在StableDiffusion如何使用 controlnet模型中预处理器Reference Only 保持角色一致性?

问题背景
在插画创作中,保持角色的一致性是一项耗时的任务,需要考虑表情、服饰、动作、场景等多个因素。以往的方法要么通过图生成图来减少重新绘制的工作量,但会限制整体画面的变化;要么通过保持随机种子一致,但由于AI生成的随机性,稍微改变提示词或参数就会导致完全不同的图片。

解决方案 – Reference Only 的介绍
为了解决这个问题,推出了 Reference Only。轻松生成角色一致的插画曾经需要花费大量时间来构思角色的表情、服饰、动作、场景等,现在只需要学会这个功能,就能完成我们的人物设定,大批量生成同一个人物角色的故事版。这是一个预处理器,不需要任何控制模型,能够直接使用一张图片作为参考来引导生成。这极大地简化了画师们的工作,使他们能够轻松生成一致性的角色插画。

使用步骤
1. 打开 Control Net
- 将之前用灵魂草稿生成的图片拖入 Control Net。
- 点击启用完美像素模式,并允许预览。
- 点击箭头,使生成图像的尺寸与加载的图片尺寸一致。
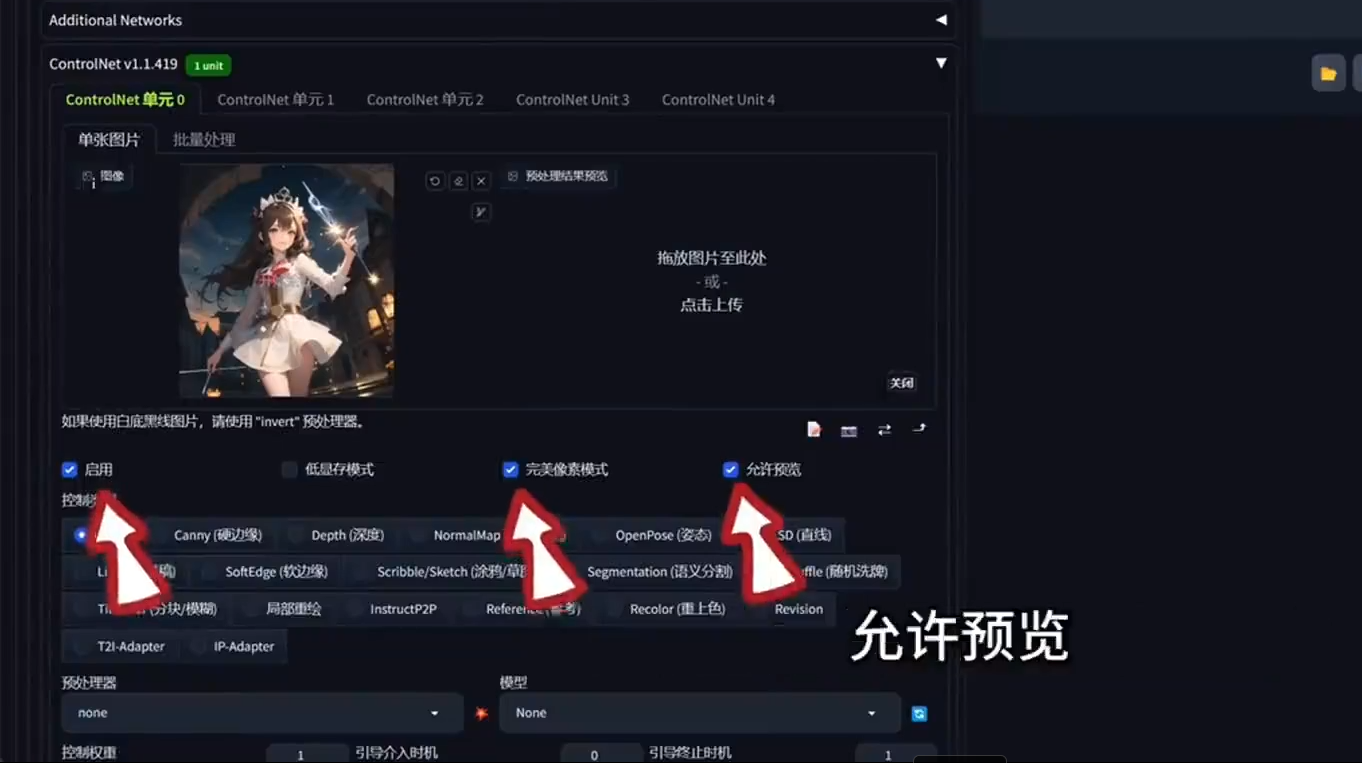
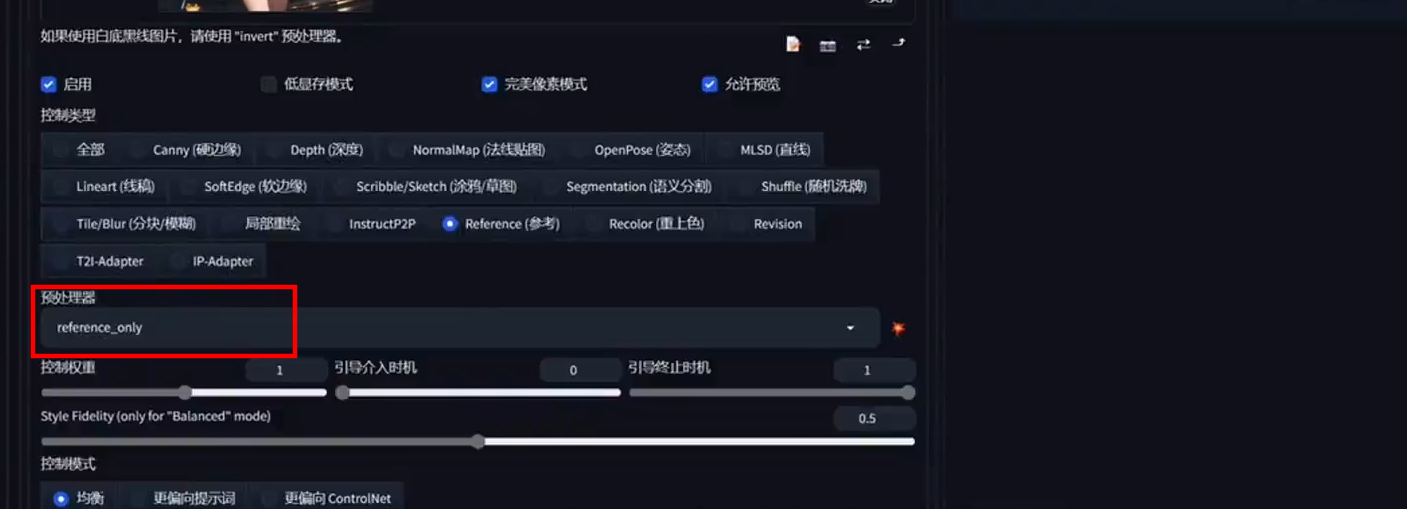
2. 选择 Reference Only 预处理器
- 在控制模式中选择 Reference 预处理器,有三个选项,选择 Reference Only。
- 设置权重、引导介入时机和引导终止时机,默认即可。
3. 选择模型和输入提示词
- 选择模型,如二次元的 Ghost Mix。
- 输入简洁的提示词,如“女孩坐着喝咖啡”。
4. 调整采样参数
- 根据个人喜好选择采样参数,如 DPM ++ SDE Karras。
- 打开修脸插件,如 A detailer
5. 生成图像
- 总批次选4,点击生成,观察生成的图像,可重复尝试不同提示词。
实际体验
通过以上步骤,可以看到生成的角色在面部表情、五官结构、发型、服装等方面尽量与输入的图片相似。通过更改提示词,可以灵活地调整角色设定,解决了人物一致性的难题。


进一步应用
除了基本使用,还可以尝试以下进阶方法:
-
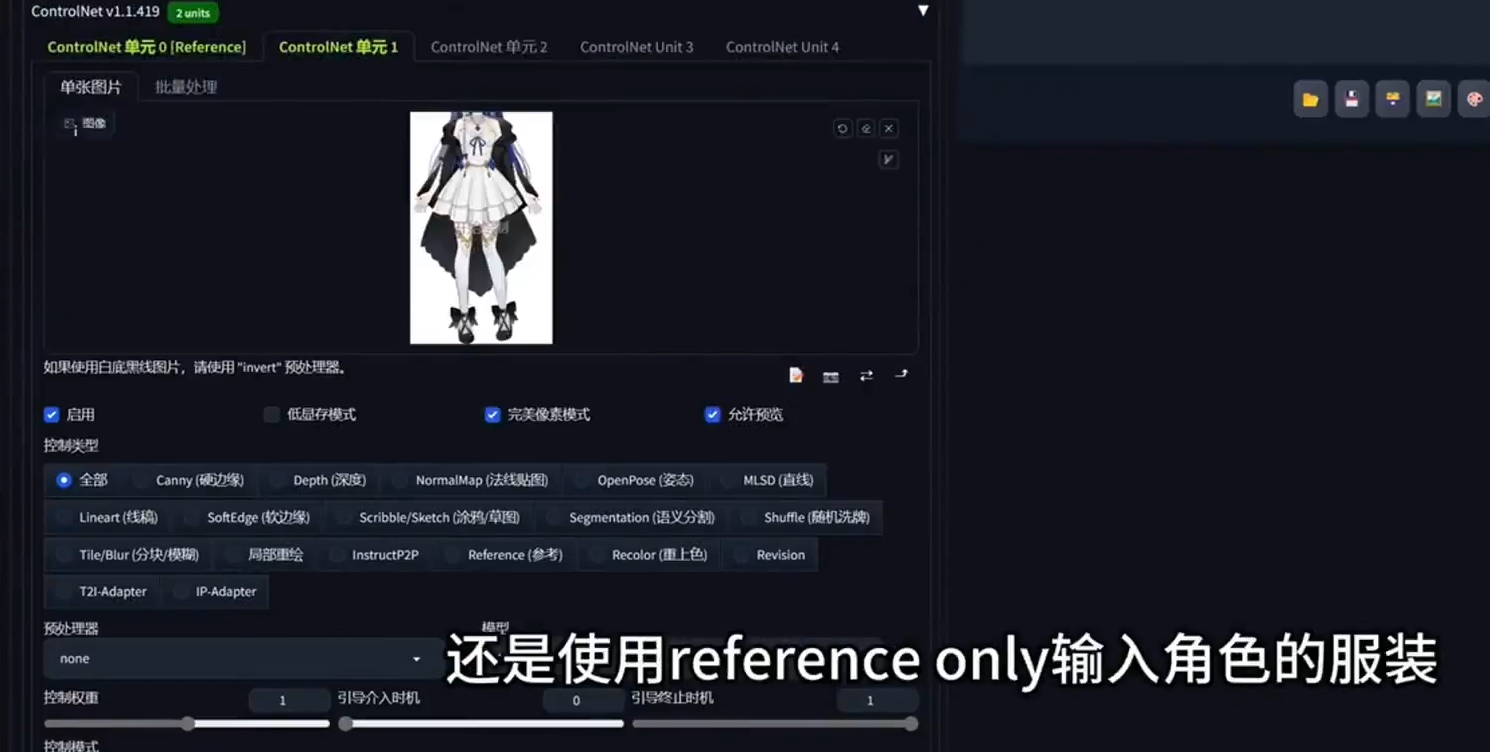
使用多个 Control Net 协同工作,分别控制面部、服装、姿势。
例如开启两个control net,第一个只上传一张头像,第二个上传整个身体。提示词,输入 one girl 和服装的信息,让我们点击生成。就可以实现脸型保持一致,根据提示词衣服来穿不同衣服。

- 尝试不同的模型和预处理器,比较它们的表现差异。


区别 Reference Only 三款预处理器
通过比较 Reference a dain、Reference a Dan + attn 以及 Reference Only 的表现,可以发现它们在颜色风格、人物形象和背景逻辑上存在差异。其中 Reference Only 表现更为稳定,人物形象不会出错,颜色舒适,背景逻辑合理。
总结
Reference Only 的出现极大地简化了角色一致性的问题,为插画创作者提供了更多可能性。通过实际操作,可以发现其在保持人物形象一致性方面的优越性。欢迎在评论区交流讨论,探索更多应用场景。
© 版权声明
文章版权归作者所有,未经允许请勿转载。

相关文章
易之网AIGC导航网站,集AI工具网址、AI绘画、AI教程、AI项目以及AI资讯于一体的AIGC导航网站,用户可以一站式找到有用的AI工具和教程。

