

1. Sora 的工作原理:大脑与视觉处理
Sora 的设计灵感来源于人类大脑处理视觉信息的方式。就像我们的大脑能够理解不同风格和内容的图片一样,Sora 也被赋予了处理多样化视觉数据的能力。它通过特定的算法,将不同来源和风格的图片、视频转换成统一的内部表示形式,从而实现对视觉内容的高效理解和生成。

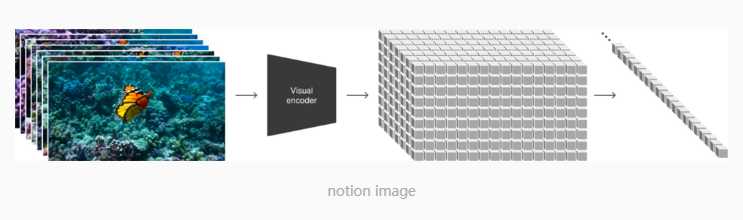
2. 视频压缩网络:标准化视觉数据
Sora 使用视频压缩网络将视觉数据“压缩”成易于处理的低维度表示。这个过程类似于将不同尺寸的照片调整到统一的尺寸,以便模型能够更高效地进行学习和生成。这样的标准化处理不仅便于存储,也为后续的空间时间补丁提取打下了基础。

3. 空间时间补丁:构建视觉内容的基本单元
空间时间补丁是 Sora 处理视觉内容的基本单元。这些补丁将视频内容分解为包含独特景观、颜色和纹理的小块,类似于相册中的照片分解为不同的视觉元素。通过这种方式,Sora 能够捕捉到视频中的每一个细节,并将它们作为生成新内容的基础。
4. 文本条件化的Diffusion模型:从噪声到艺术
Sora 的核心机制之一是文本条件化的Diffusion模型。这个模型的工作原理类似于根据文本提示逐步将随机噪声转化为有意义的视觉内容。Sora 从一个充满随机噪声的视频开始,逐步调整,最终生成与文本描述相匹配的视频或图片。这个过程体现了 Sora 在理解和创造视觉内容方面的灵活性和创造性。
5. 视频生成的关键步骤
Sora 的视频生成过程涉及三个关键步骤:视频压缩、空间时间补丁提取和Transformer模型的应用。这些步骤共同作用,使得 Sora 能够将文本提示转化为具有丰富细节和动态效果的视频内容。视频压缩网络负责将原始视频数据转换为易于处理的形式,空间时间补丁则提供了对视频内容的细致处理能力,而Transformer模型则根据文本提示和补丁内容生成最终的视频。
6. Sora 的技术特点与创新
Sora 在视频生成领域展现了多项技术特点和创新。它支持多种视频格式,能够根据设备原生比例生成内容,提高了内容创作的灵活性。Sora 还改进了视频构图和框架设计,确保主要内容始终处于观众视线中。此外,Sora 能够准确理解文本指令,生成具有丰富细节和情感的角色及场景,以及处理多模态输入,如静态图像或已有视频。
7. Sora 的模拟能力:真实世界互动
Sora 不仅能生成动态视觉效果,还能模拟人物与环境之间的简单互动。它能够生成展现动态摄像机运动的视频,保持人物、物体和场景的一致性,以及模拟如尘土飞扬这样的细节。这些能力使得 Sora 在理解和模拟真实世界动态方面展现出了显著的优势。
8. Sora 的局限性与挑战
尽管 Sora 在视频生成方面取得了显著进步,但它在模拟物理世界的准确性、长时间视频的一致性以及处理复杂文本指令方面仍面临挑战。为了克服这些局限性,Sora 需要更多样化和高质量的训练数据,以及更高效的算法优化。
9. 结语
Sora 作为 OpenAI 的最新视频生成模型,展现了在理解和创造视觉内容方面的潜力。虽然存在挑战,但随着技术的不断发展,Sora 有望在未来实现更广泛的应用,并在视频内容创造和视觉艺术领域开辟新的可能性。
© 版权声明
文章版权归作者所有,未经允许请勿转载。




