
我们了解到 Stable Diffusion模型都是基于 512×512 分辨率的图像进行训练的,所以我们生成的图片尽量不要超过这个分辨率,否则可能会让整体画面失去控制。但是基于 512 分辨率生成的图片无法满足我们对清晰度的要求,于是高清修复便成为了我们SD作图的必要步骤。
本期开始我们分三期来学习一下 webUI 自带的高清放大插件,其他高清插件和工具以及高清修复的妙用。在WEBUI中,它为我们提供了三种方式进行图片放大,
– 分别是文生图中的高清修复,
– 图生图中的upscale插件和Extra 图片放大。
– 本期主要讲文生图中的高清修复
文生图-高清修复选项
- 在文生图中,采样方法的下方,我们就可以看到高清修复选项。打钩激活之后就可以看到相关控制参数。
- 分别是放大算法、高清修复采样次数、重绘幅度、放大倍率和自定义宽高调整。
放大算法
- 首先第一个高清算法在 webui 中默认为我们提供了 15 种高清算法。这 15 种算法可以分为八类,分别是潜变量latent、Lanczous、最临近Nearest、Esrgan、LDSR、ScuNET和SwinIR.
高清修复采样次数。
- 这个参数为我们进行高清修复时使用的迭代步数,设置为零时则使用默认步数。这个参数一般不需要调整,保持零即可。如果调整也需要配合重绘幅度进行.
重绘幅度
- 重绘幅度决定算法对图像内容的保留程度,该值越高,放大后图像就比放大前图像差别越大,高值就会对原图进行不同程度的改写。具体的执行步骤为重绘强度乘以重绘步数。
放大倍率和自定义宽高调整
- 放大倍率就是我们希望将原图尺寸放大多少倍,比如原图 512×512,放大两倍就是 1024×1024,以此类推。一般情况下我们都是选择放大两倍,有特殊需求的可以适当提高倍数,注意很容易爆显存。自定义宽高当选定倍率时,这个参数是灰色的,但是当我们直接调整的时候会点亮,同时放大倍数就会灰掉且失效,所以高清工作时就会采用你设置的长宽。一般情况下我们也是不会去调整这个参数的。

- 但是有个问题你需要了解一下,如果你调整了高清后的图片,会按照你原图的短边进行比例裁剪,然后再进行放大重绘。


高清算法测试
所以高清修复中最重要的莫过于高清算法,但每个算法的具体原理晦涩而又难懂,我们大致了解一下就好。作为使用者的,我们只需关心哪个算法更适合哪种类型的放大就好,所以就让我用具体的测试来一一分析吧。
算法测试分类:
- 写实类测试咒语:
- 真人使用人物眼睛的特写。 模型选择为麦橘大佬的真人模型。
- 二次元类测试咒语:
- 坐在草地和花丛中的白长直女孩。 模型选择为表现优异的二次元模型 counterfeit。

算法表现测试:
- 默认迭代步数为20,高分迭代步数为0。
- 第一类潜变量latent:
- 是一种基于外模型的图像增强算法。
- 通过将原始图像编码成潜在向量,并对其进行随机采样和重构,从而增强图像的质量、对比度和清晰度。
- 在一般情况下,该算法显存消耗较小,但效果并非最优。
- 变量算法包括六种:
- 潜变量
- 潜变量抗锯齿
- 潜变量bicubic
- 潜变量摆bicubic抗锯齿
- 潜变量最临近整数
- 潜变量最邻近整数

重绘幅度0-1表现
写实类图片
首先是写实类图片,经过与原图的对比,重绘幅度 0.3 级以下,高清放大效果并不理想,甚至把一缕发丝变成了伤口。

0.4 和 0.5 的放大效果相对不错,

0.6 到 0.8 眼影部分变化大

0.9 合一还是算了吧。

整体来看,LT 的算法都把鼻子重绘了出来,因此造成了面部比例失调。如果不考虑比例失调问题,写实类图片使用这个系列算法进行放大的时候,建议选择重绘幅度 0.4 到 0.5 比较合适。
二次元类图片
然后是二次元类图片,经过对比,重绘幅度零到 0.4 不仅没有高清放大,反而模糊了。

真正高清修复表现好的则是从 0.5 开始,但是仔细观察能比较好,保持原图结构的也只有 0.5 了,但是女孩胸口的蝴蝶结细节,0.5 幅度也进行了完全重绘。

以下三个算法(Lanczos、最邻近整数缩放、SwinlR 4x)我们放在一起测试。
Lanczos
Lanczos是一种用于对称矩阵的特征值分解的算法,在机器学习中通常用于实现特征值分解的近似算法,例如用于计算大规模数据集中的主成分分析(PCA)或矩阵逆运算。Lanczos算法的基本思路是利用正交矩阵将原始矩阵变换为一个三对角矩阵,然后使用迭代方法找到这个三对角矩阵的特征值和特征向量。由于三对角矩阵的维度通常比原始矩阵小得多,因此Lanczos.算法可以大大加速特征值分解的计算过程。
Lanczos算法的优点是它非常简单且易于实现,并且对于许多数据集而言效果很好。然而该算法的缺点是它在处理高维数据和大规模数据时的计算开销非常大,并且对于噪声数据和类别之间的不平衡性表现较差。
Nearest最临近算法
最临近算法是一种常见的机器学习算法,用于分类和回归问题。在分类问题中,最临近算法根据样本之间的距离将新样本分配给最相似的已知样本所属的类别。在回归问题中,最临近算法通过找到与新样本最相似的已知样本来预测输出值。最临近算法的优点是它非常简单且易于实现,并且对于许多数据集而言效果很好。然而该算法的缺点是它在处理高维数据和大规模数据时的计算开销非常大,并且对于噪声数据和类别之间的不平衡性表现较差。
SwinIR 4x算法
SwinIR 4x是一种基于Swin transformer 的图像超分辨率重建算法,可将低分辨率图像放大四倍,生成高分辨率图像。Swin transformer 是一种新型的 transformer 模型,相对于传统的 transformer 模型,在处理图像等二维数据时具有更好的并行性和更高的计算效率。SwinIR 4x通过引入Swin transformer 和局部自适应模块,提高图像重建的质量和速度,其中局部自适应模块用于提高图像的局部细节,从而增强图像的真实感和清晰度。SwinIR 4x被广泛应用于计算机视觉领域,特别是图像重建、图像增强和图像超分辨率等方面。
- 图像重建算法比较
- SwinIR 4x的高清处理效果优异,并且随着重绘幅度的提升,整体布局开始有些失控。
- Lanczos算法表现一般,随着重会幅度的递增,没有很惊艳的效果,0.4左右的参数表现较好。
- Nearest最临近算法表现要优于Lanczos算法,且综合效果最好的参数在0.4左右。
- 图像增强算法比较
- 对于二次元类图片,SwinIR 4x的表现碾压其他算法,即使从0.5开始的重绘幅度已经对原图细节进行了明显改变。
- Lanczos算法在0.3的保持度下,高清表现在0.4到0.6之间效果较好。
- Nearest需要将重绘幅度拉到0.6才能表现出高清效果,但这样会损失原图的细节。
- 选择合适的算法和重绘幅度
- 综合来看,在修复二次元风格图片时,建议将重绘幅度控制在0.7以下。
- 低重绘幅度且保持原图细节的情况下,推荐选择SwinIR 4x算法。

LDSR算法
下一组测试是LDSR算法,LDSR是一种用于图像超分辨率的深度学习算法,全称为Deep Laplacian Pyramid Super-resolution。LDSR算法通过学习图像的低分辨率版本和高分辨率版本之间的关系,来实现图像的超分辨率。虽然LDSR模型是stable Diffusion中最基础的算法模型,但它体积很大,速度很慢,资源耗费较多。
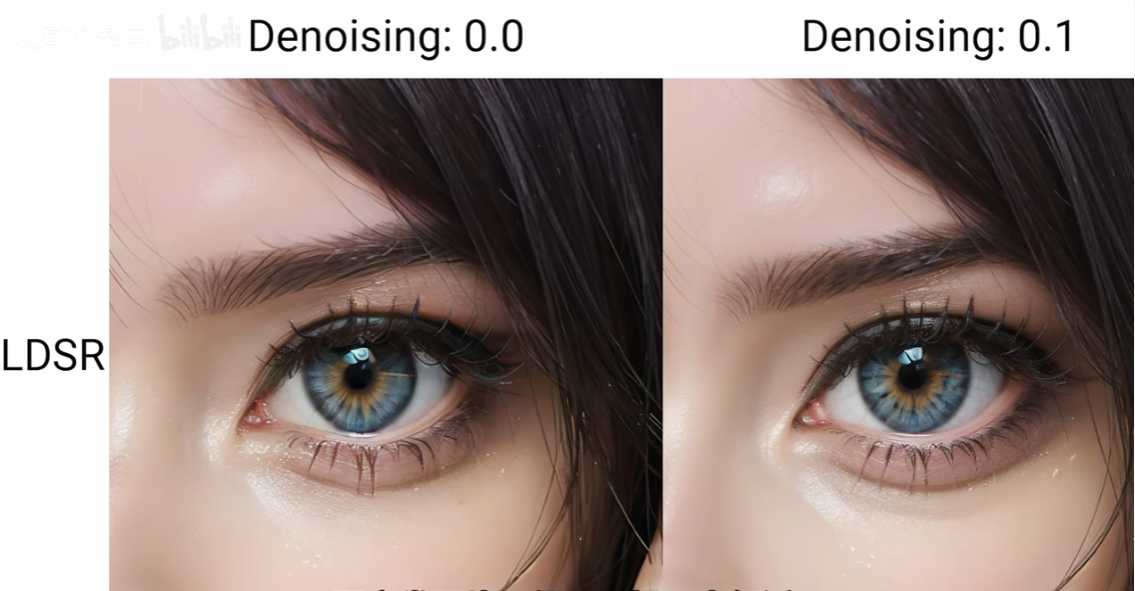
综合看来,LDS2算法在低重绘下的高清效果真的很完美,重绘幅度 0.1 开始甚至把眼白上的血管都画了出来。但是老问题,重绘幅度高于 0.6 的时候,画面比例开始失调。
EsrGan系列和Scu系列
最后一组测试图就是EsrGan系列和Scu系列了(ESRGAN_4x、R-ESRGAN 4x+、R-ESRGAN 4x+Anime6B、ScuNET、ScuNET、PSNR)。
EsrGan
- EsrGan是Enhanced Super-Resolution Generative Adversarial Network的缩写,是一种基于生成对抗网络(GAN)的图像超分辨率算法。其主要思想是通过学习低分辨率(L2)图像与其高分辨率(HR)对应物之间的映射,来实现从L2图像到HR图像的映射过程,从而实现图像的超分辨率。相较于传统的基于差值的超分辨率算法,EsrGan可以生成更加清晰、细节更加丰富的高分辨率图像。ESRGANE的训练数据集通常包括低分辨率图像及其对应的高分辨率图像,其训练过程中通过生成器网络(Generator)和判别器网终(Discriminator)相互对抗,以提高生成器的超分辨率效果。
ESRGAN4x
- ESRGAN4x是一种基于超分辨率技术的图像增强算法。它是ESRGAN算法的一种改进版本,可以将低分辨率的图像通过神经网络模型增强到4倍的分辨率。ESRGAN4x算法主要利用超分辨率技术中的单图像超分辨率重建方法,通过对低分辨率图像进行学习和训练,学习到图像的高频细节信息,然后将这些信息用于重建高分辨率图像。相比于传统的插值方法,ESRGAN4x算法在增强图像的细节信息和保留图像质量方面有了明显的提升。
R-ESRGAN 4x+
- 而R-ESRGAN 4x+是一种基于超分辨率技术的图像增强算法,全称为”Real-Time Enhanced Super-Resolution Generative Adversarial Network 4x+”,是一种基于生成式对抗网络(GAN)的算法。是ESRGAN的改进版本之一。它通过引入残差连接和递归结构,改进了ESRGAN的生成器网络,并使用GAN进行训练。R-ESRGAN4x+在提高图像分辨率的同时,也可以增强图像的细节和纹理,并且生成的图像质量比传统方法更高。它在许多图像增强任务中都取得了很好的效果,比如图像超分辨率、图像去模糊和图像去噪等
R-ESRGAN4x+Anime6B
- R-ESRGAN4x+Anime6B是一种基于超分辨率技术的图像增强算法,主要用于提高动漫图像的质量和清晰度。它基于R-ESRGAN4x+算法,并使用了Anime6B数据集进行训练。Anime6B数据集是一个专门用于动漫图像处理的数据集,其中包含了大量不同风格、不同质量的动漫图像,使得算法可以适应不同类型的动漫图像处理,如动画制作、漫画制作等。
Swin-Conv-UNet
- Swin-Conv-UNet(SC-UNet)是一种新的图像去噪方法,用于清除真实图像中的噪声。作者创建了一个特殊的计算机模型,结合了两种技术,既能捕捉图像中的局部细节,也能理解整个图像的大致结构。与以往的方法不同这个新方法不仅考虑了一种噪声,还考虑了不同类型的噪声和图像大小调整。
-
算法测试结果总结:
- 写实类图片的零重绘幅度时,R-scan4X表现最好,随着重绘幅度的提升,五个算法的清晰度逐渐相似。
- EsRrcan 4x 的表现略差于两R系列。 SCunet系列整体有些模糊,比其他三个算法表现稍差。
- 二次元类图片方面,R-ESRGAN4X+Anime6B的效果最好,重绘幅度提升R-ESRGAN 4X逼近A6B,但ESRGAN 4x还是逊色手两个R-ESGAN。
- 至于SCUNet整体表现还是模糊。
- 算法选择建议:
- 绿色:建议使用的参数。
- 黄色:可以尝试的参数。
- 红色:不建议使用的参数。


up:A_Eye实验室

相关文章

