








一、动机与功能
在之前,我开源过一个只需要收集10分钟语音素材即可训练的变声器,主打训练素材时长要求低,门槛低。但是,10分钟的语音素材仍然不能覆盖到很多素材比较缺乏的人物。因此,我定下了个小目标,看看能不能把音色克隆10分钟的训练门槛进一步降低到一分钟。其中,隐藏任务有两个,一个是五秒极限克隆,第二个是用A语言训练,支持生成B语言的语音,即heygen的核心技术。
1.1 功能介绍
- 五秒参考音频推理(免训练) :能实现音色像,听感上有比较像的和有那么点不像的。不太像的案例,主要体现在特质、说话方式和口癖,而非音色的说话人上。但还是能达到90%像。
- 文本转语音:少量素材微调一分钟,素材足够微调,得到逼近真人的效果。
- 跨语言的TTS推理: 即训练素材和用来合成语言的文本来自不同语言。
- 变声功能:已经实现了。泛化性,还在测试中,会在下一个视频里进行公布。
二、训练推理教程&现场实操
现场实操的过程如下:
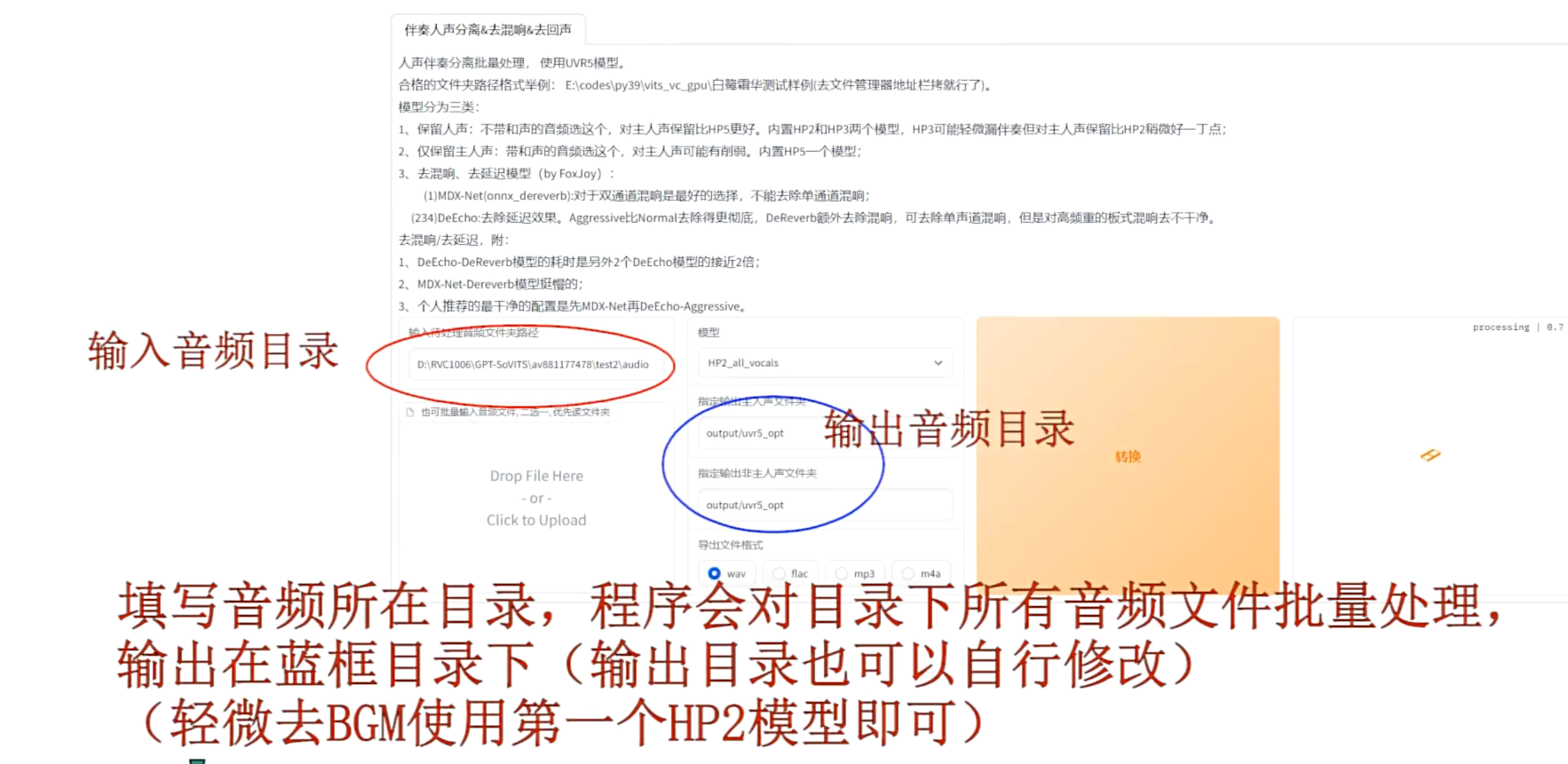
- 打开WEB页面使用伴奏工具:因为原素材有轻微背景音乐,所以需要先把它去除掉。
-
填写音频所在目录:程序会对目录下所有音频文件批量处理输出,在篮筐目录下轻微去除BGM,使用第一个模型即可。

-
把伴奏分离工具的勾去掉,可以释放伴奏分离工具占用的显存。
-
语音切分和语音识别:填写上一步得到的干净人声目录,切换输出目录和要语音识别的音频输入目录,分别做语音切分和语音识别。语音识别的结果默认在output./asr opt.这个目录下能找到
-
开启标注工具进行文本校对:接下来把语音识别的结果1ist文件路径作为标注工具的输入,
开启标注工具,进行文本校对。(会自动弹出WebUI网页)
听不清、语速太快、有杂音的、文本太少的建议删除(勾选Yes点delete)
点submit text或者save files.原地保存修复后的list文件
(也可以看标注工具原作者的教程:BV1My4y1P7WX) -
训练集格式化:得到标注文件后,我们来到第二个tab,先做训练集格式化,填写三个打星号的实验名,干生目录和标注文件路径,然后点击一键三连,等待右下角提示跑完全程。
-
进行两个子模型的微调:可以看到这个目录下出现23456几个路径,然后分别进行两个子模型的微调,顺序随意,也可以同时用不同卡序列参数,不懂的默认就好。
显存没什么要求,6G显存大概率就能玩了
(图里是batch12,1.6G>9.5G)
推荐>=20系(比20系更新架构的)的N卡 -
推理界面:训练完来到推理界面,刷新模型路径,然后可以下拉选择训练完的两个子模型,选完模型后点击开启推理网页界面。
三、效果对比
我们来听一下现场训练的效果。排除获取原始音频外,从拿到素材到得到模型大约8分钟(可以工业化生产)。8分钟定制一个新音色,非常高效。
本次训练素材BV17K4y1z7dV共计2分钟,切分标注完剩73秒,1分钟微调目标达成!
想对比音色相似度的可以回滚25秒听参考音频
通过对比各个竞品的音频,我发现目前各家的效果都是有办法免费体验到的,大家应自己去尝试得出结论,结果最终还将交由后人评说。
四、参考引用致谢
感谢一些开源仓库对他们的贡献,特别感谢赛尔大佬在算法层面的灵魂交流,以及尤里组长在两个月前对我调研语音大模型的帮助。
五、结语
我始终相信先进的技术被研发出来,就是应该去服务于全人类的。整合包的获取方式通过关注阿婆主发送关键词后的自动私信获取,你也可以对视频进行一键三连,来加速本项目的研发进度。
#关键词:#语音变声
© 版权声明
文章版权归作者所有,未经允许请勿转载。




