SenseChat
商汤科技推出的类ChatGPT的人工智能大语言模型
Langchain是基于Langchain思想的本地知识库问答应用。它旨在构建一个支持中文场景和开源模型的离线运行的知识库问答解决方案。

Langchain是基于Langchain思想的本地知识库问答应用。它旨在构建一个支持中文场景和开源模型的离线运行的知识库问答解决方案。受事先已有的document.ai项目的启发,以及AlexZhangji创建的ChatGLM-6B Pull Request,Langchain实现了FastChat接入Vicuna、Alpaca、LLaMA、Koala、RWKV等模型,并依托于Langchain框架,通过FastAPI提供的API调用服务,或使用基于Streamlit的Web UI进行操作。
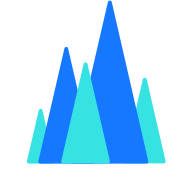
其实现原理如下:
从文档处理的角度来看,Langchain的实现流程如下:加载文件 -> 读取文本 -> 文本分割 -> 文本向量化 -> 问句向量化 -> 在文本向量中找到与问句向量最相似的前k个文本 -> 将匹配的文本作为上下文,与问题一起添加到prompt中 -> 提交prompt给LLM生成回答。
Langchain不涉求微调或训练过程,但可以通过微调或训练进行优化。该项目的代码已更新至0.2.7版本,并可在v11版本的AutoDL镜像中获取。Docker镜像也已更新至0.2.7版本。
docker run -d --gpus all -p 80:8501 registry.cn-beijing.aliyuncs.com/chatchat/chatchat:0.2.7
如果想更深入了解该项目或进行贡献,请参考项目的 Wiki页面。
Langchain解决了知识库增强中完全本地化推理的痛点,同时解决了企业在数据安全保护和私有部署方面的问题。该方案采用Apache License开源许可,可以免费商用,无需支付费用。它支持市场上主流的本地化大型预训练语言模型和Embedding模型,并支持开源的本地向量数据库。