
该项目是基于本地知识库的问答应用,利用langchain思想实现。它旨在建立一个对中文场景和开源模型友好、可离线运行的知识库问答解决方案。项目支持使用ChatGLM-6B等大语言模型直接接入,或通过fastchat api接入其他模型。通过加载文件、文本分割、文本向量化、问句向量化等过程,实现与问句最相似的文本匹配,并提交给LLM生成回答。项目还提供了Docker镜像和部署方式,以及Web UI和API的使用示例。
1. LangChain和ChatGL模型具备多种语言能力,包括自我认知、提高写作、文案写作和信息抽取。
2. LangChain框架用于开发语言模型驱动应用程序,提供模型支持、提示词管理、外部数据交互等功能。
3. LangChain主要应用场景包括文档问答、个人助理、数据查询、信息提取和文档总结。
4. 本项目基于本地知识库实现问答功能,可利用提示词进行微调提升效果。
5. ChatGL和LangChain项目支持基于本地文档的问答功能。
6. 这个过程涉及从文档中提取相关信息,并为语言模型创建提示。
7. 实施单文档问答包括五个步骤,包括加载和分割文本,并将其与用户的问题进行匹配。
8. 匹配可以通过字符或语义搜索进行,后者更常用。
9. LangChain的实现涉及下载本地文档,并创建一个用于匹配的向量数据库。
10. 存储在语义向量数据库中。
11. 加载文件成为文本片段。
12. 将文本片段向量化组成向量库。
13. 用户提交问题并在向量库中进行检索。
14. 通过相似性搜索方法返回相关的文档片段。
15. LangChain使用向量数据库实现本地文档问答。
16. 进行向量化并在VectorStore中进行匹配。
17. TopK参数在Similarity Search中设置。
18. Docs存储匹配的文档片段。
19. LangChain能接入不同类型的数据源,包括PDF、TXT和图片等。
20. LangChain的ChatGL项目基于ChatGL等大型语言模型的知识库问答实现。
21. LangChain的实现包括向量化的本地文档问答匹配、加载文件、向量化和文本片段的检索和匹配。
22. LangChain的ChatGL项目可以处理不同的数据源,并优化中文提示和文档阅读。
23. Chains文件夹定义了处理不同数据类型(包括文档、表格和知识图谱)的工作流程和不同类型的Chain。
24. Content文件夹存储用于准确信息匹配的原始文件。
25. VectorStore文件夹使用Face存储方法存储有限的库文件。
26. Config文件夹存储各种配置信息。
27. LangChain的实现包括用于处理不同数据源和优化中文提示的各种文件夹。
28. 该项目可以进行文本片段的匹配、加载、向量化和检索以及向量搜索。
29. 上下文信息可以合并在一起,形成更完整的语义段落。
30. “center size”的默认值约为100个字符。
31. 前k个搜索结果经过排序和去重处理。
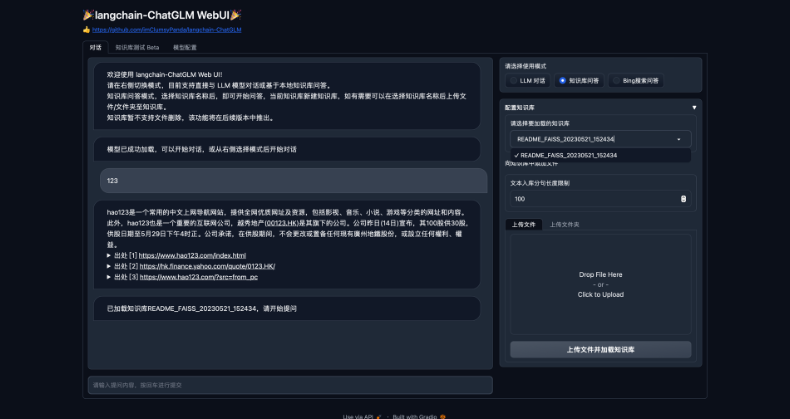
32. Web UI界面包括LLM对话、知识库测试和模型配置的选项。
33. 项目使用的默认的embedding模型是text-to-web的large-中文模型。
34. 可以通过微调自然源模型或embedding模型来提高本地知识库问答的效果。
35. 在文档加工方面,可以利用语义识别的模型进行文段划分,并根据上下文关联程度来选择加入的问题。
36. 另一种文档加工方式是利用语言模型对每个段落进行总结,并进行向量化。
37. 可以利用代码生成模型来更有效地进行text to cipher或者text to circle的操作。
38. ChatGL项目计划扩充不同类型的数据,完善知识库的功能,并支持更多的类型相关库。
39. 可以在本地知识库问答优化中使用模型微调、文档处理和整合不同数据类型。
40. LangChain ChatGLMI项目中计划进行的开发包括应用升级、优化和其他功能开发。
41. LangChain项目的团队成员包括前端工程师、博士和工程师,在后端开发和跨平台应用方面有着专业的贡献。
42. 在本地知识库问答中,出处内容要作为填充内容添加到prompt模板中,才能得到最终答案。
43. 图像识别是通过OCR进行文本转化的,目前暂不支持表格识别,但会在未来进行测试和升级。
44. 可以优化本地知识库问答。
45. LangChain项目团队在前端工程、容器化和语言建模方面拥有专业知识。
46. LangChain讨论了提示模板和上下文长度的处理。
47. LangChain支持使用OpenAI的API模型和使用OCR进行图像识别。
48. 面部向量库可以在本地保存,并使用”faceadd document”功能进行添加。
49. LangChain团队计划将Bing搜索和本地知识库纳入问答系统中。
50. 优化文本相关性的方法。
51. 使用固定模板回答无相关文本的问题。
52. 文件中表格内容可通过结构解析和库表数据解析进行支持。
53. 可考虑加入Pinecone项链库。
54. LangChain提供多种Score计算方式。
55. 扩充方向包括数据源、库的管理、文本画面方式和Agent的应用等。
56. 文本关键词提取可以用于优化文本相关性匹配。
57. 支持使用固定模板回答没有相关文本的问题。
58. 通过结构和数据解析支持文件表格内容。
59. 可以使用Pinecone和不同的Score计算方法。
60. 可以使用消息队列和分配器实现并发处理,以支持更多的问答用户。
61. LangChain支持将知识图谱转换成向量的方式进行查询匹配。
62. 通过限制返回数量来优化文字相关性。
63. 有通用定义模板用于未知问题的回答。
64. 可以支持结构化表格内容。
65. 表格内容可以转换为JSON格式。
66. 图片中的文字可以通过OCR识别。
67. Pad OCR需要在线下载模型和执行过识别后才能进行离线使用。
68. LangChain团队计划将Bing搜索和本地知识库纳入问答系统中。
69. 优化文本相关性的方法。
70. 使用固定模板回答无相关文本的问题。
© 版权声明
文章版权归作者所有,未经允许请勿转载。




