
MovieChat是一个理解长视频的系统,能理解视频内容并回答关于视频的问题 MovieChat整合了视觉模型和大型语言模型,以克服特定预定义视觉任务的限制。 该模型将记忆分为短期记忆和长期记忆两种类型。短期记忆负责最新事件的记忆,长期记忆存储的是视频中的关键信息,这些信息在长时间内保持不变。

MovieChat旨在解决长视频的计算复杂性、内存成本和长期时间连接的挑战。 MovieChat的工作机理主要基于Atkinson-Shiffrin记忆模型的启发,提出了一个包括快速更新的短期记忆和紧凑的长期记忆的记忆机制。
短期记忆被设计为快速更新,可以理解为对视频中最近发生的事件的记忆,这种记忆随着新事件的发生而快速更新。长期记忆则更为紧凑,存储的是视频中的关键信息,这些信息在长时间内都保持不变。
在Transformer模型中,tokens被用作记忆的载体。这意味着,每一个token都可以被视为一个记忆单元,存储了视频中的某一部分信息。通过这种方式,MovieChat可以在处理长视频时,有效地管理和利用记忆资源。
MovieChat框架由视觉特征提取器、短期和长期记忆缓冲区、视频投影层和大型语言模型组成。视觉特征提取是使用预训练模型如ViT-G/14和Q-former完成的。这些视觉特征被提取出来,然后通过视频投影层转换为可以被大型语言模型处理的形式。
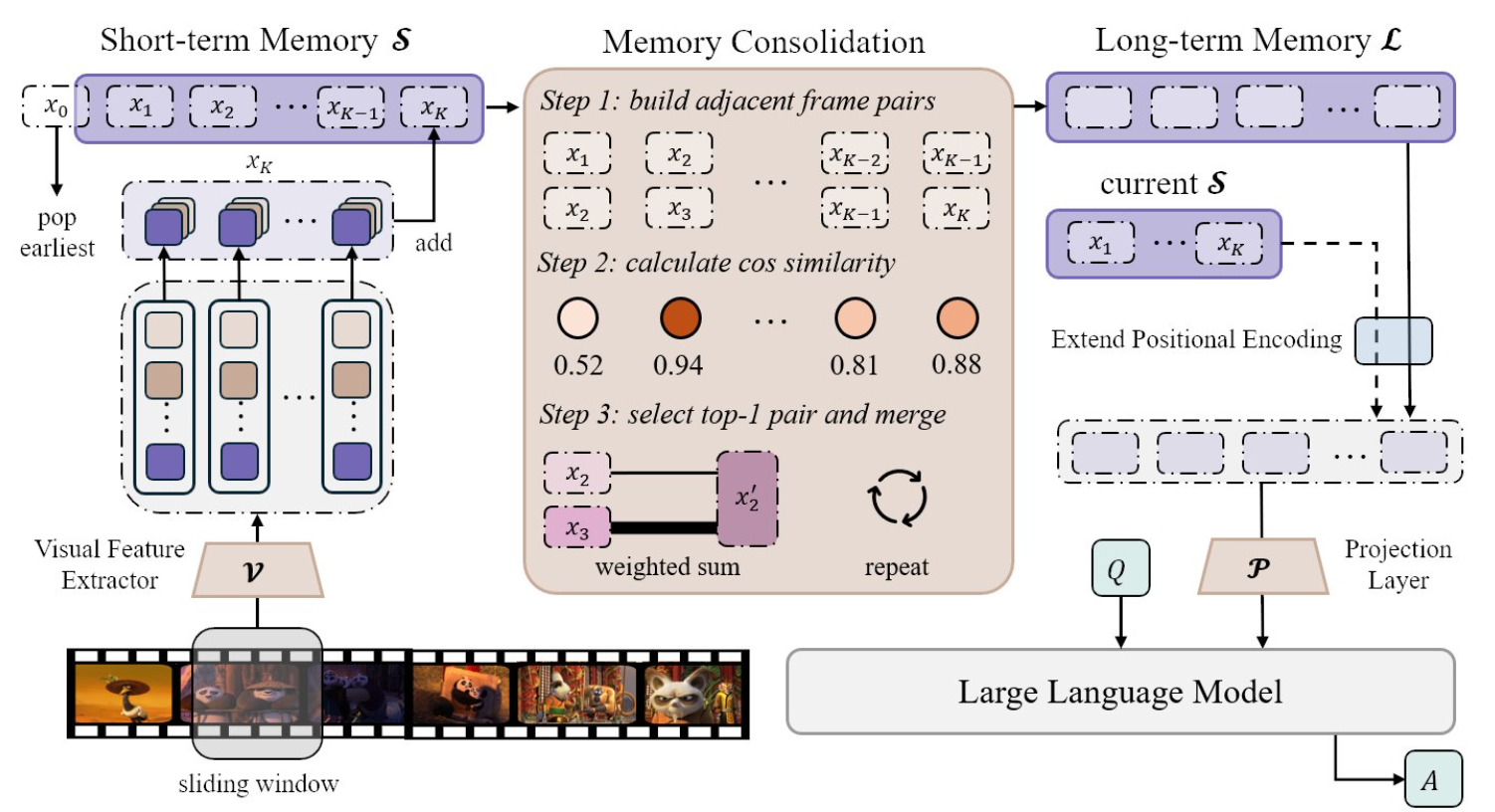
MovieChat的工作原理主要包括以下几个步骤:
1、预处理:首先,将视频切割成一系列的片段,并对每个片段进行编码,得到每个片段的特征表示。
2、记忆管理:然后,将这些特征表示存储到记忆中。在处理新的视频片段时,会更新记忆,旧的信息会被逐渐遗忘,新的信息会被存储到记忆中。
3、问题回答:当接收到一个问题时,MovieChat会根据问题和记忆中的信息生成一个回答。这个过程是通过一个Transformer模型完成的,该模型可以处理长序列,并生成相应的回答。
© 版权声明
文章版权归作者所有,未经允许请勿转载。



