
本测评结果仅用于学术研究。
零一万物(01.AI)成立于2023年5月16日,致力于打造全新的AI2.0平台。去年11月,零一万物发布Yi-6B、Yi-34B双语开源模型;前不久又推出一站式 AI 工作平台“万知”,引发颇多关注。
零一万物(01.AI)在5月13日发布了Yi-Large大模型。SuperCLUE团队提前受官方邀请体验Yi-Large API,并对Yi-Large进行了通用性能评测。
那么,Yi-Large在SuperCLUE中文基准上的表现如何?与国内外代表性大模型相比处于什么位置?在各项基础能力上如计算推理、长文本、代码生成、生成创作上会有怎样的表现?
我们基于SuperCLUE通用大模型综合性中文测评基准,对Yi-Large进行了全方位测评。
测评环境
参考标准:SuperCLUE综合性测评标准
评测模型: Yi-Large(官方小范围内测API)
评测集: SuperCLUE综合性测评基准4月评测集,2194道多轮简答题,包括计算、逻辑推理、代码、长文本在内的基础十大任务。
模型GenerationConfig配置:
- temperature=0.6
- top_p=0.9
- max_new_tokens=2048
- stream=false
测评方法 :****
本次测评为自动化评测,具体评测方案可点击查阅SuperCLUE综合性测评标准。本次测评经过人工抽样校验。


先说结论
结论1: 在SuperCLUE综合基准上,Yi-Large表现不俗,以总分74.29分的优异成绩刷新国内最好成绩,跻身国内大模型第一梯队。
结论2: 在本次测评中,相比国外代表性模型很有竞争力。总体来看,Yi-Large表现好于Llama3-70B,与Claude3-Opus打平,相比GPT4 Turbo相差4.84分,还有一定提升空间。
结论3: 在本次测评中,Yi-Large在各项能力上表现均衡,尤其在计算、代码、知识百科和语言理解能力上处于国内领先位置,适用于数理运算、编程助手、知识运用及文本处理等应用场景。安全能力还有一定提升空间。
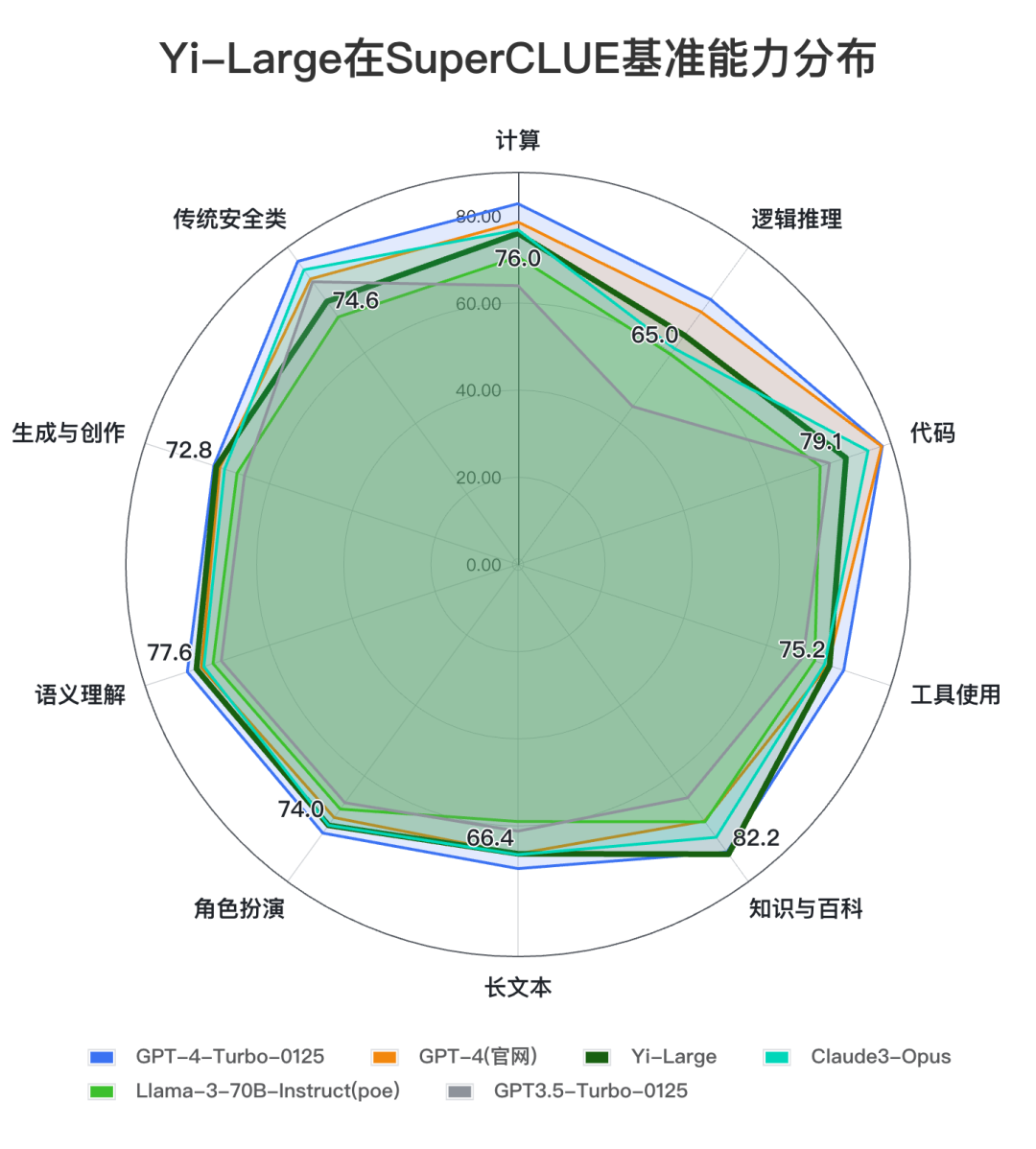
对比模型数据来源: SuperCLUE, 2024年4月30日**
以下是我们从 定量和定性 两个角度对模型进行的测评分析。
测评分析
1 定量分析
在SuperCLUE测评中,Yi-Large总体表现如下:
********Yi-Large** ******** ****总体表现** ****

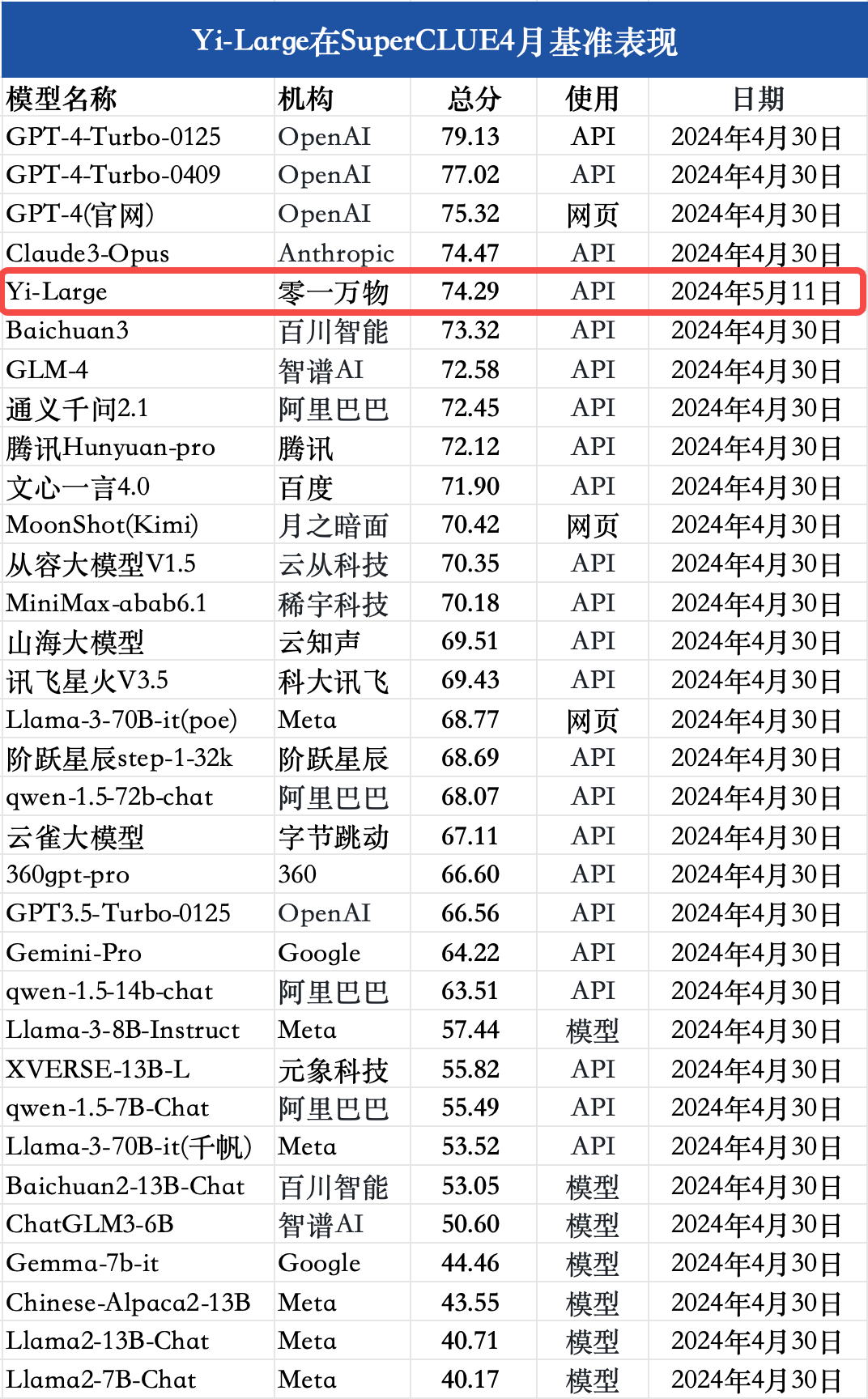
注:对比模型数据来源:SuperCLUE, 2024年4月30日;由于部分模型分数较为接近,为了减少问题波动对排名的影响,本次测评将相距0.25分区间的模型定义为并列,以上排序不代表实际排名。
在SuperCLUE通用综合测评基准上,Yi-Large取得74.29分,表现不俗,刷新国内大模型最好成绩。Yi-Large综合性能与Claude3-Opus水平相当。较GPT-4-Turbo-0125低4.84分。
********Yi-Large在十大基础能力上的表现** ******
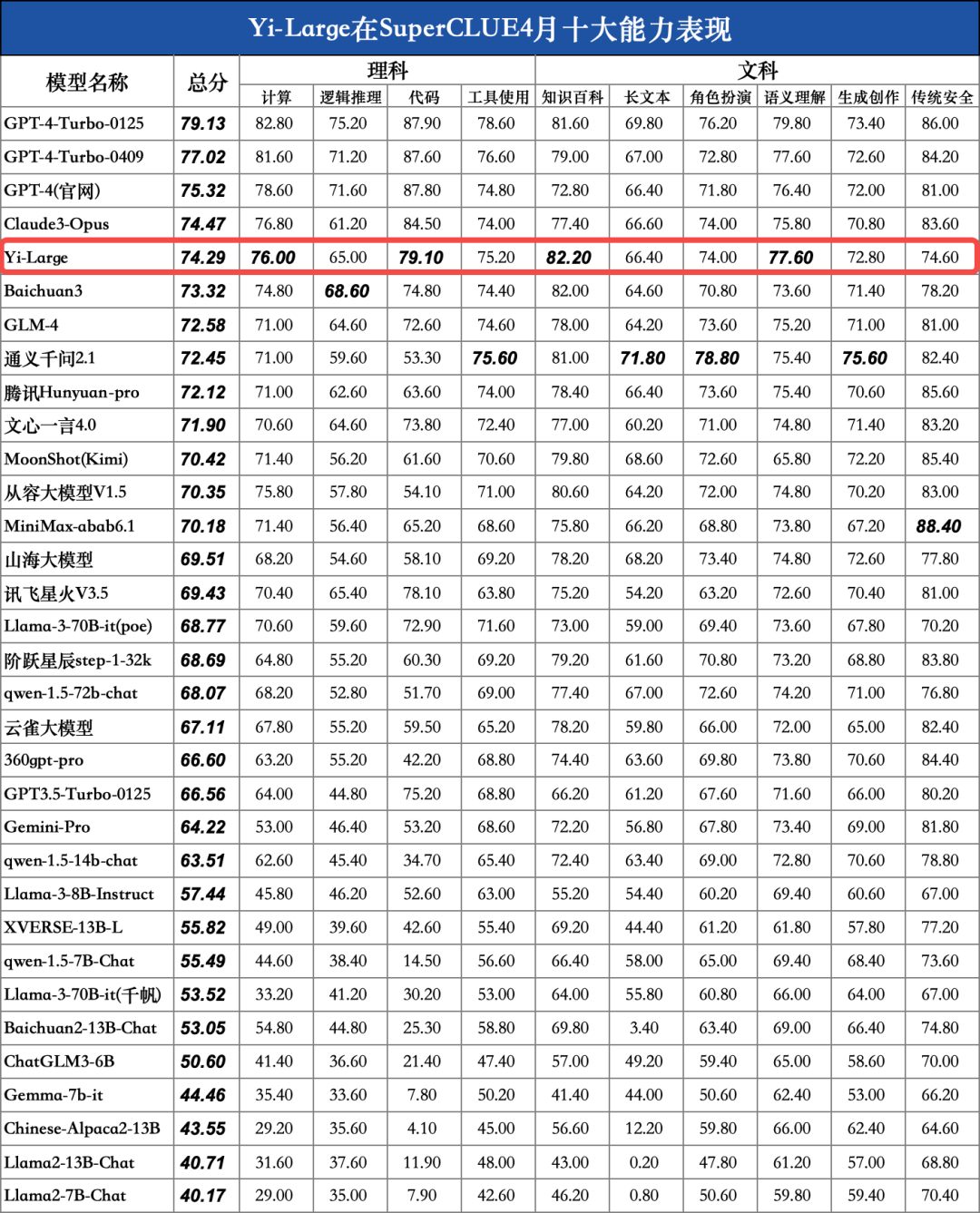
对比模型数据来源:SuperCLUE, 2024年4月30日
Yi-Large在十大任务上较为均衡。其中, 计算(76.0)、代码(79.1)、知识百科(82.2)和语义理解(77.6)均刷新国内最好成绩; 在安全能力上还有一定优化空间。
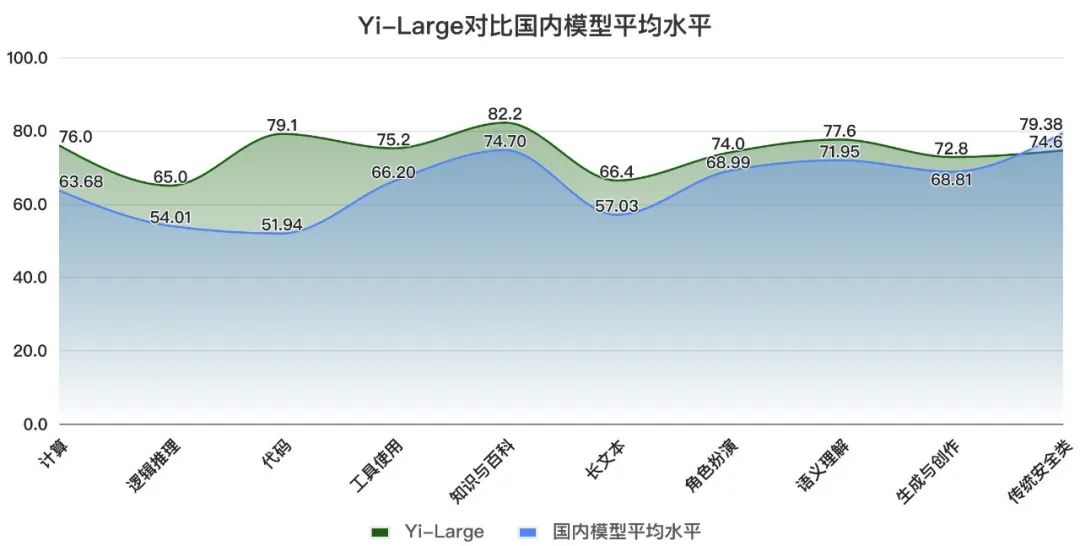
对比数据来源:SuperCLUE, 2024年4月30日
将Yi-Large与国内大模型平均得分对比,我们可以发现,Yi-Large在绝大部分能力上高于平均线,展现出较均衡的综合能力。尤其在计算(+12.32)、逻辑推理(+11.09)、代码(+27.16)、工具使用(+9)、长文本(+9.37)、知识百科(+7.50)能力上远高出平均线6分以上。
********Yi-Large与国外代表模型对比** ******
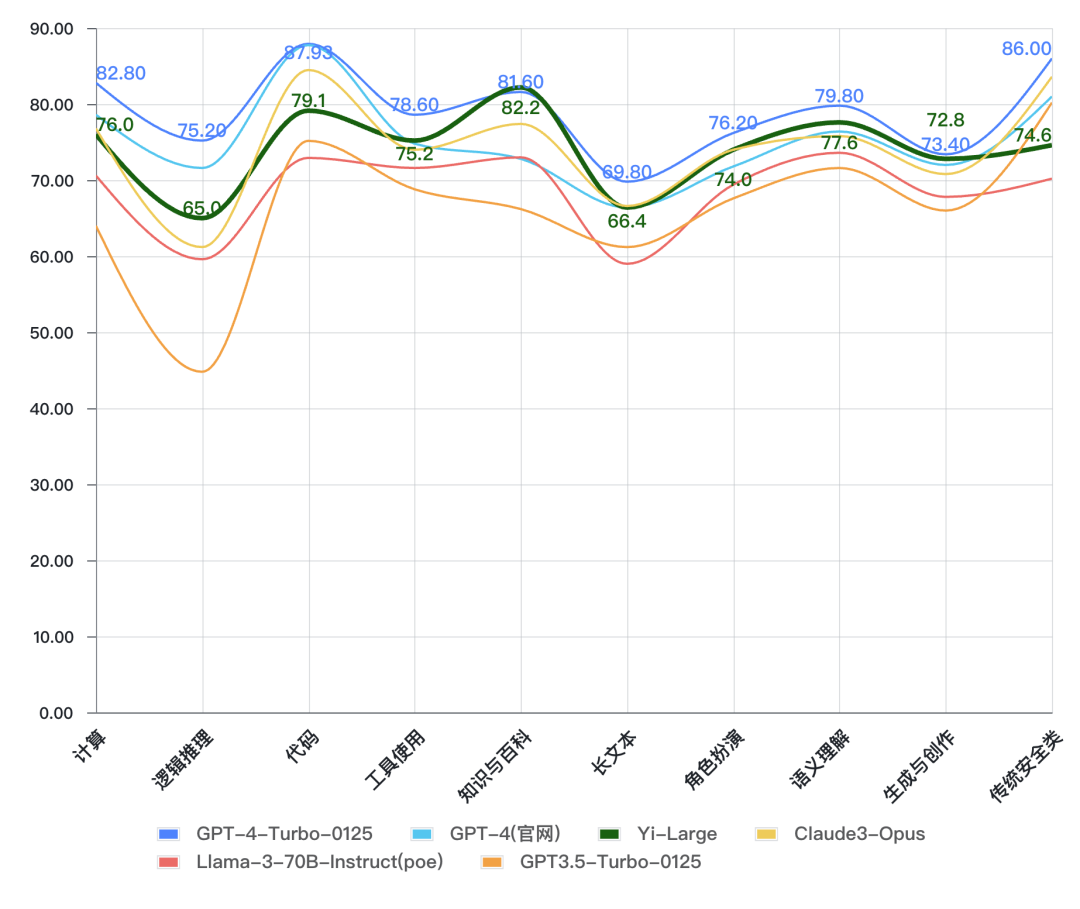
将Yi-Large与国外代表大模型对比,Yi-Large在绝大部分能力与GPT4(网页)、Claude3-Opus差距不大,综合能力表现优于Llama3-70B。较GPT-4-Turbo还有一定提升空间。
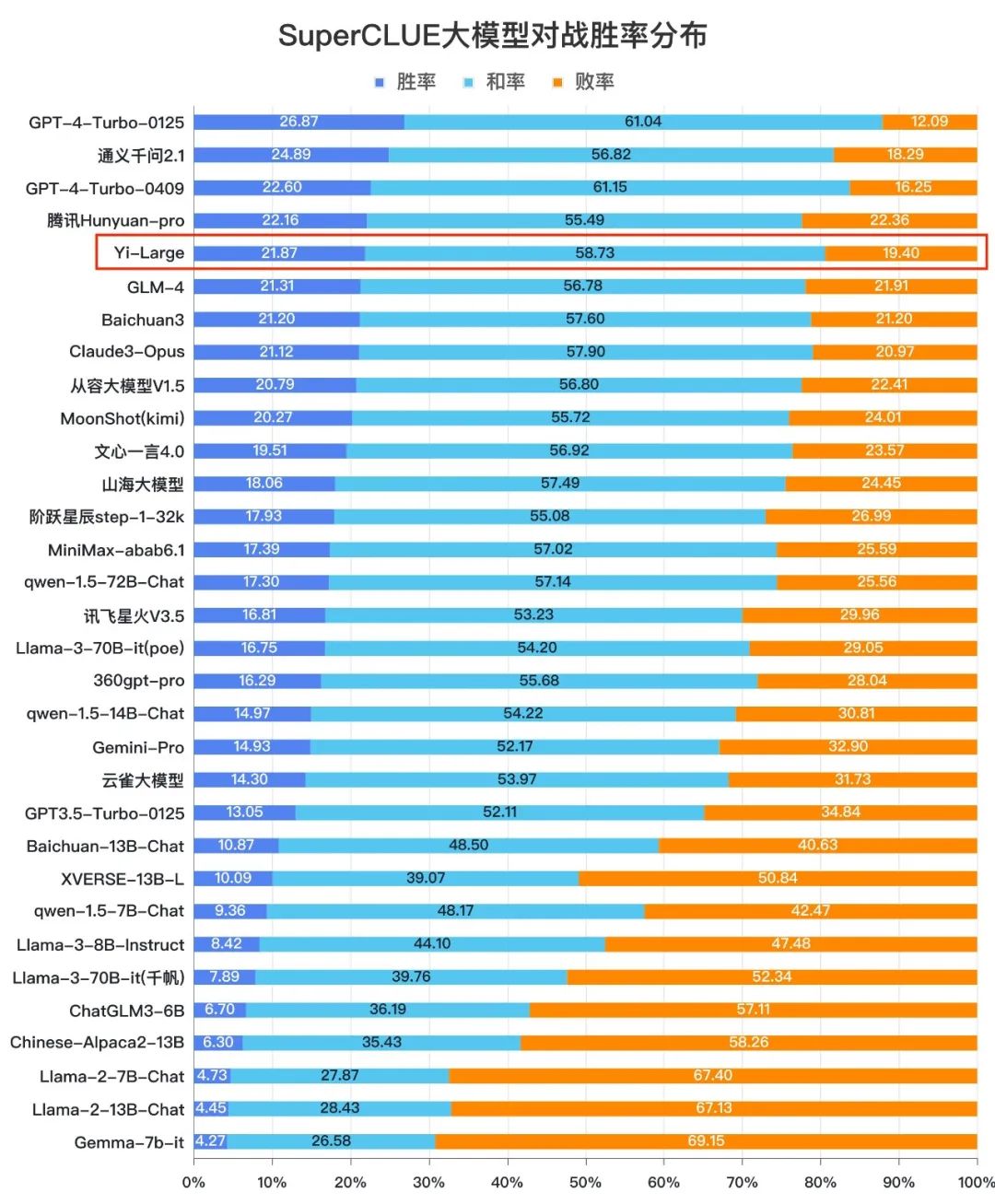
来源:SuperCLUE, 2024年4月30日;模型在每道题上的得分与GPT-4(官网)相比计算差值,得到胜(差值大于0.5分)、平(差值在-0.5~+0.5分之间)、负(差值低于-0.5)。
我们统计了所有大模型在测评中与GPT-4(官网)的对战胜率,可以发现Yi-Large的胜率为21.87%,表现优于Claude3-Opus。
小结 :
从评测结果我们发现,Yi-Large综合能力上表现不俗,在总分上刷新了国内最好成绩,位列国内大模型第一梯队。其中在计算、代码、知识百科及语义理解能力上较为领先,安全能力上还有一定优化空间。
2 定性分析
通过一些典型示例,对比定性分析Yi-Large的特点。
(建议:在电脑端查看获得更好体验)
较好的示例1:计算

较好的示例2:长文本

较好的示例3:知识百科

有优化空间的示例:安全

© 版权声明
文章版权归作者所有,未经允许请勿转载。




