AnimateDiff for ComfyUI
改进了ComfyUI的AnimateDiff集成,最初改编自sd-webui-animatediff,但此后发生了很大变化。请阅读 AnimateDiff 存储库自述文件,了解有关其核心工作原理的更多信息。
此处显示的示例通常也会使用这些有用的节点集:
ComfyUI_FizzNodes“批处理提示计划”节点的提示旅行功能。
ComfyUI-Advanced-ControlNet,用于批量加载文件并控制哪些潜在因素应受到ControlNet输入的影响(正在进行的工作将包括更多高级工作流程+稍后使用AnimateDiff的功能)。
ComfyUI-VideoHelperSuite用于加载视频,将图像组合成视频,以及执行各种图像/潜在操作,如追加,拆分,复制,选择或计数。
comfyui_controlnet_aux适用于原版ComfyUI中不存在的ControlNet预处理器。注意:如果您以前使用过comfy_controlnet_preprocessors,则需要删除comfy_controlnet_preprocessors以避免两者之间可能存在的兼容性问题。由同人小说16积极维护。
安装
如果使用Comfy Manager:
查找 ,并确保作者是 。安装它。AnimateDiff EvolvedKosinkadink图像
如果手动安装:
将此存储库克隆到文件夹中。custom_nodes
使用方法:
- 本文将介绍如何下载并使用不同运动模块,以及它们在图像生成中产生的不同效果。
-
下载运动模块
- 您可以从以下渠道获取所需的运动模块:
- 原始型号:谷歌云端硬盘、拥抱脸、花旗、百度网盘
- mm_sd_v14
- mm_sd_v15
- mm_sd_v15_v2
- 稳定的mm_sd_v14微调,以及男子气概的拥抱脸:
- mm-Stabilized_mid
- mm-Stabilized_high
- mm_sd_v15_v2的微调,以及男子气概的拥抱脸:
- mm-p_0.5.pth
- mm-p_0.75.pth
- 更高分辨率的微调,由CiaraRowles提供:
- temporaldiff-v1-animatediff
- 将模型放置在指定路径,并可选择重命名:
- 运动 LoRA
- 创意发挥
- 在正常的图像生成中有效的创意也可能适用于 AnimateDiff 生成。以下是一些潜在的高级应用:
- 控制网的堆叠
- 屏蔽控制网的条件反射以仅影响部分动画
- 鼓励尝试不同方法,您将会惊讶于您所能够实现的效果。
- 工作流示例
- 下面是一个示例工作流程:
- 下载所需运动模块并放置于指定路径。
- 如有需要,重命名模型。
- 将运动 LoRA 放入相应路径,并可选择重命名。
- 尝试不同的创意和控制网组合,以达到您想要的效果。
特征:
兼容各种采样器、原版 KSampler 节点和 KSampler(高效)节点。
控制网络支持 – 每帧或帧之间的“插值”;可以将其用作IMG2video(请参阅下面的工作流程)
使用滑动上下文窗口的无限动画长度支持(9/17/23 引入)
实现了来自原始 AnimateDiff 存储库的可混合运动 LoRA。警告:仅适用于基于 v2 的运动模型,如 、 和(9/25/23 引入)mm_sd_v15_v2mm-p_0.5.pthmm-p_0.75.pth
从ComfyUI_FizzNodes使用BatchPromptSchedule节点提示旅行(自9/27/23开始工作)
HotshotXL支持(SDXL运动模块拱形),(自10/05/23开始工作) 注意:您将需要使用beta_schedule,context_length或总帧(不使用上下文时)的最佳点是8帧,并且您需要使用SDXL检查点。当我在处理功能/其他节点之间有一些时间时,将很快添加更多文档和示例工作流。hsxl_temporal_layers.safetensorslinear
即将推出的功能:
备用上下文计划程序和上下文类型(正在进行中)
研究 AnimateDiff 修复或运动遮罩功能
核心节点:
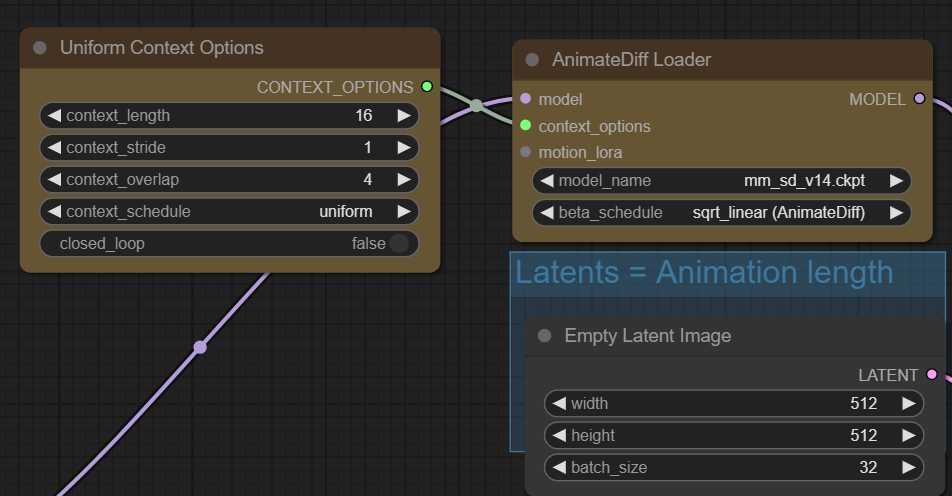
AnimateDiff Loader

作为使用 AnimateDiff 所需的唯一节点,加载器输出一个模型,该模型在传递到采样节点时将执行 AnimateDiff 功能。
输入:
模型:用于 AnimateDiff 使用的模型。必须是 SD1.5 派生的模型。
context_options:采样时使用的可选上下文窗口;如果传入,则动画总长度没有限制。如果未传入,动画长度将限制为 24 或 32 帧,具体取决于运动模型。
motion_lora: 可选运动 LoRA 输入;如果传入,可以影响运动。
model_name:用于 AnimateDiff 的运动模型。
beta_schedule:标清的噪声调度程序。 是使用具有预期饱和度的 AnimateDiff 的预期方法。但是,也可以给出有用的结果,因此请随意尝试。sqrt_linearlinear
输出:
MODEL:注入以执行 AnimateDiff 函数的模型
用法
要使用,只需将模型插入 AnimateDiff 加载器即可。当输出模型(以及此路径中的任何衍生模型)传递到采样节点时,AnimateDiff 将执行其操作。
所需的动画长度由传递到采样器的潜伏物决定。连接context_options后,您可以传入的潜在数量没有限制,即无限动画长度。当没有连接context_options时,最佳点是传入 16 个潜伏以获得最佳结果,根据加载的运动模型,限制为 24 或 32。这些相同的规则适用于统一上下文选项的context_length。
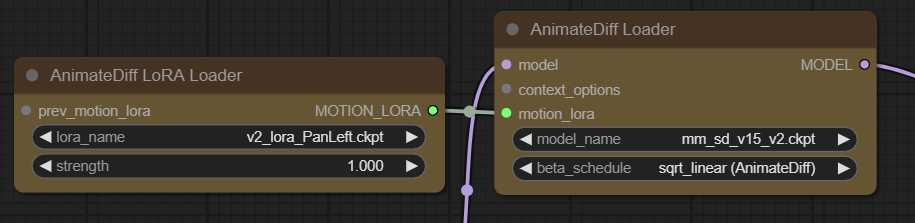
您还可以连接 AnimateDiff LoRA 加载器节点来影响图像中的整体运动 – 目前,仅适用于基于运动 v2 的模型。

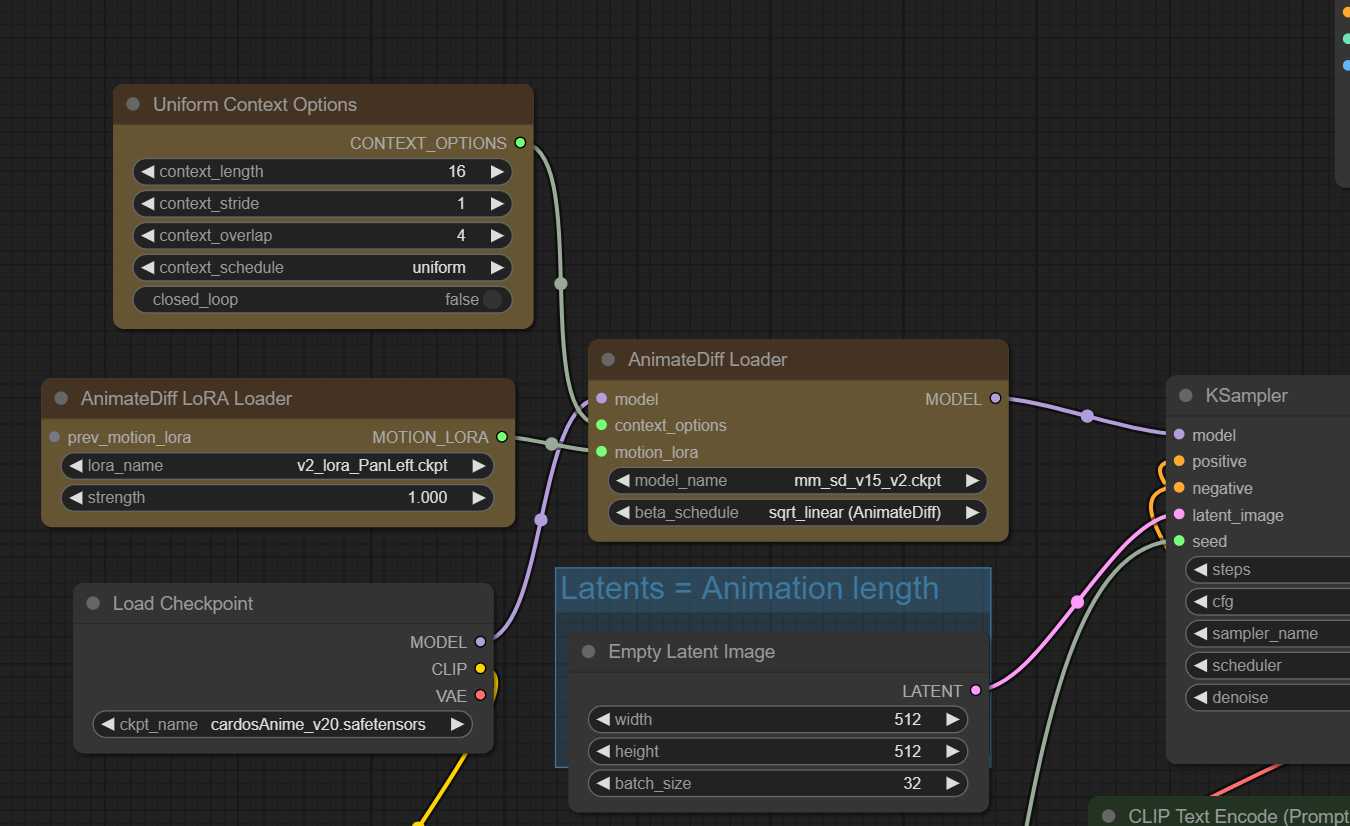
统一上下文选项
待办事项:填写此内容图像
AnimateDiff LoRA Loader
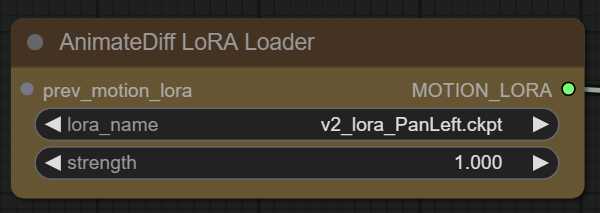
允许将运动 LoRA 插入运动模型.当前运动 LoRA 仅正确支持基于 v2 的运动模型.不影响采样速度,因为值在模型加载后被冻结。如果您在使用 LoRA 时遇到速度变慢, 请打开一个问题,以便我解决它.目前,我知道的基于 v2 的三个模型是 、 和 。mm_sd_v15_v2mm-p_0.5.pthmm-p_0.75.pth
输入:
lora_name:放置在目录中的运动 LoRA 的名称。ComfyUI/custom_node/ComfyUI-AnimateDiff-Evolved/motion-lora
强度: 运动 LoRA 的强 (或弱) 效果应该有多强.值过高可能会导致最终渲染中出现伪影。
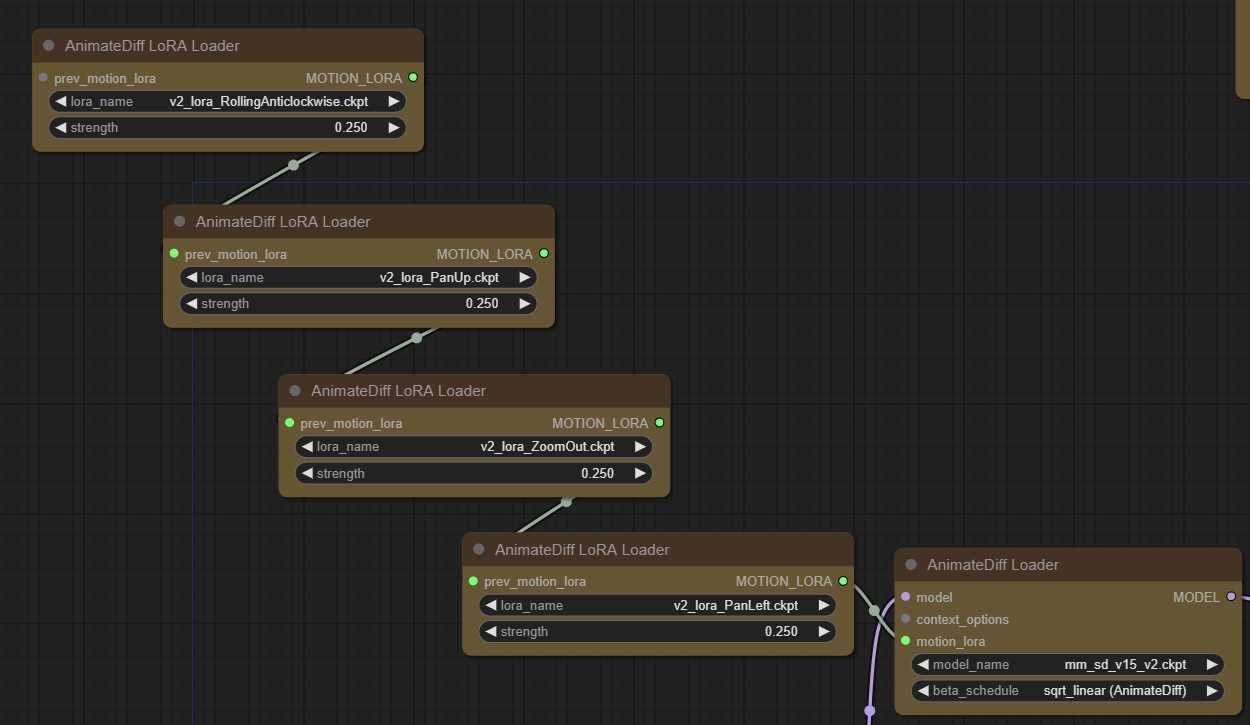
prev_motion_lora: 可选输入允许将 LoRA 堆叠在一起.
输出:
MOTION_LORA:motion_lora存储链接在其后面的所有LoRA名称的对象 – 可以插入另一个AnimateDiff LoRA加载器的背面,或插入AniamateDiff Loader的motion_lora输入。
示例(将工作流的图像下载或拖动到 ComfyUI 中,以立即加载相应的工作流!
TXT2img


TXT2IMG – (快速旅行)
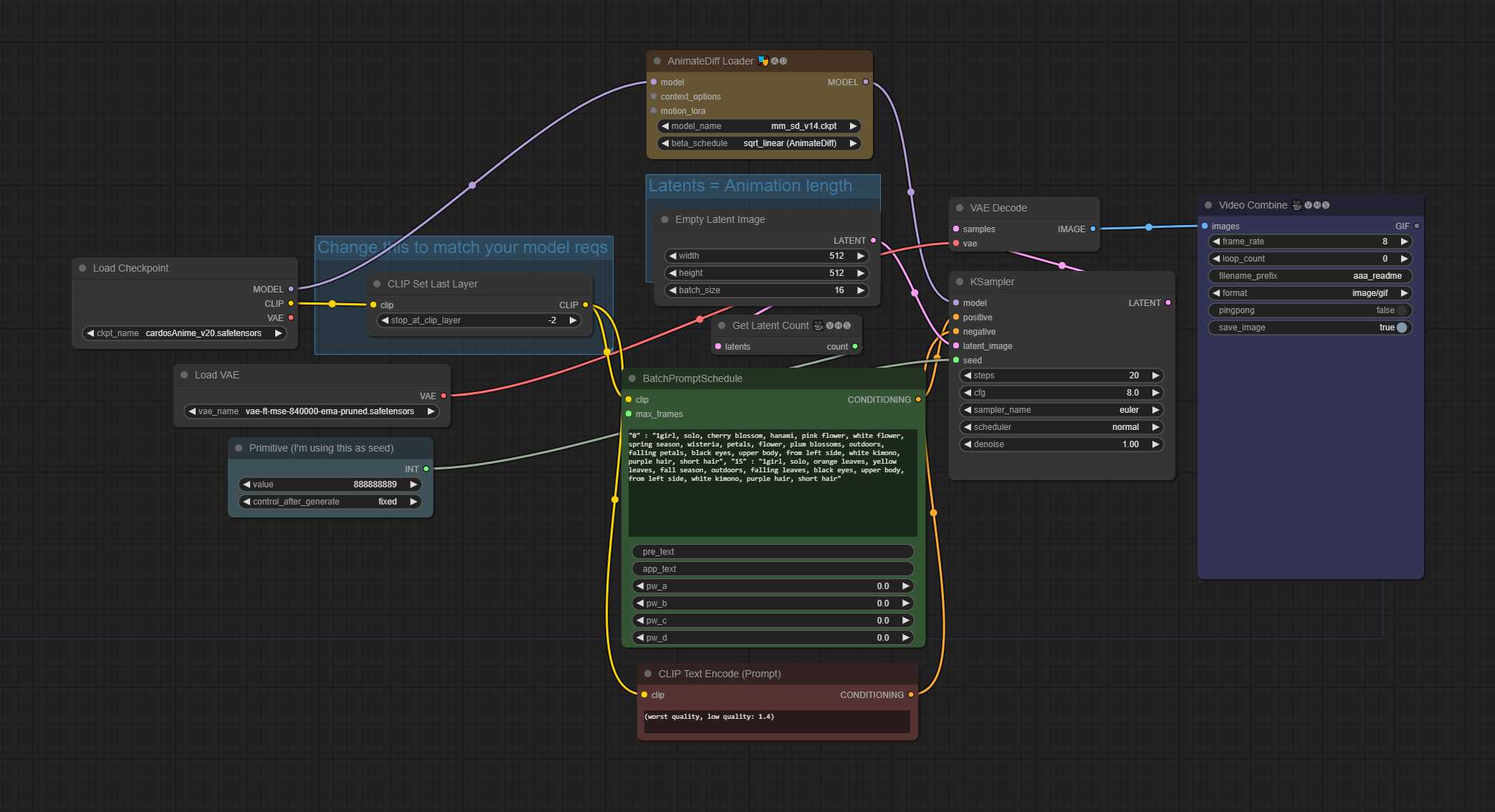

TXT2IMG – 48帧动画,16 context_length(均匀)
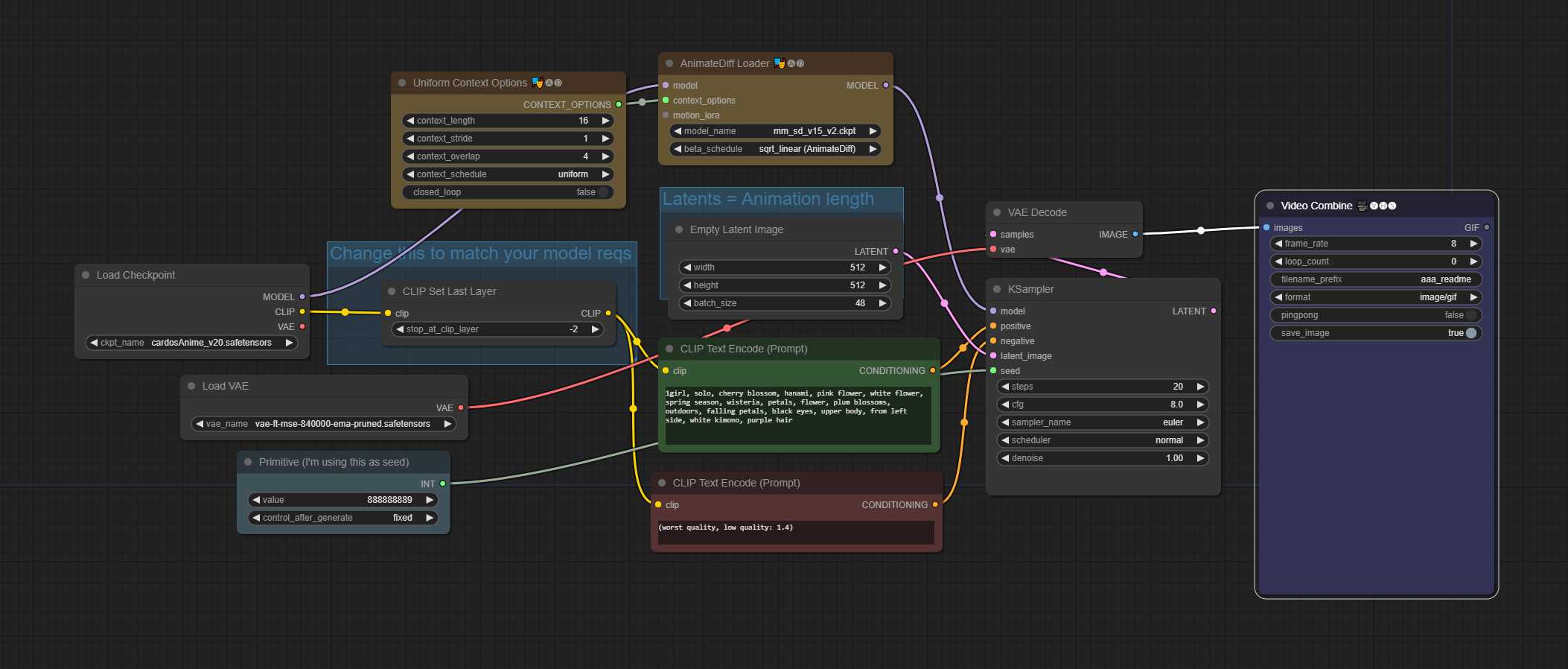

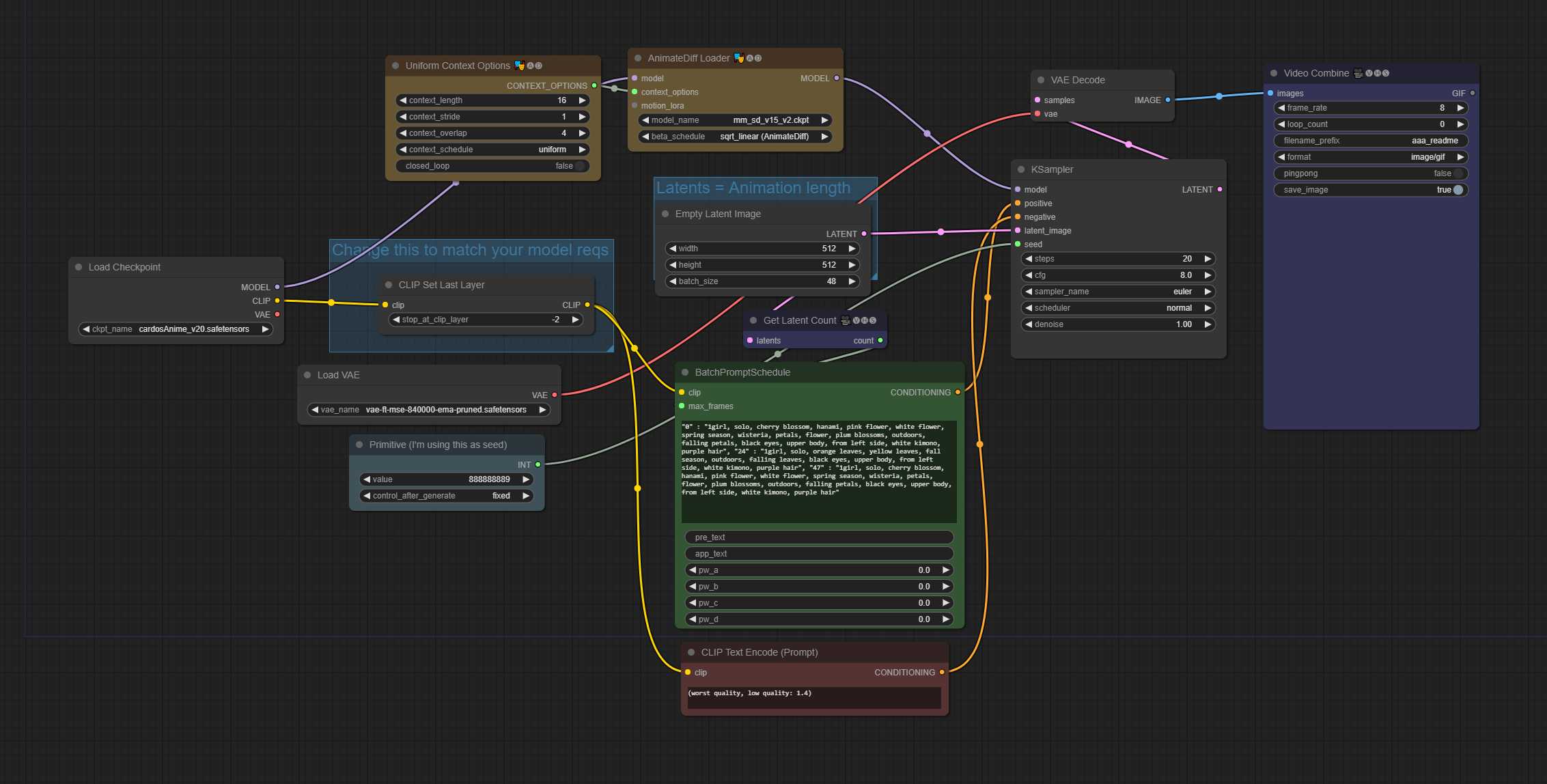
TXT2IMG – (提示行程)48帧动画,16 context_length(统一)

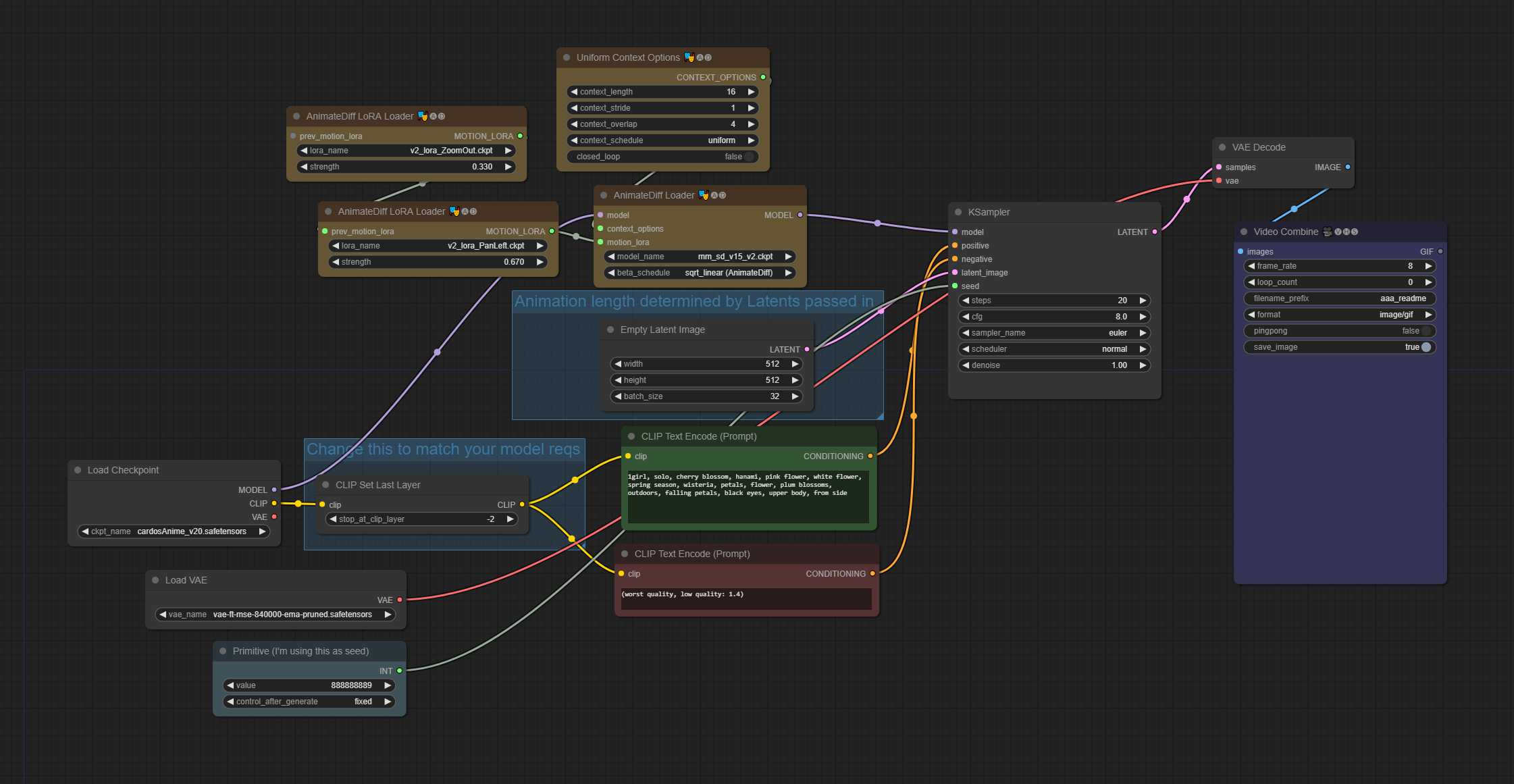
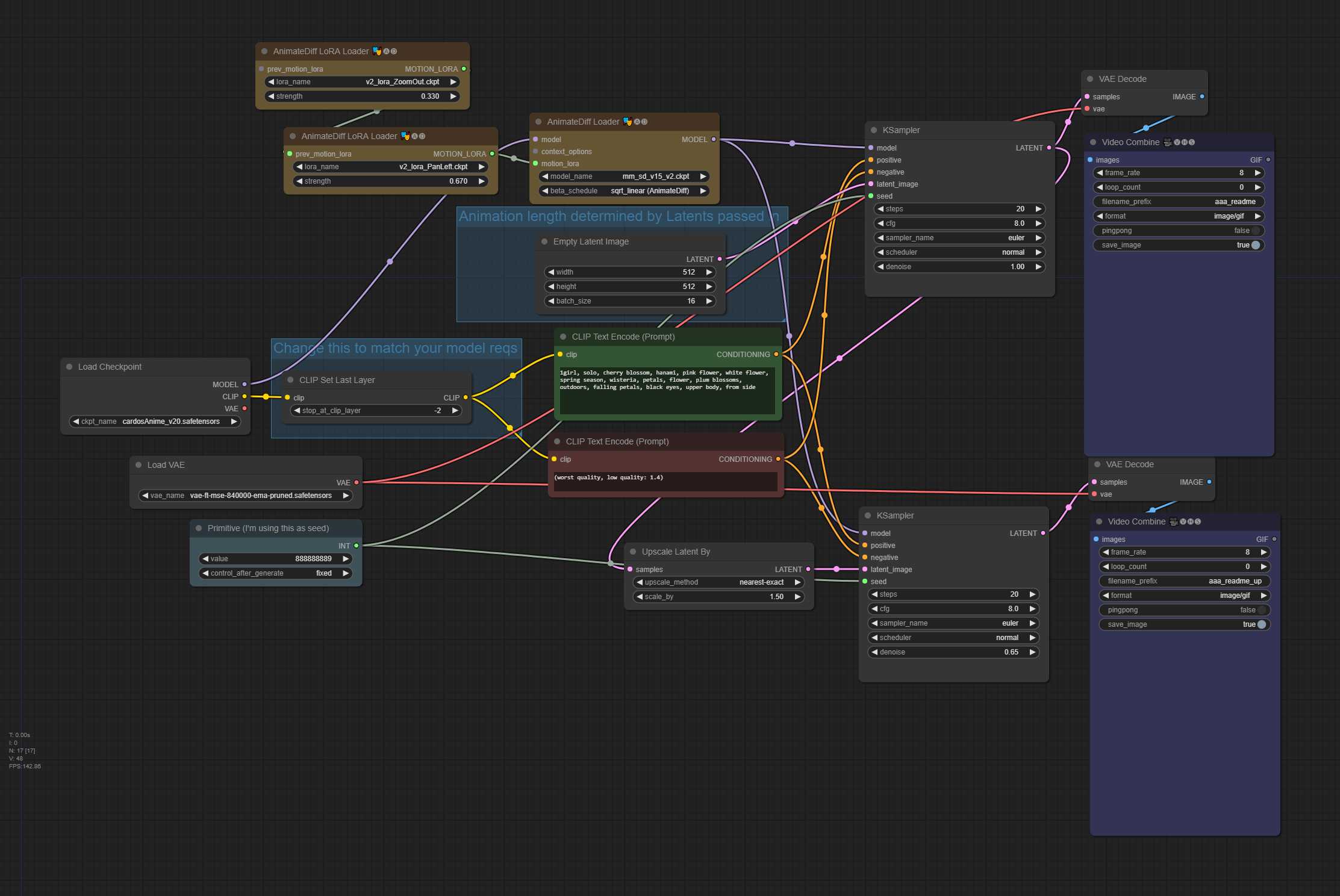
txt2img – 32帧动画,16 context_length(统一) – 平移和缩小运动 LoRA

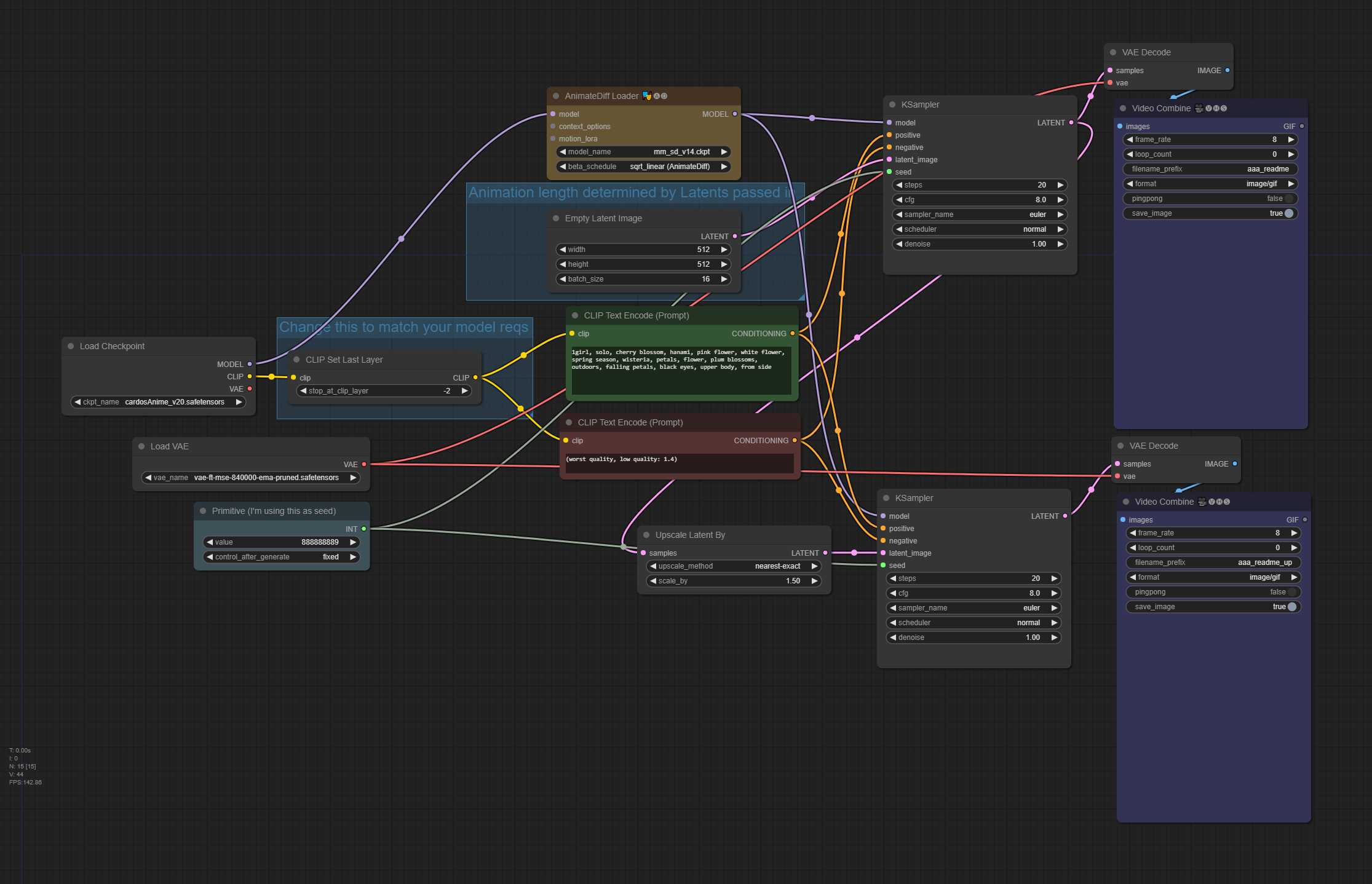
TXT2img 带潜在高档(高档部分降噪)
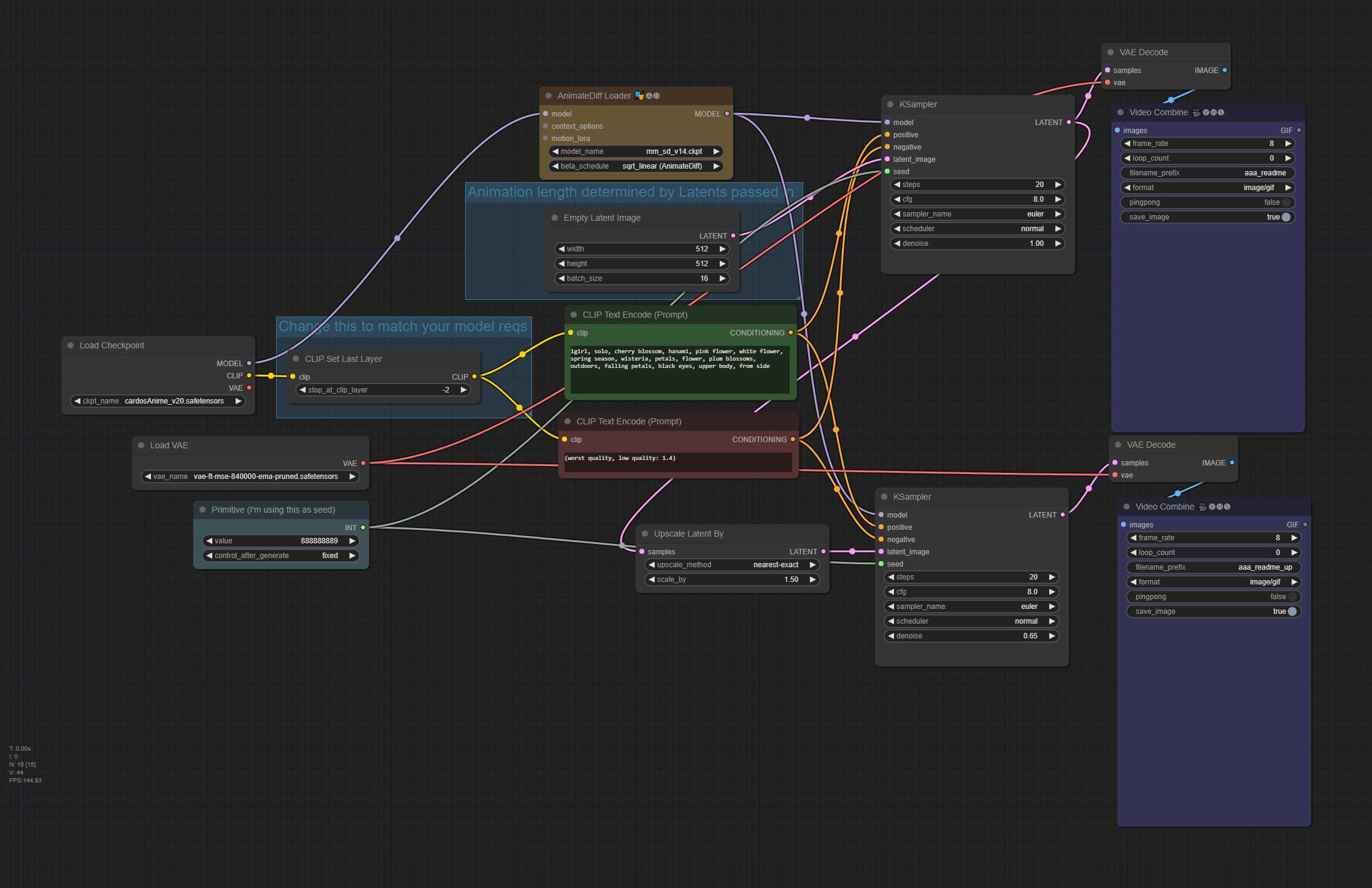

txt2img 带潜在高档 (高档部分降噪) – 平移和缩小运动 LoRA

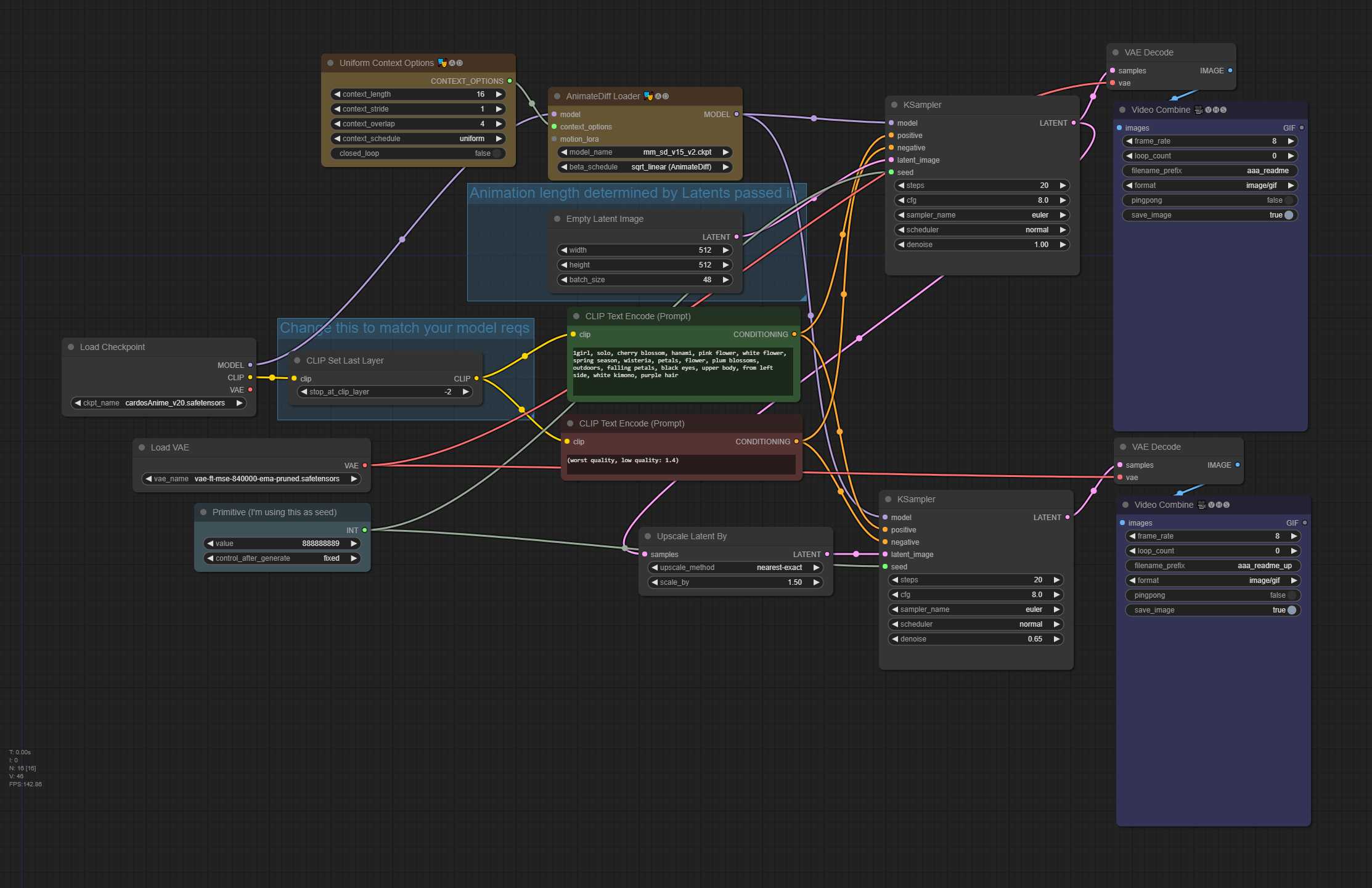
TXT2img 带潜在高档(高档部分降噪)- 48 帧动画,16 context_length(均匀)

TXT2IMG 带潜在高档(高档全降噪)

TXT2IMG 带潜在高档(高档全降噪) – 48 帧动画,16 context_length(均匀)
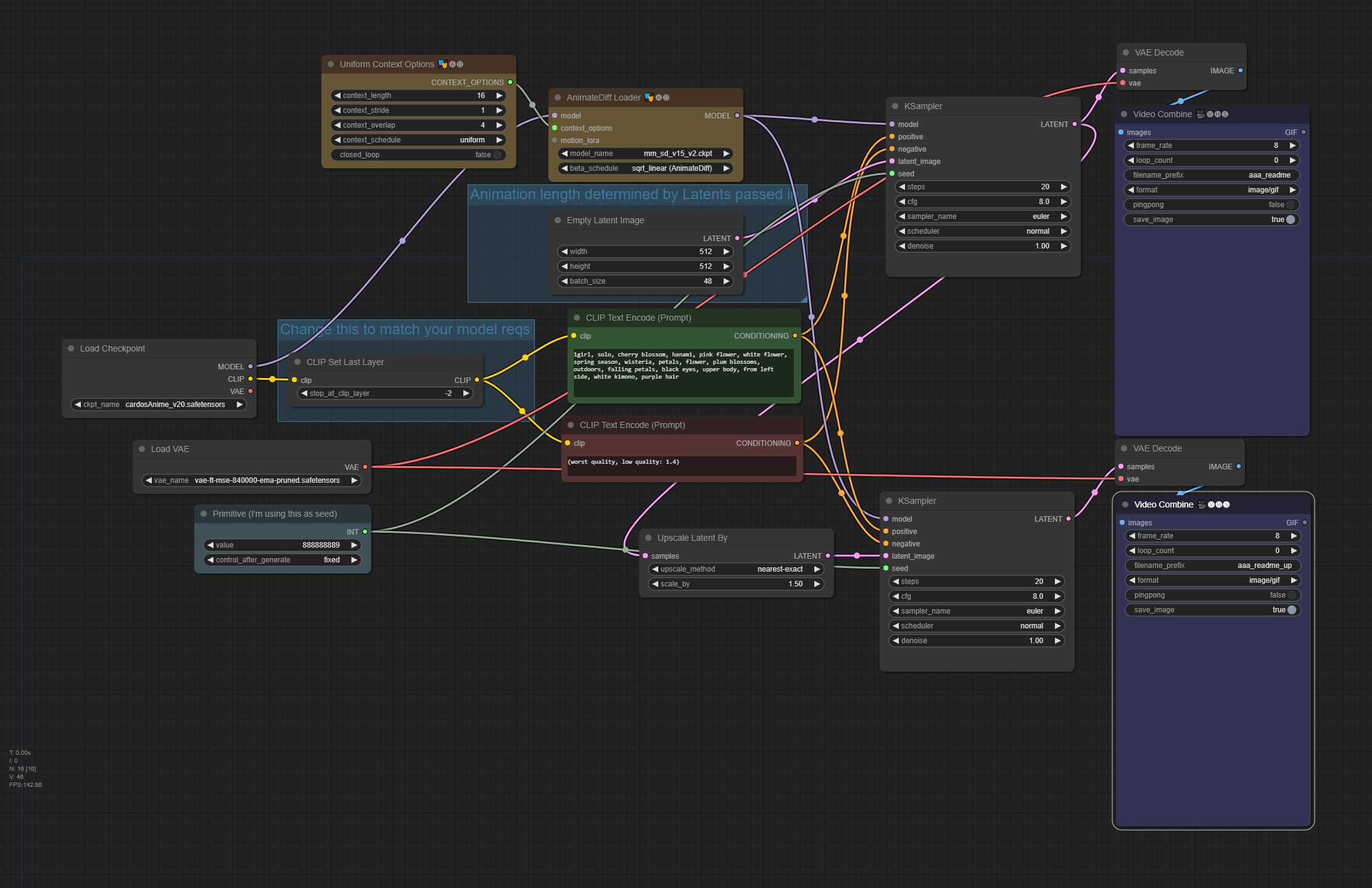

txt2img 带 ControlNet 稳定潜在升级(高档部分降噪,缩放软控制网络权重)
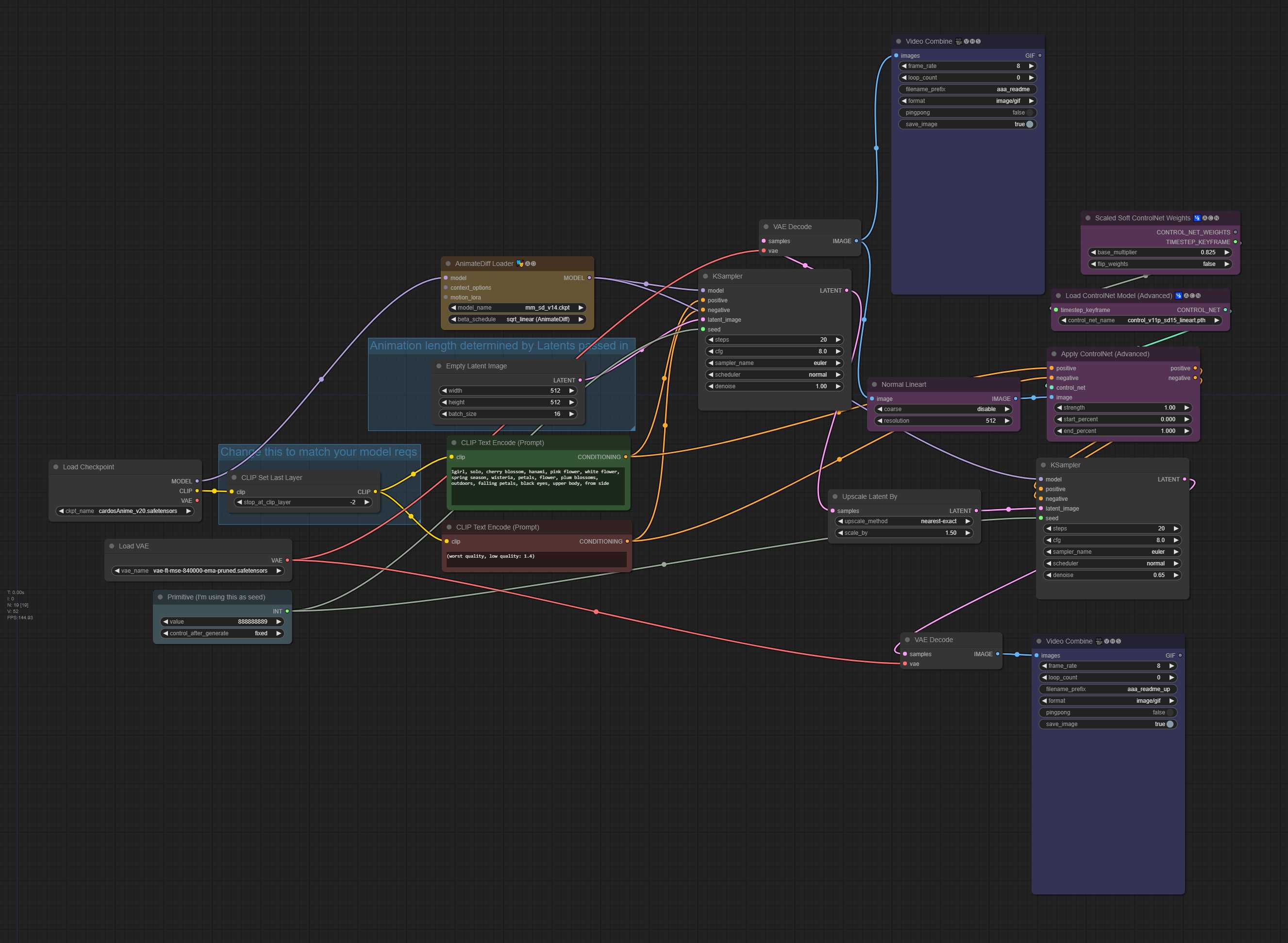

txt2img 带 ControlNet 稳定潜在升频(高档部分降噪,缩放软控制网络权重) 48 帧动画,16 context_length(均匀)


txt2img 带初始 ControlNet 输入(以第一个 txt2img 上的普通艺术线条预处理器为例)
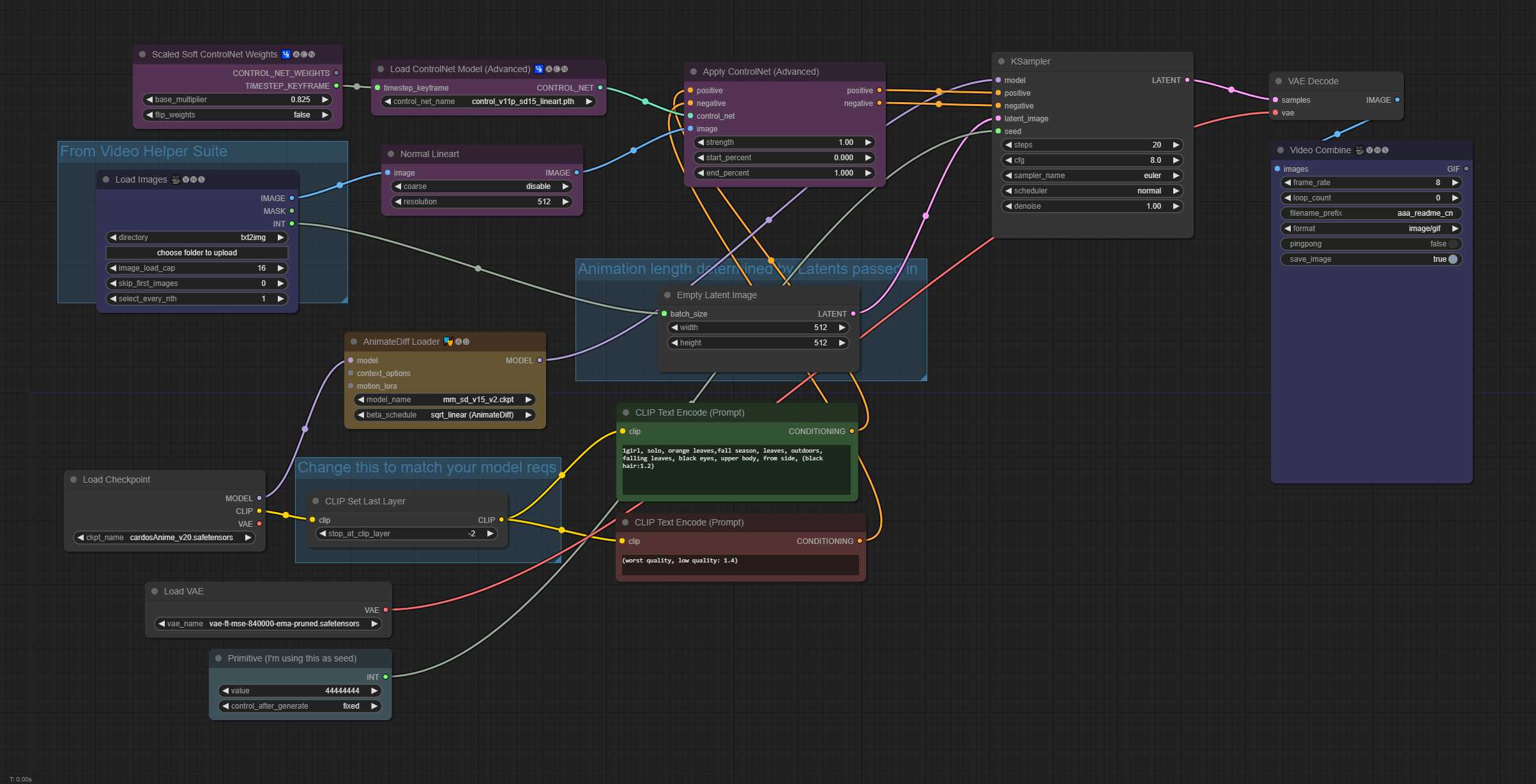

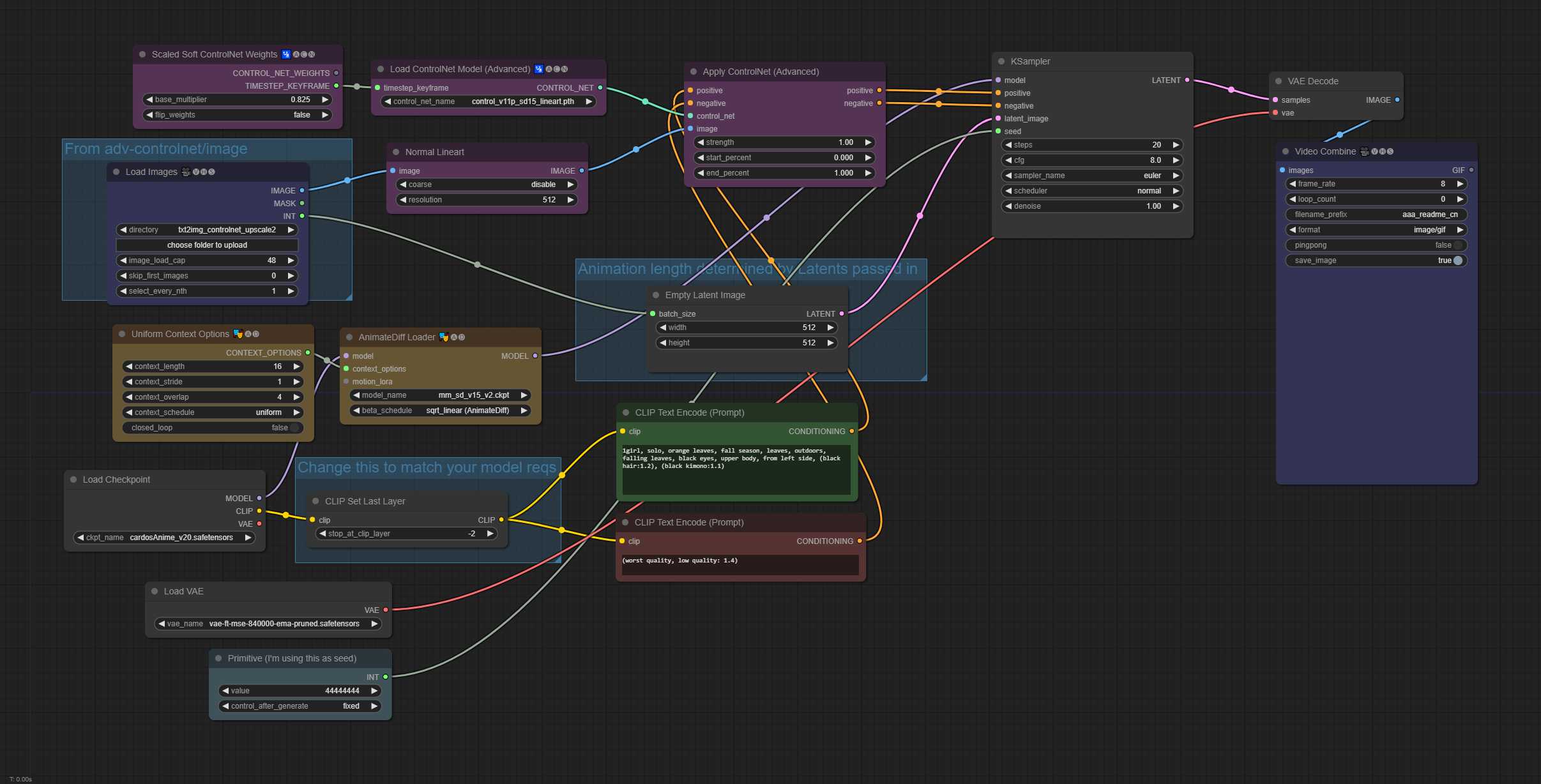
txt2img 带初始 ControlNet 输入(以第一个 txt2img 48 帧上使用普通艺术线预处理器为例) 48 帧动画,16 context_length(统一)

txt2img 带初始控制网络输入(使用 OpenPose 图像)+ 带全降噪的潜在高档
(open_pose图片由Toyxyz提供)
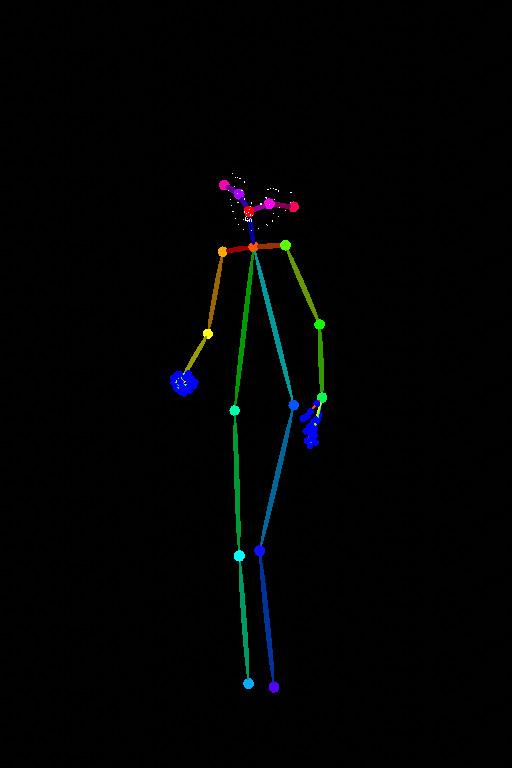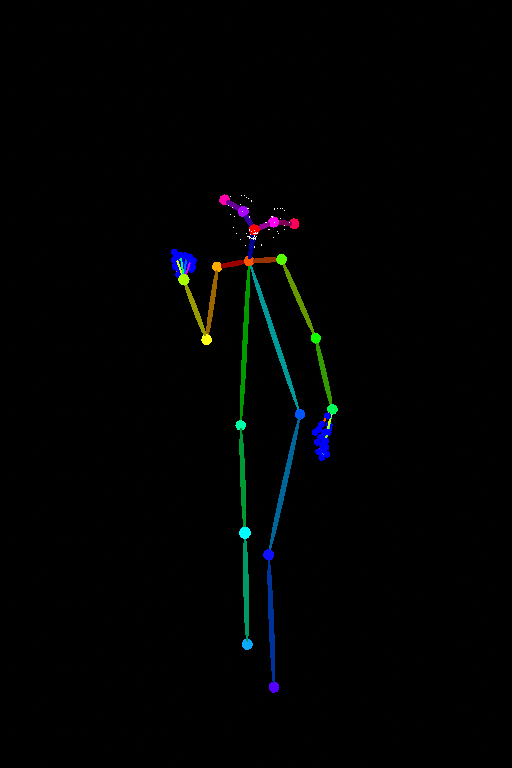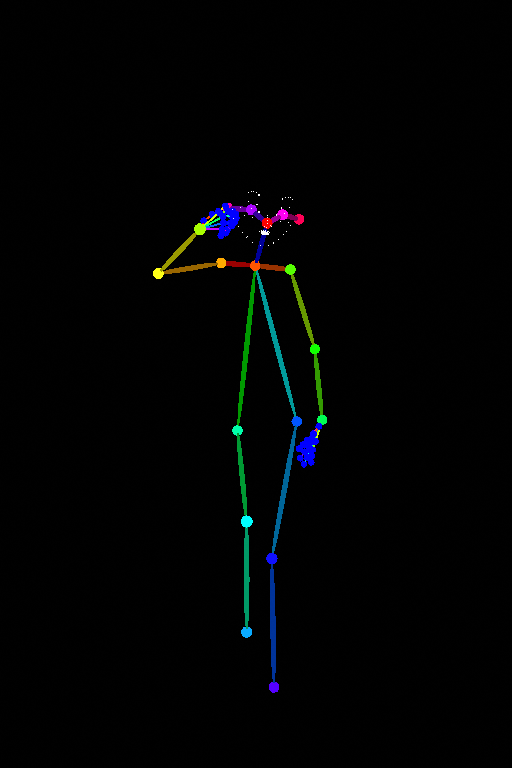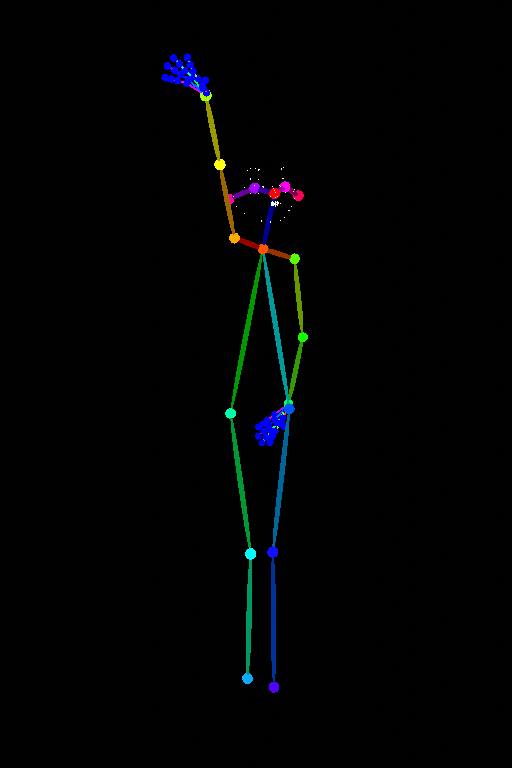

txt2img 带初始控制网络输入(使用 OpenPose 图像)+ 带全降噪的潜在高档,48 帧动画,16 context_length(均匀)
(open_pose图片由Toyxyz提供)

img2img
TODO:用一些有用的方法填写,其中一些使用控制网络磁贴。很抱歉,现在这里什么都没有,我有很多代码要写。我将尝试逐条填写此部分+高级控制网使用。
© 版权声明
文章版权归作者所有,未经允许请勿转载。