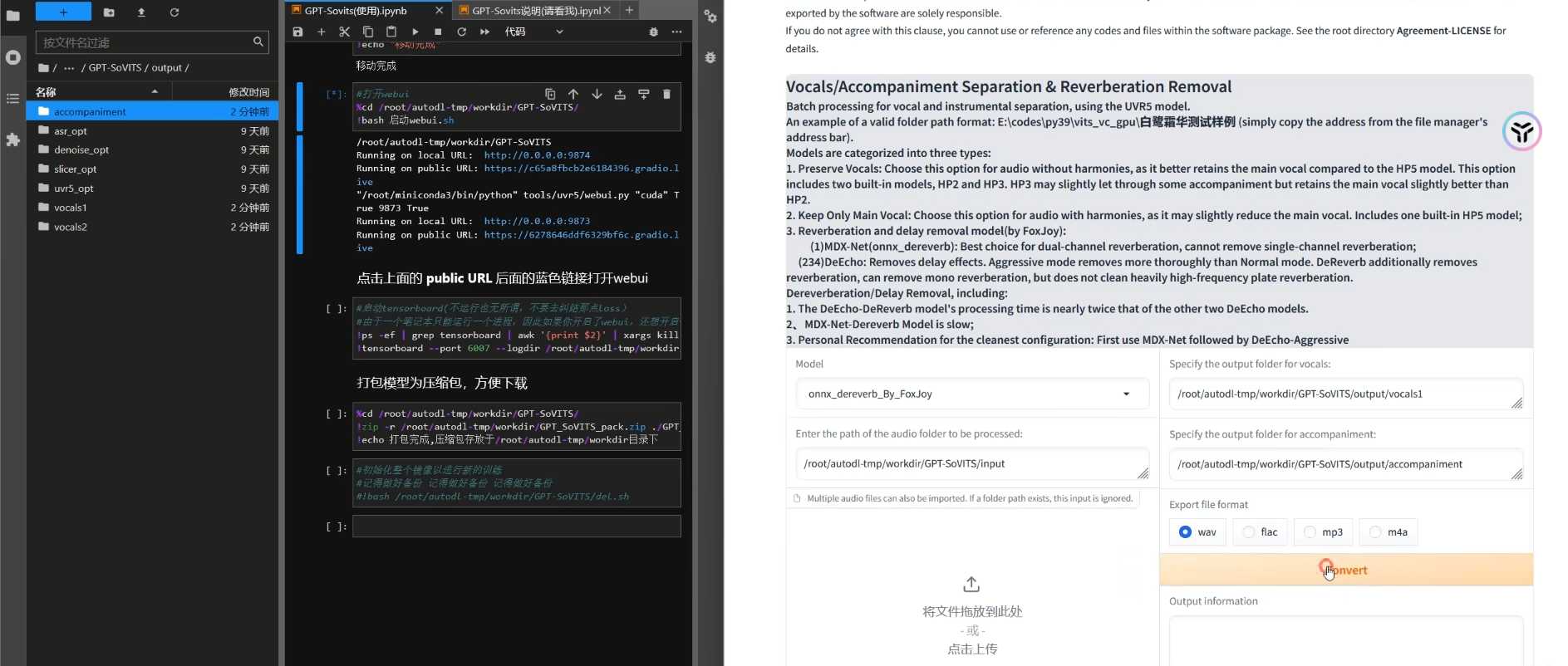
- 官方推荐的三步处理流程:
- 第一次:使用去混响、去延迟模式 onnx_dereverb_By_FoxJoy
- 第二次:使用去混响模式 VR-DeEchoDeReverb
- 第三次:使用去伴奏模式 HP2_all_vocals
- 填入文件路径和保存地址(Linux系统需在路径前添加”/root”)
- 点击”Convert“按钮开始处理
- 完成三次处理后,关闭UVR5 UI页面和工具
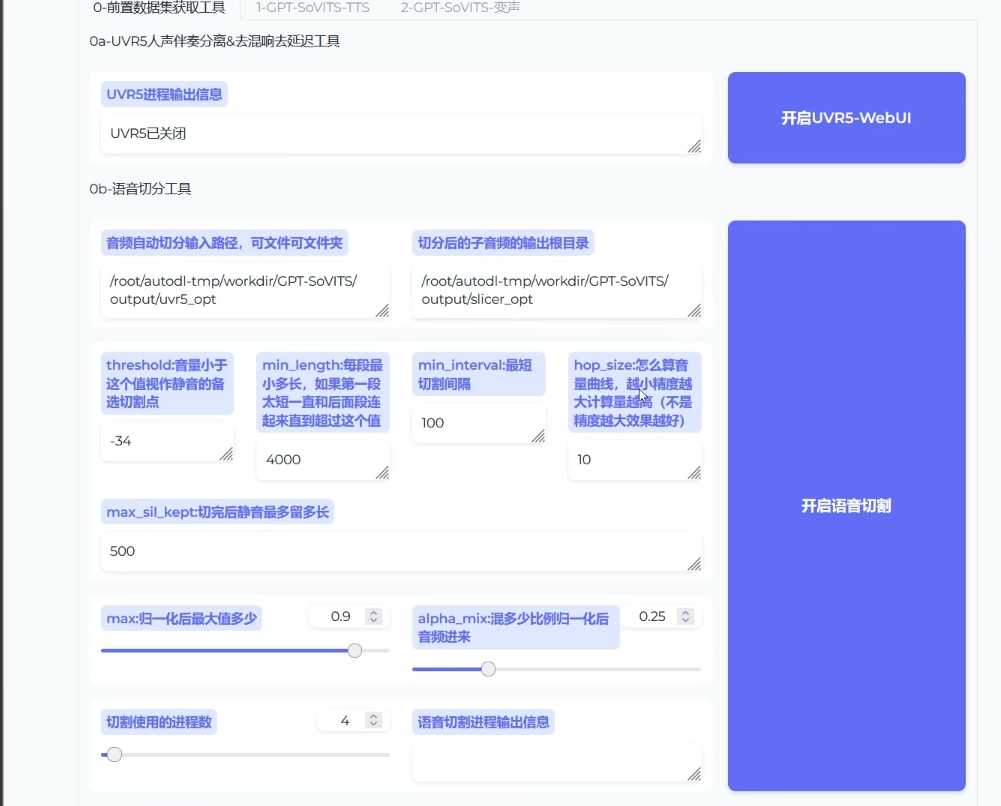
音频切片处理
- 设置切片时长(单位:毫秒),保持默认参数
- 点击”开启语音切割“,等待切片完成
- 不推荐使用语音降噪功能
📝 语音标注与校对
自动标注
- 使用自动标注工具标注切割好的音频
- 保持默认参数,等待自动标注完成
手动校对
- 使用标注校对工具对自动标注的音频进行校对
- 点击蓝色链接进入校对工具UI页面
-
校对流程:
- 播放音频,根据实际内容校对文字
- 需要停顿的地方添加逗号
- 每修改完一条,立即点击”Submit Text“提交文本
- 再点击”Save File“保存文件
- 翻页请点击”NEXT Index“
- 如需删除音频,先勾选音频后面的”Yes“,再点击”Delete Audio“
- 选择几个代表不同语气的音频片段作为样本,下载到本地
- 文件名最好用标注的内容命名(用于后续模型推理)
- 文件名最好用标注的内容命名(用于后续模型推理)
🚀 模型训练
初始训练
- 关闭校对工具UI
- 输入自定义的模型名称和版本
- 选择”V3“版本,其他参数保持默认
- 点击”开启一键三连“开始初训模型
- 等待初训完成
微调训练
- 所有参数保持默认
- 注意训练顺序:必须等SoVITS训练完成再开始训练GPT
- 完成后,模型训练结束
💬 模型推理与使用
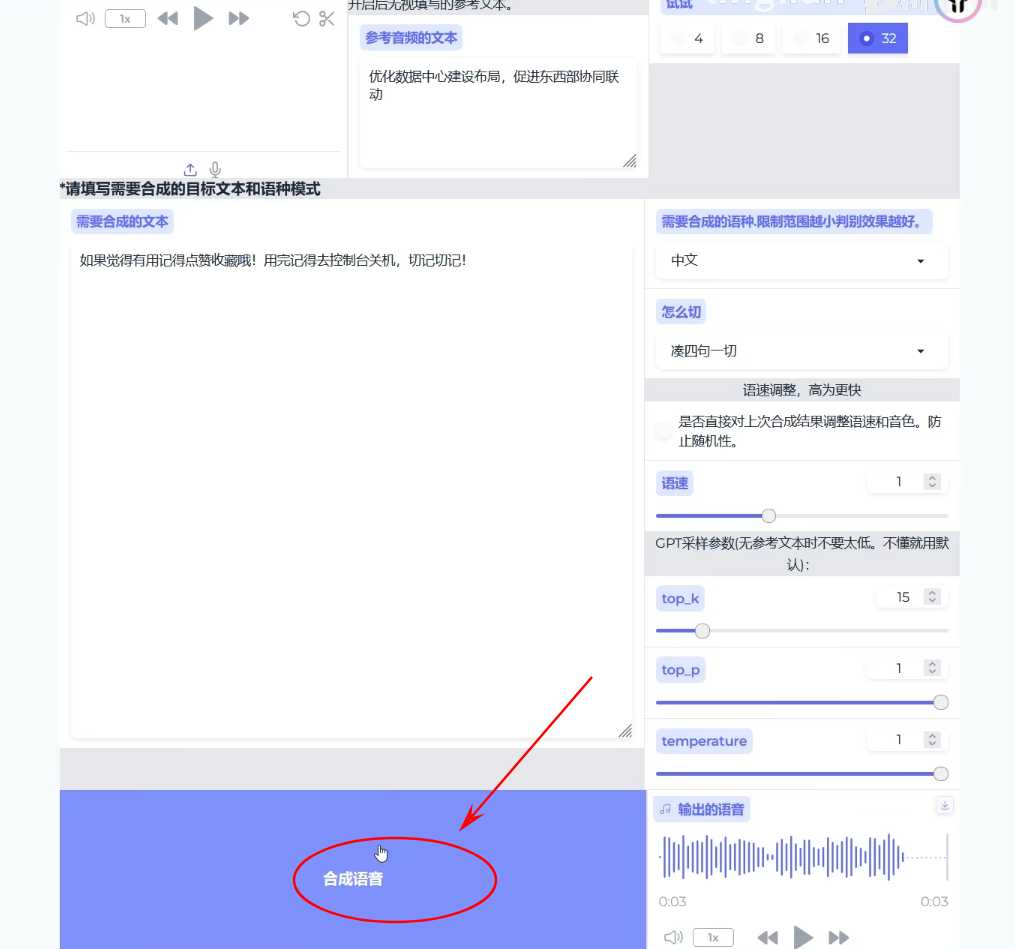
开始推理
- 开启TTS推理Web UI
- 上传保存的音频片段,用于语气参考(如平静、欢乐等)
- 可以尝试不同参数进行推理,找到最适合的效果
实用提示
- 可以尝试不同的参数组合,总有一款适合您的需求
- 重要提醒:使用完毕后记得去控制台关机,避免持续计费
🔍 常见问题与解决方案
- GPU选择问题:CUDA版本必须11.8及以上,显存建议24GB以上
- 音频处理建议:按照官方推荐的三步流程处理,效果最佳
- 训练顺序问题:必须先完成SoVITS训练,再进行GPT训练
我认为:这篇声音克隆教程,看似技术繁复,实则暗藏人性幽微。表面上是教人如何复制声音,骨子里却是对身份认同的一次拷问。声音作为人的第二张脸,如今也能被轻易复制,这不禁让我想起《阿Q正传》中阿Q那可悲的精神胜利法。当技术让我们能够轻易”成为”他人,我们是否也在不知不觉中丧失了自我?这种技术的普及,会不会让我们像鲁镇的看客一样,对真假界限越来越模糊,最终连自己的声音都变得陌生?声音克隆技术的发展,或许正是当代社会身份焦虑的一面照妖镜。
#GPT-SoVITS
© 版权声明
文章版权归作者所有,未经允许请勿转载。