阿里巴巴最新发布的开源多模态视觉大模型Qwen2-VL系列,以超强识别能力引领多模态AI领域。本文将详细介绍Qwen2-VL的特点、优势、应用场景,并指导如何在线及本地部署使用。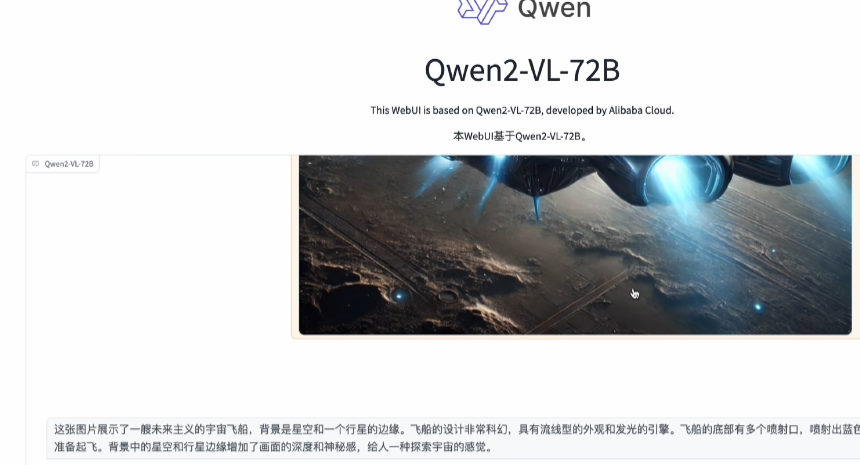
什么是Qwen2-VL?
Qwen2-VL是由阿里巴巴达摩院推出的第二代视觉语言模型,在前代Qwen-VL的基础上实现了多项改进和增强。该模型在多模态处理方面表现出色,拥有20亿、70亿和720亿参数的多个版本。
Qwen2-VL的显著特点和优势有哪些?
- 增强的多模态处理能力:可同时处理文本、图像和视频数据。
- 高级图像和视频理解能力:支持动态分辨率和复杂视觉场景的理解。
- 多语言和多模态支持:支持实时视频分析和多语言文本生成。
- 实时交互和工具集成:支持与外部工具集成,应用于客服和现场工作。
Qwen2-VL应用在哪里?
实时视频分析
Qwen2-VL在视频通话或直播中,能够即时回答用户提出的问题。高效处理视觉内容分析,使其广泛应用在客服、电子商务监控和医疗影像分析等领域。
医学影像识别
通过高质量的医学影像数据集,可对Qwen2-VL进行微调,提高在医学影像识别上的准确率。例如,识别X光片中的骨折位置,并分析CT影像中癌变部位。
如何测试Qwen2-VL的图像识别能力?
Hugging Face平台演示
在Hugging Face平台上测试Qwen2-VL 72B模型的图像识别能力,包括对AI生成宇宙飞船或医学影像的准确识别。以下是一个图像识别的过程:
- 上传图片至Qwen2-VL 72B模型。
- 输入识别图像内容的提示。
- 查看模型分析结果及其准确性。
本地部署流程
使用RTX A6000显卡的Ubuntu系统本地部署70亿参数的Qwen2-VL模型:
- 创建虚拟环境:
- 在终端中输入创建虚拟环境的命令。
- 安装依赖:
- 依次使用命令安装Python 3.11、Transformers等所需库。
- 运行Python脚本:
- 编写并运行脚本代码来加载和应用模型,对图像进行识别和描述。
以下是用于图像识别的Python代码示例:
python
import … # 导入所需的库
模型加载与处理
图像的预处理与生成
感悟
我认为:Qwen2-VL代表了视觉识别领域的一次重大飞跃,其在多模态处理和实时交互中的应用潜力无限。模型的灵活配置和高精准识别能力,使其在医学等专业领域展现出强大价值。对这些先进技术的深入探索将推动AI应用的边界不断扩大。
文中代码:https://blog.stoeng.site/20240831.html
https://www.bmanhua.com/manhua/1508/
© 版权声明
文章版权归作者所有,未经允许请勿转载。