混元-DiT
混元-DiT:高性能细粒度中文理解,多分辨率扩散Transformer模型
DeepSeek-V2不只是一款模型,它是通往更智能世界的钥匙。它以更低的成本,更高的性能,开启了 AI 应用的新篇章。DeepSeek-V2 的开源,是对这一信念的最好证明,它将激发更多人的创新精神,共同推动人类智能的未来。

在人工智能领域,深度学习模型的发展速度令人惊叹。最近,杭州深度求索公司发布的DeepSeek-V2模型,以其独特的混合专家(MoE)架构和巨大的模型规模,成为了业界的焦点。

DeepSeek-V2是一款具有2360亿参数的混合专家语言模型,每个token激活21亿参数,支持长达128K的上下文长度。中文综合能力(AlignBench)开源模型中最强:与 GPT-4-Turbo,文心 4.0 等闭源模型在评测中处于同一梯队!
英文综合能力(MT-Bench)处于第一梯队:英文综合能力(MT-Bench)与最强的开源模型 LLaMA3-70B 处于同一梯队,超过最强 MoE 开源模型 Mixtral 8x22B知识、数学、推理、编程等榜单结果位居前列.
该模型通过引入MLA机制,不仅在性能上有了显著提升,而且在训练成本和计算资源消耗上都实现了大幅度降低。相比之下,DeepSeek-V2的性能和经济性都极具竞争力,尤其是与同类大型语言模型相比,如GPT-4-Turbo,DeepSeek-V2的成本仅为其百分之一,但提供了相等甚至更优的性能。
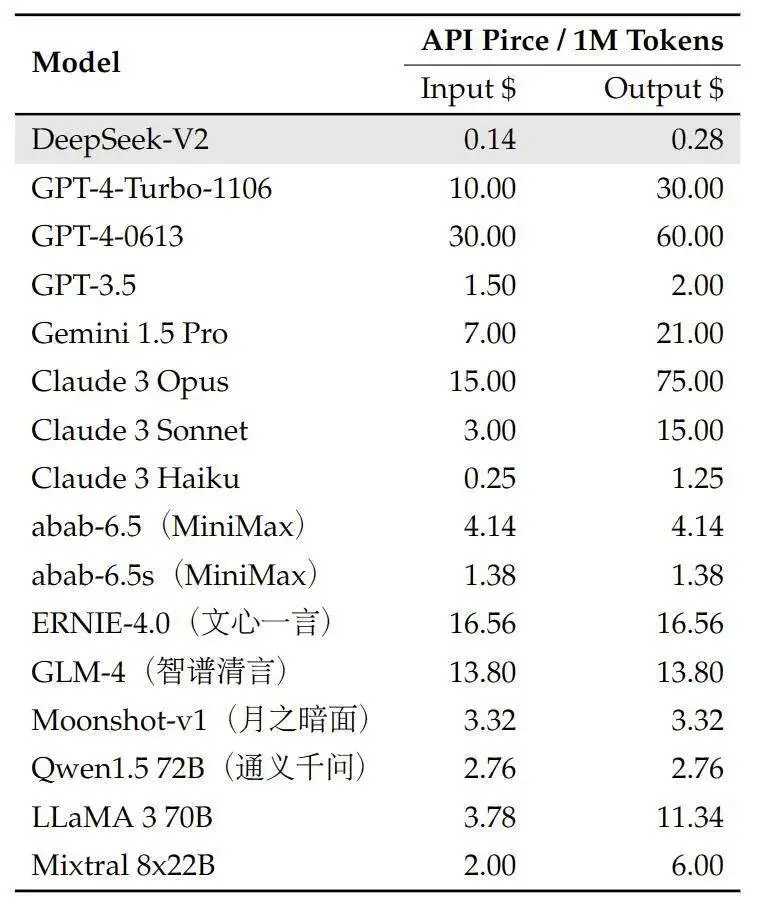
在全网搜索方面,DeepSeek-V2的强大处理能力和高效率表现尤为突出,这得益于其混合专家模型的结构设计和大规模参数配置。
| 事件名称 | 事件时间 | 事件概述 |
|---|---|---|
| DeepSeek发布DeepSeek V2模型 | 2024年5月7日 | 技术发布DeepSeek公司发布了新的开源大模型DeepSeek V2,这是一个混合专家(MoE)语言模型,具有236B参数。 |
| DeepSeek V2性能提升 | 不明确 | 技术进步与前代产品相比,DeepSeek V2在性能上实现了显著提升。 |
| DeepSeek V2成本降低 | 不明确 | 成本效益DeepSeek V2在训练成本和推理效率上表现出色,节省了大量计算资源。 |
| DeepSeek V2开源 | 近日 | 开源贡献DeepSeek AI公司开源了DeepSeek V2模型,旨在探索通用人工智能(AGI)的本质。 |
DeepSeek-V2模型的发布,不仅在技术上实现了重大突破,其开源的举动也为AI领域的研究和应用提供了新的可能性。这款模型的高性能、经济高效以及对长上下文的支持,使其在众多领域中有着广泛的应用前景,特别是在需要处理大量数据和复杂计算的场景中。DeepSeek-V2的成功,标志着混合专家模型在人工智能发展中的重要地位,同时也展示了杭州深度求索公司在AI技术创新方面的强大实力。
可以在线体验:
DeepSeek-V2官网