



- 首先,准备训练所需的音频文件,格式为WAV格式的单人音频,可以包含背景音乐,建议音频时长半小时以上。压缩包关注:AI掌门堂,回复“VITS”获取。
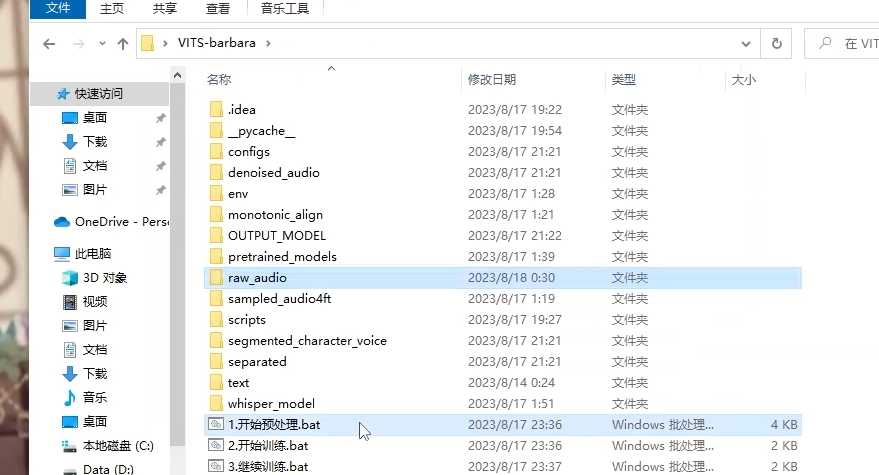
- 将音频文件放入raw_audlo文件夹中,并双击开始处理。

- 按照说明填写参数,系统会自动提取人声并分包。
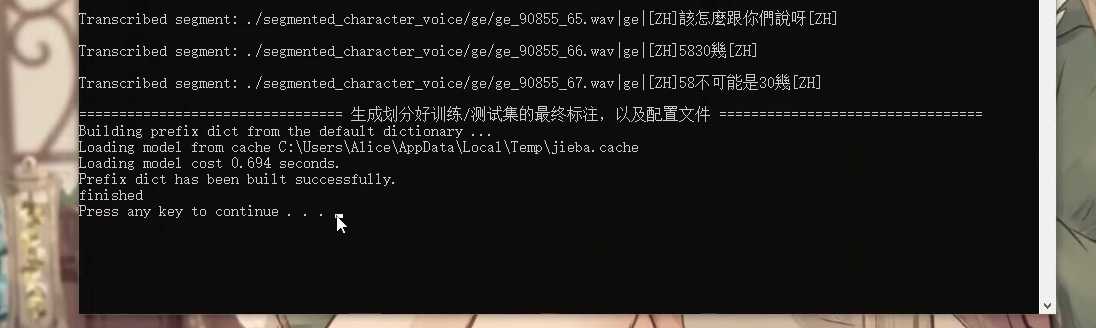
- 标注过程可能会卡顿,因为需要进行语音识别,耐心等待即可。
完成状态
- 训练状态下,双击开始训练,可以根据需要设置参数。
- 训练时可以随时停止,直接关闭即可。
- 训练的语音结果可能不连续,因为深层训练也是一句一句进行的。
- 训练完成后,可以保存效果并继续训练。
- 如果需要中文专项支持,可以查看原仓库中的相关需求。
- 建议给作者一个小星星以表支持。
- 如果需要暂停训练,直接关闭即可,但继续训练时要注意不要点错。
- 开始训练时会清空上一次的模型,如果需要手动备份,可以找到模型文件的位置。
- 可以根据需要对模型进行修改和调整。
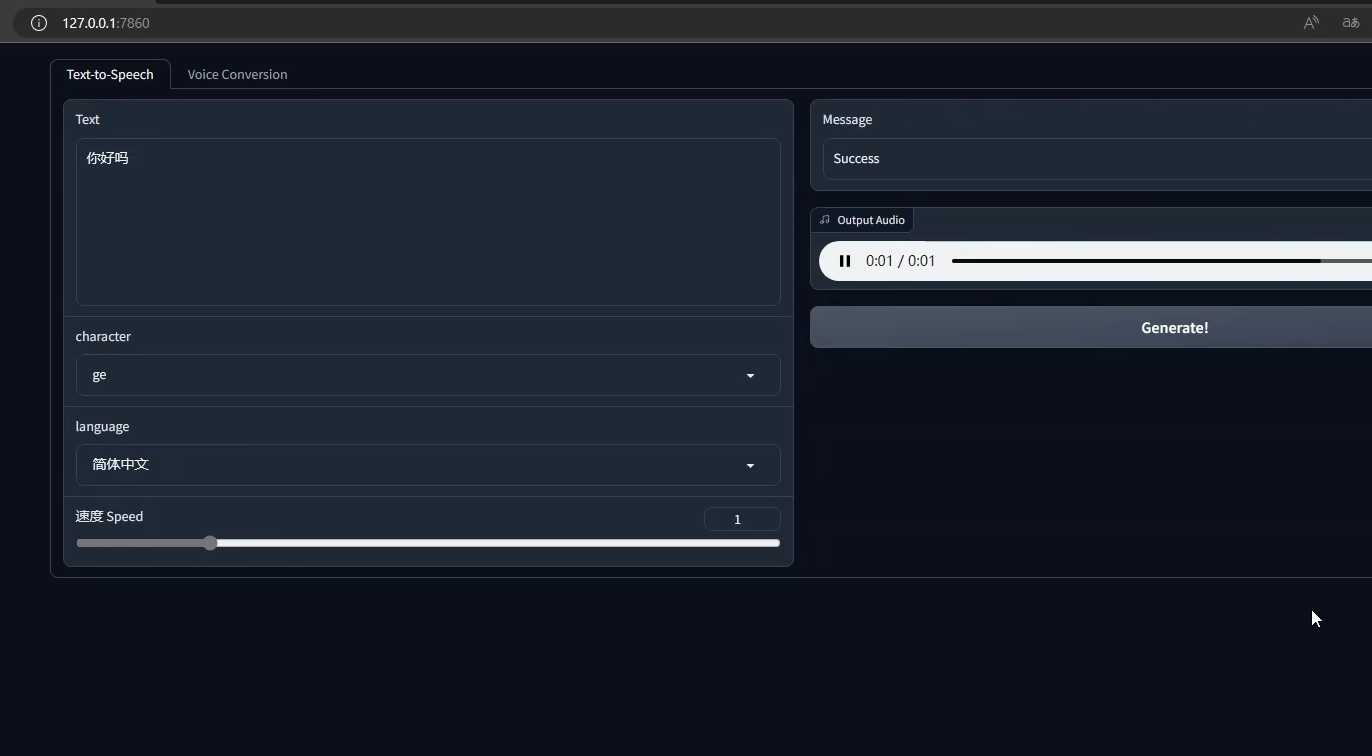
- 训练完成后可以开始生成文字,双击开始,并在网页UI中填入要生成的文字,点击生成即可。
- 下载生成的音频可以点击音频右上角的小箭头。
© 版权声明
文章版权归作者所有,未经允许请勿转载。