SD整体结构
1. 总览
SD的整体结构类似于一个文生图,有三个模型组成。输入包括文本编码器clib,一个生成模型UNET和vae解码器。
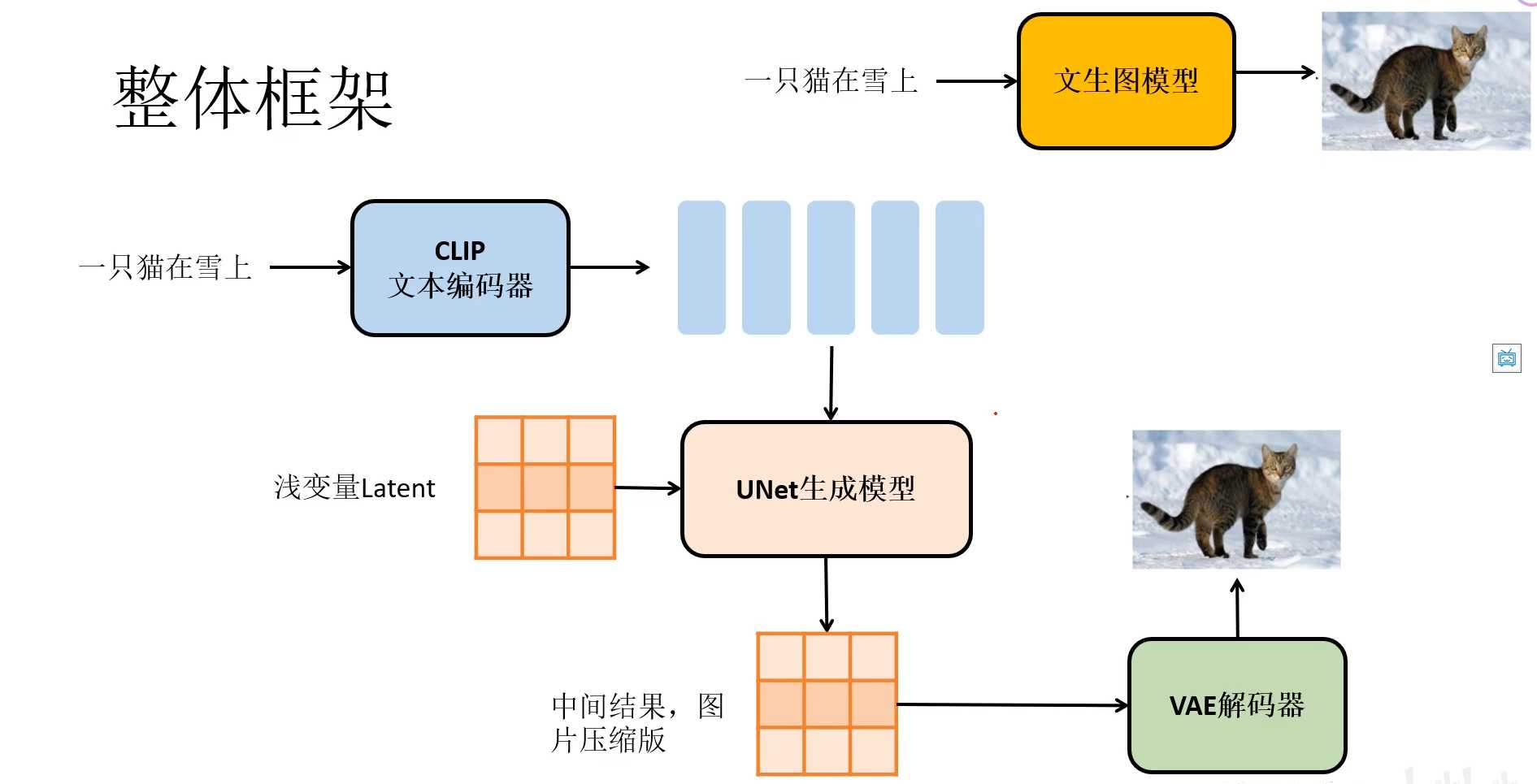
2. 图像的生成过程
- 文本编码器(clip):将输入的文本编码成向量表示。生成向量之后交给Unet。
- 生成模型(unet):接收文本编码器的输出向量和浅变量(LATENT)(控制生成随机性),生成中间结果图片,这个也是带有噪声的图像,可以理解为输出图像的压缩版。。
- 解码器(VAE):用于降噪和还原图片。把压缩版的图像给还原出来。
3. 总体操作流程
- 文本编码器接收文本输入,并将其编码为向量。
- 向生成模型unet提供文本编码器的输出向量和浅变量(随机噪声),生成一张中间结果的图片。
- 使用变分自编码器VE来处理中间结果图片,进行降噪操作。VE还能从噪声中提取图片特征,并还原出原始图片。
- 最终结果通过多次降噪操作得到,将其输出。

CLIP模型
一个专门为文生图设计的文本编码器
1. 训练步骤
CLIP模型是一种特殊的文本编码器,用于SD中图像和文本的配对。CLIP的训练步骤包括:
– 有约束的预训练:使用一个图像和文本描述数据集,将文本描述编码为向量,图片编码为向量,训练过程中使输出结果尽量接近。
– 进一步训练:创建一个有物体名称的数据集,输入为描述和对应的图片,通过编码器将描述转化为向量,通过图片编码器将图片转化为向量,训练过程中使解码结果与原始图片尽量接近,最终训练得到一个强大的文本编码器。这样在文生图时就可以很好的根据提示词生成结果。

2. 用途
CLIP模型可以根据提示词生成结果,进而在生成图片时提供指导。
Unet模型

1. 功能(简单理解)
Unet模型是SD的核心功能部分,用于加噪和降噪。
– 加噪:通过不断的添加噪声(随机变量)到中间结果图片,达到完全添加噪声的效果。
– 降噪:将添加完噪声的图片降噪,逐渐消除噪声,直到得到中间结果图片。中间结果图片与最终生成的图片大小相同,可以理解为图片的压缩版本。

2. 实际过程
- 使用VAE(编码器)Encoder对原始图片进行编码,得到与浅变量相同大小的中间结果图片。
- 将中间结果图片与噪声相加,得到第一次加噪结果。
- 将第一次加噪结果与另一个噪声相加,得到第二次加噪结果。
- 重复以上过程,直到得到完全加噪的图片。
- 对完全加噪的图片进行降噪,最终得到中间结果。
VAE模型
1. 全称
VAE是变分自编码器(Variational Autoencoder)的缩写。

2. 功能
VAE的功能即编码和解码。(编码-训练模型,解码-文生图)通过编码器将图片编码为较小的图片表示,再通过解码器将较小的图片解码为与原始图片大小相同的图片。目的是尽量还原原始图片,学会编码解码过程。
3. 用途
VAE在SD中的作用主要是从降维和还原图片。它可以从噪声中提取图片特征,并还原成原始图片,在图像生成中起到了还原的作用。
SD整体架构
SD整体架构由文本编码器CLIP、生成模型Unit和变分自编码器VE组成。CLIP用于文本编码,Unit用于加噪和降噪,VE用于降维和还原。整体流程分为文本编码、生成模型生成中间结果、中间结果经过VE降噪还原。每个部件在数据集收集、训练过程中有不同的作用和需求。在CONFUI中会进一步讲解这些部件的工作流程。
up:新建文件夹X
© 版权声明
文章版权归作者所有,未经允许请勿转载。