
问题背景
随着LLM(Language Models)的迅猛发展,企业和个人知识库变得越来越流行。但是随之而来的问题有两个:搭建成本高和回答的内容结果不准。
- 搭建成本高:之前有一篇文章介绍了如何使用Dify来简单搭建私人知识库。
- 回答的内容结果不准:知识库的原理很简单,通过加载文件、读取文本、文本分割、文本向量化、问句向量化等步骤来生成回答。回答不准确的原因是因为搜的不准,搜的不准是因为数据集太脏。
数据集结构化的重要性
为了解决回答结果不准确的问题,需要进行数据集的结构化。数据集的结构化一般有两种方式:树形结构和问答对结构。
- 树形结构适合超大型书籍或层级知识,可以参考腾讯的ChatGPT搭建代码知识库文章。
- 问答对结构是指将大段的文本转换成一个个的问答对数据集。当有问题时,大模型可以直接匹配对应的问答对,提高准确性。
大白话说,就是根据你的问题,去根据的你问题,去被切成N多块的文本块里,挨个搜索,找到一个或几个最相关的拿过来给大模型,让大模型根据这些搜出来的文本块作答。
而答得不准的原因,当然就是搜的不准。
搜的不准的原因,就是数据集太脏了。
无脑用GPT整理结构化数据集
为了降低整理数据集的工作量,可以使用GPT来自动生成问答对。
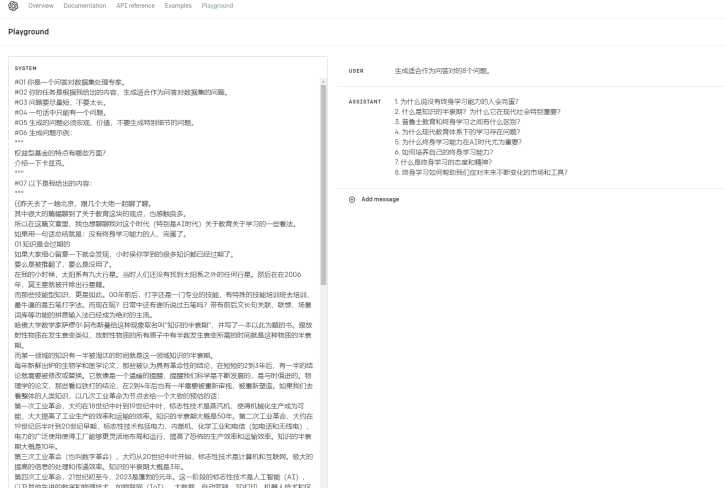
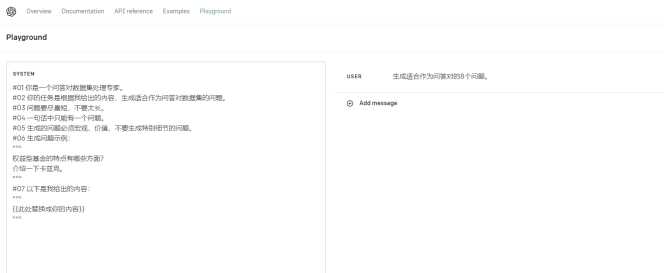
- 先让GPT根据文档生成适合问答对的问题。
– 在OpenAI的Playground中选择16K模型,将温度调到0.8,最大输出设为最大值。https://platform.openai.com/playground
– 在System中使用以下Prompt:
你是一个问答对数据集处理专家。
你的任务是根据我给出的内容,生成适合作为问答对数据集的问题。
问题要尽量短,不要太长。
一句话中只能有一个问题。
生成的问题必须宏观、价值,不要生成特别细节的问题。
生成问题示例:
"""
权益型基金的特点有哪些方面?
介绍一下卡兹克。
"""
以下是我给出的内容:
"""
{{此处替换成你的内容}}
"""
**[](https://www.yizz.cn/wp-content/uploads/2023/11/wp_editor_md_a61e013e1073f8b3fd614e473dfe430d.jpg)**
- 在下面的输入框中替换”{{此处替换成你的内容}}”部分,然后运行GPT生成问题。
- 根据生成的问题和原始内容,生成对应的问答对。
– 打开一个新的Playground窗口,配置与第一步相同的参数。
– 在System中使用以下Prompt:
你是一个问答对数据集处理专家。
你的任务是根据我的问题和我给出的内容,生成对应的问答对。
答案要全面,多使用我的信息,内容要更丰富。
你必须根据我的问答对示例格式来生成:
"""
{"content": "基金分类有哪些", "summary": "根据不同标准,可以将证券投资基金划分为不同的种类:......"}
...
"""
我的问题如下:
"""
{{此处替换成你上一步生成的问题}}
"""
我的内容如下:
"""
{{此处替换成你的内容}}
"""
- 将上一步生成的问题复制到” 我的问题如下:”部分,将原始内容复制到” 我的内容如下:”部分。
- 在输入框中随便写一句”拼成问答对”的话,然后运行GPT生成问答对。
- 将生成的问答对保存到txt文件中,可以作为数据集灌给Dify或Langchain-ChatGLM等工具使用。

通过上述步骤,可以无脑使用GPT来整理结构化数据集,省去手动整理的麻烦。希望这种方法能够提高大家的工作效率,让大家能够处理更有趣的事情。
© 版权声明
文章版权归作者所有,未经允许请勿转载。