
本文手把手带你开发一个 Coze 扣子插件。我们要做的功能很实用:输入一个 B 站 UP 主主页,批量抓取他的视频字幕(包括 AI 自动字幕)。
本文适合 完全没写过插件的人,照着做就能跑通。
目录
1. 插件要实现什么?
输入:一个 B 站 UP 主的主页地址,例如:
https://space.bilibili.com/1196144358/video
输出:这个 UP 投稿的视频列表,带上字幕信息,长这样:
{
"code": 0,
"message": "ok",
"data": {
"count": 5,
"items": [
{
"bvid": "BV1xxxx",
"title": "某个视频标题",
"has_subtitle": true,
"captions_text": "[00:00] 字幕内容..."
}
]
}
}
2. 准备工作
- 一个 Coze 账号。
- 一点点 Python 基础(会
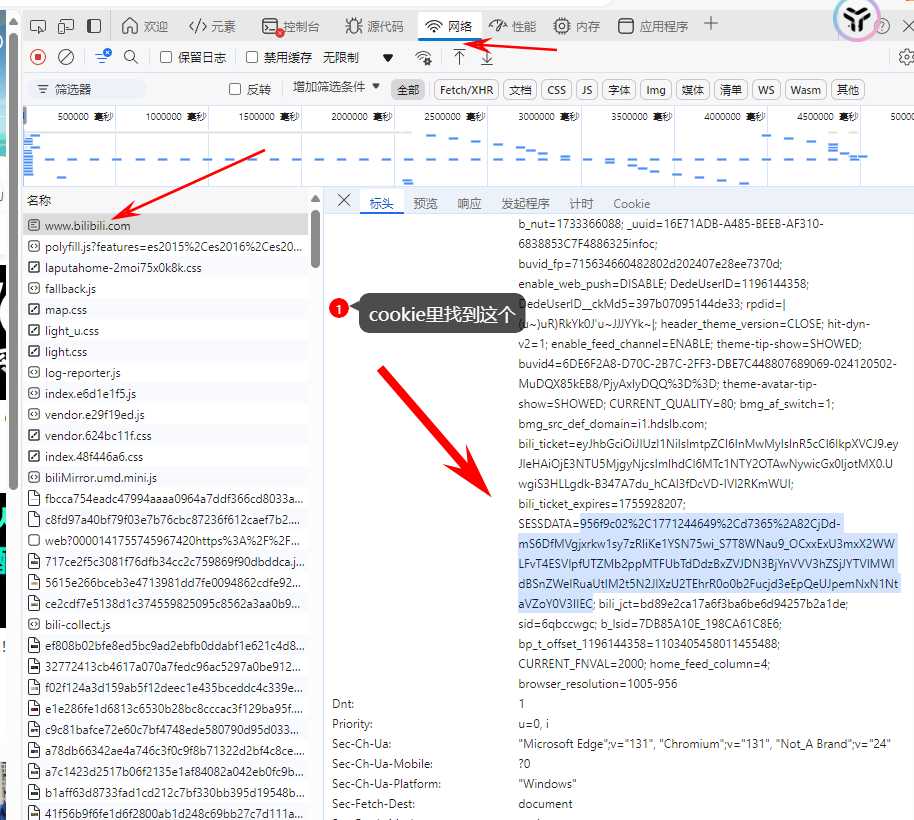
import requests就够)。 - 如果想抓取 AI 自动字幕,需要登录过的 B站 Cookie →
SESSDATA值。
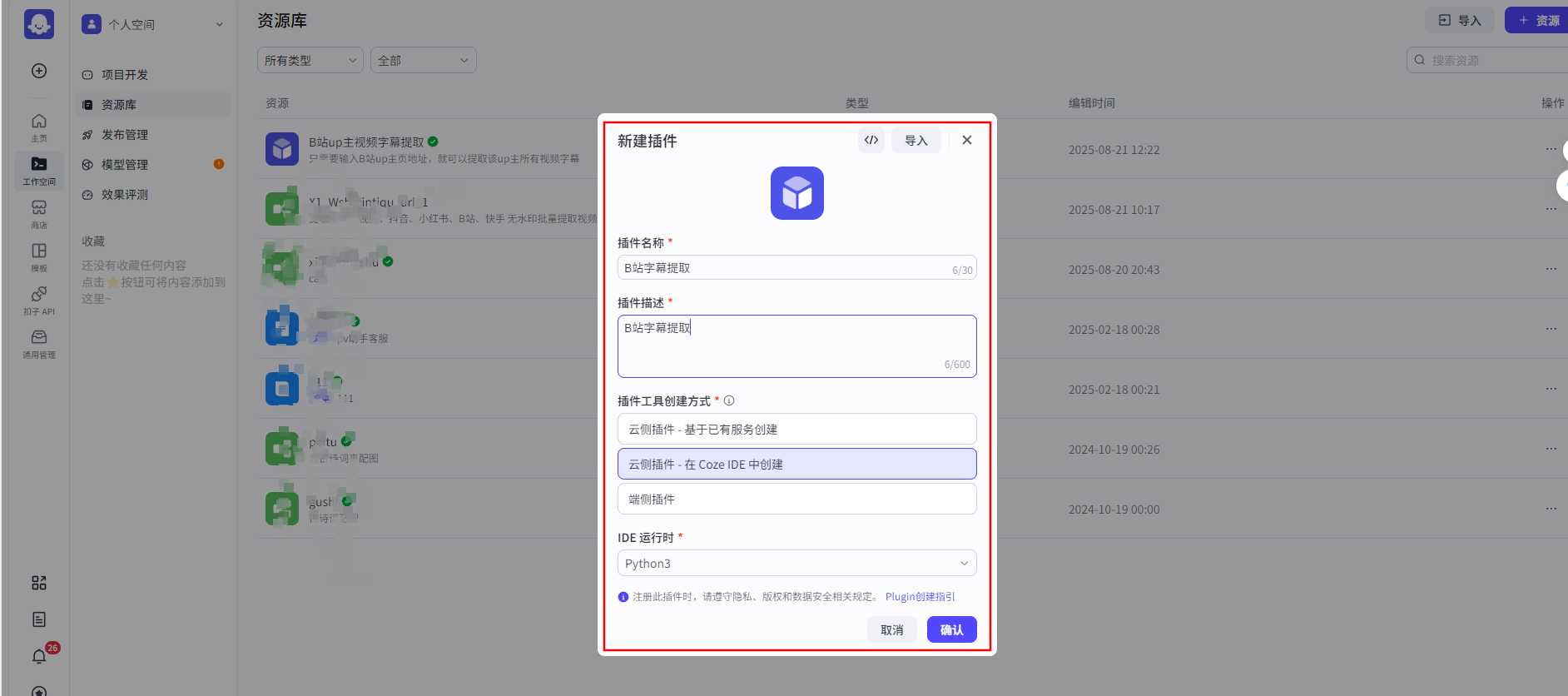
3. 在 Coze 里新建插件
- 打开左侧 插件 → 点击 创建插件。
- 插件类型选择 代码插件(Python)。

- 插件建好后,在“工具列表”里新增一个工具:
- 工具名:
bili_up_captions_v1(名字随便,但不能和现有重复)。 - 工具简介:
批量获取B站UP主视频字幕
4. 配置输入输出参数
进入插件的 元数据 页面。
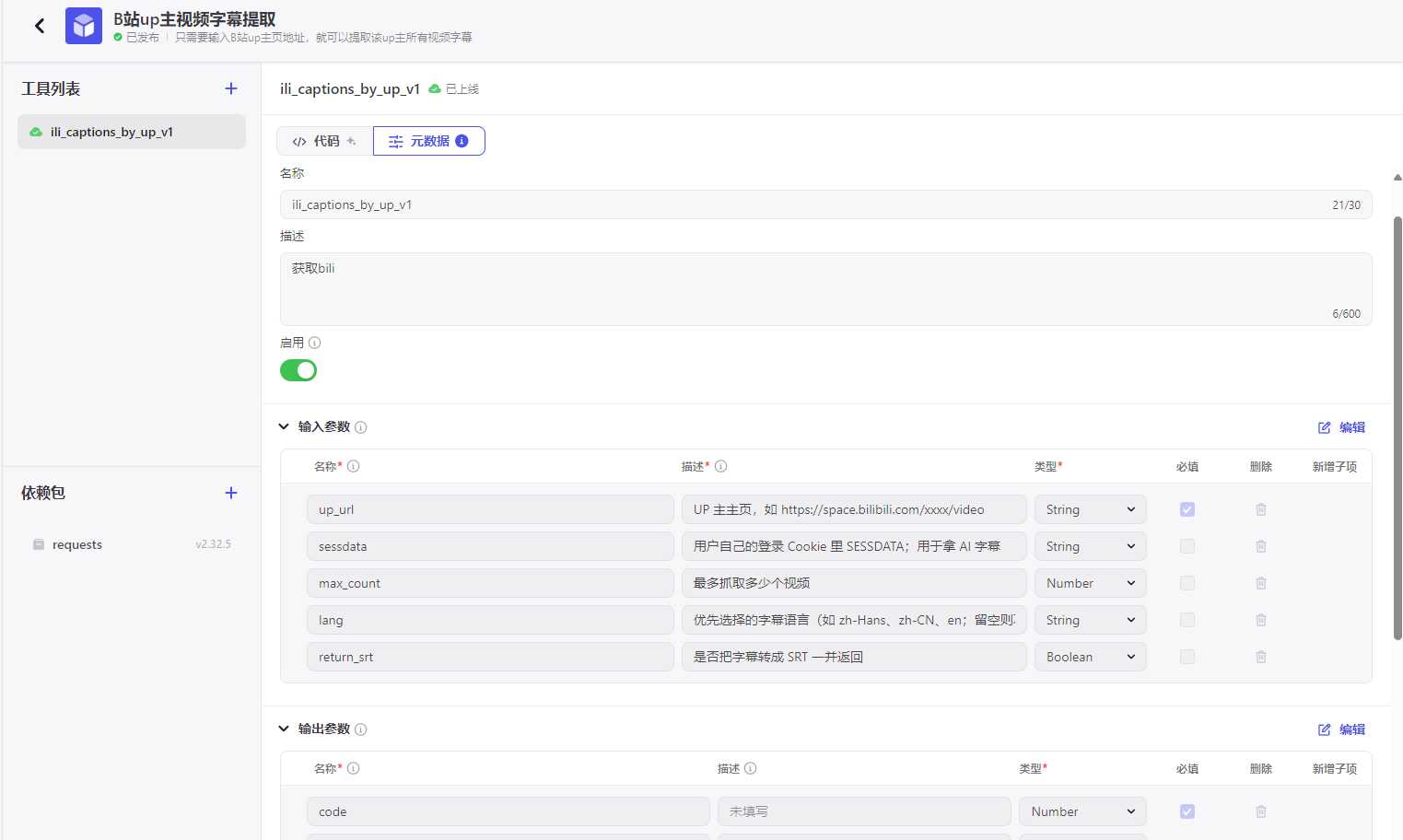
输入参数
up_url(String, 必填) — UP主页链接。sessdata(String, 可选) — 登录 Cookie,拿 AI 字幕用。max_count(Number, 可选) — 抓多少条视频,默认 5\~20。lang(String, 可选) — 指定语言,比如zh-Hans。return_srt(Boolean, 可选) — 是否返回 SRT(先保留开关)。
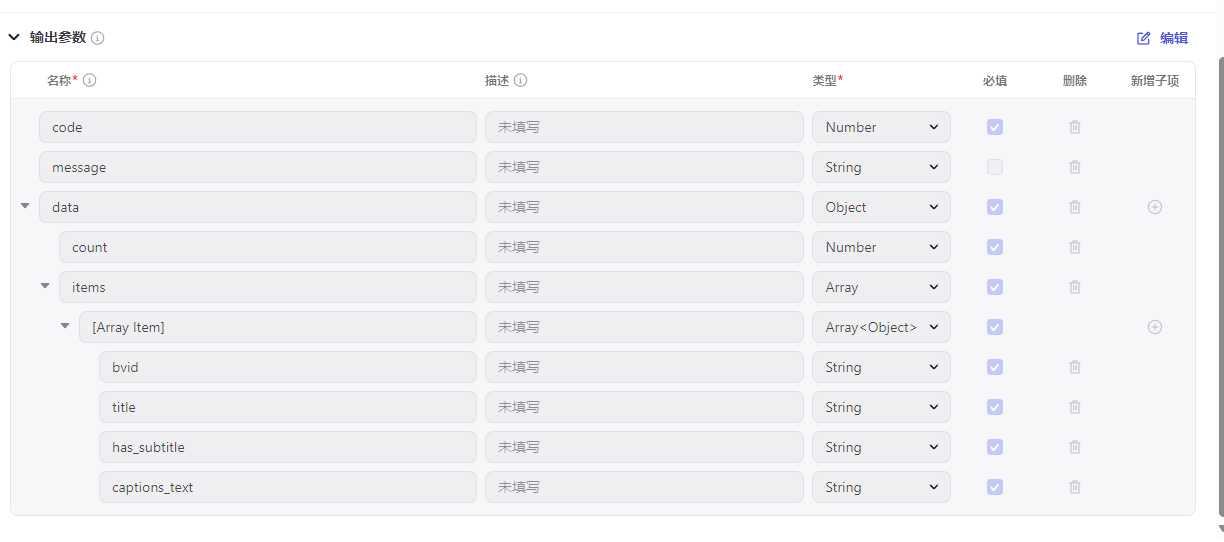
输出参数
code(Number)message(String)data(Object)count(Number)items(Array-
bvid(String) title(String)has_subtitle(Boolean)captions_text(String)
⚠️ 注意:items 一定要设置成 Array,然后在里面加子字段,否则无法返回结构化数据。
5. 写 Python 代码
点击上方的 代码 标签,把下面的代码粘进去。
别忘了在左下角“依赖包”里添加 requests。
import requests, re, time, random
UA = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/115 Safari/537.36"
# ========= 工具函数 =========
def _read_input(args, key, default=None):
try:
inp = getattr(args, "input", None)
if inp is not None and getattr(inp, key, None) is not None:
return getattr(inp, key)
if isinstance(args, dict) and key in args:
return args[key]
except: pass
return default
def _ok(data, msg="ok"): return {"code":0,"message":msg,"data":data}
def _err(msg): return {"code":-1,"message":msg,"data":{"count":0,"items":[]}}
def _to_int(v,d=0):
try: return int(v)
except: return d
def _to_bool(v,d=False):
if isinstance(v,bool): return v
if isinstance(v,str): return v.lower() in {"true","1","yes"}
if isinstance(v,(int,float)): return v!=0
return d
def _extract_mid(url):
m=re.search(r"space\.bilibili\.com/(\d+)",url)
return m.group(1) if m else None
# ========= 主逻辑 =========
def handler(args):
up_url = str(_read_input(args,"up_url","")).strip()
sess = str(_read_input(args,"sessdata","") or "").strip()
max_ct = _to_int(_read_input(args,"max_count",5),5)
lang = str(_read_input(args,"lang","") or "").strip()
if not up_url: return _err("请提供UP主页链接")
mid = _extract_mid(up_url)
if not mid: return _err("无法解析mid")
bvids = get_up_bvids(mid,sess,limit=max_ct)
items = []
for bvid in bvids:
title,cid = get_title_and_cid(bvid)
if not cid:
items.append({"bvid":bvid,"title":title or "","has_subtitle":False,"captions_text":""})
continue
player = get_player_info(bvid,cid,sess)
sub_list = extract_sub_list(player)
if not sub_list:
items.append({"bvid":bvid,"title":title,"has_subtitle":False,"captions_text":""})
else:
chosen = choose_sub(sub_list,lang) if lang else sub_list[0]
j = download_json(chosen["url"],sess)
if not j or "body" not in j:
items.append({"bvid":bvid,"title":title,"has_subtitle":False,"captions_text":""})
else:
txt = "\n".join([f"[{int(s['from']//60):02d}:{int(s['from']%60):02d}] {s['content']}"
for s in j["body"] if s.get("content")])
items.append({"bvid":bvid,"title":title,"has_subtitle":True,"captions_text":txt})
time.sleep(random.uniform(0.8,1.5))
return _ok({"count":len(items),"items":items})
# ========= API 调用 =========
def get_up_bvids(mid,sess,limit=5):
url="https://api.bilibili.com/x/space/arc/search"
s=requests.Session()
if sess: s.headers.update({"Cookie":f"SESSDATA={sess}"})
s.headers.update({"User-Agent":UA})
bvids=[]
pn=1
while len(bvids)<limit:
r=s.get(url,params={"mid":mid,"pn":pn,"ps":30,"order":"pubdate"},timeout=10).json()
if r.get("code")!=0: break
vlist=(r.get("data") or {}).get("list",{}).get("vlist") or []
if not vlist: break
for v in vlist:
if v.get("bvid"): bvids.append(v["bvid"])
if len(bvids)>=limit: break
pn+=1
return bvids
def get_title_and_cid(bvid):
r=requests.get(f"https://api.bilibili.com/x/web-interface/view?bvid={bvid}",
headers={"User-Agent":UA},timeout=10).json()
if r.get("code")==0:
d=r.get("data") or {}
return d.get("title"),d.get("cid")
return None,None
def get_player_info(bvid,cid,sess=""):
h={"User-Agent":UA,"Referer":f"https://www.bilibili.com/video/{bvid}"}
if sess: h["Cookie"]=f"SESSDATA={sess}"
r=requests.get(f"https://api.bilibili.com/x/player/v2?cid={cid}&bvid={bvid}",headers=h,timeout=10).json()
return r if r.get("code")==0 else None
def extract_sub_list(info):
out=[]
try:
subs=(info.get("data") or {}).get("subtitle",{}).get("subtitles") or []
for s in subs:
u=s.get("url") or s.get("subtitle_url") or ""
if u.startswith("//"): u="https:"+u
out.append({"lang":s.get("lan"),"url":u})
except: pass
return out
def choose_sub(lst,lang):
for s in lst:
if (s.get("lang") or "").lower()==lang.lower(): return s
return lst[0]
def download_json(url,sess=""):
h={"User-Agent":UA}
if sess: h["Cookie"]=f"SESSDATA={sess}"
try: return requests.get(url,headers=h,timeout=10).json()
except: return None
📸 配图建议:贴一张 IDE 界面的截图。
6. 安装依赖
在 IDE 左下角,添加依赖 requests。等显示“已安装”再运行。
7. 测试运行
点击右上角“测试代码”,输入:
{
"up_url": "https://space.bilibili.com/1196144358/video",
"max_count": 5,
"lang": "zh-Hans"
}
如果你看到返回的 items 里有字幕,就成功啦。
如果 captions_text 为空,大概率是视频没有外挂字幕。带上 sessdata 再试试,就能抓到 AI 字幕。
8. 接入机器人或工作流
插件能跑通,就可以接到机器人或者工作流里了:
- 机器人:在工具面板加上它,并写规则:“当用户输入B站UP主页并说‘字幕’,就调用这个工具”。
- 工作流:上游节点接收链接 → 调用插件 → 下游节点做总结或翻译。
9. 常见问题 & 踩坑记录
- 工具名重复:换一个没用过的名字。
- 报 schema 错:数字要设成 Number,布尔要设成 Boolean。
- 抓到别人的视频:别用“动态接口”,要用“投稿列表接口”。
- 被限流
-412:加随机sleep,一次别抓太多。 - 字幕为空:可能本身没字幕,或者需要
sessdata。
10. 总结
扣子插件的开发流程其实很清晰:
- 新建插件 → 配输入输出。
- 写 Python 代码,逻辑放进
handler。 - 安装依赖,保存测试。
- 接入机器人或工作流。
这次的例子是“B站UP字幕抓取器”,但思路通了以后,你完全可以改造:比如抓评论、抓弹幕、把字幕翻译、或者自动生成笔记。
插件其实就是一段 Python + 一份输入输出定义,想象空间很大 🚀。
© 版权声明
文章版权归作者所有,未经允许请勿转载。